블록체인 데이터를 다루는 생태계는 프로세스 측면에서 세가지 주체로 구분할 수 있다. 원시 데이터 소스, 데이터 탐색 및 추출을 위한 인프라와 도구를 제공하는 코디네이터, 데이터에 접근하는 사용자로 나눌 수 있다. KYVE 블록체인은 이 생태계에서 데이터 코디네이터 역할을 한다. 블록체인 데이터로 구성된 데이터 소스에 대해 사용자가 쉽게 접근할 수 있는 인프라를 운영한다.
실제로 이 인프라는 이전 아티클 ”블록체인의 문제를 해결하는 블록체인, KYVE”에서 살펴 봤듯이 KYVE L1 블록체인을 통해 구축하였다. 이 데이터 생태계 분석 글에서는 이러한 구성 요소를 기반으로 앞으로의 향방에 대해 살펴보자.
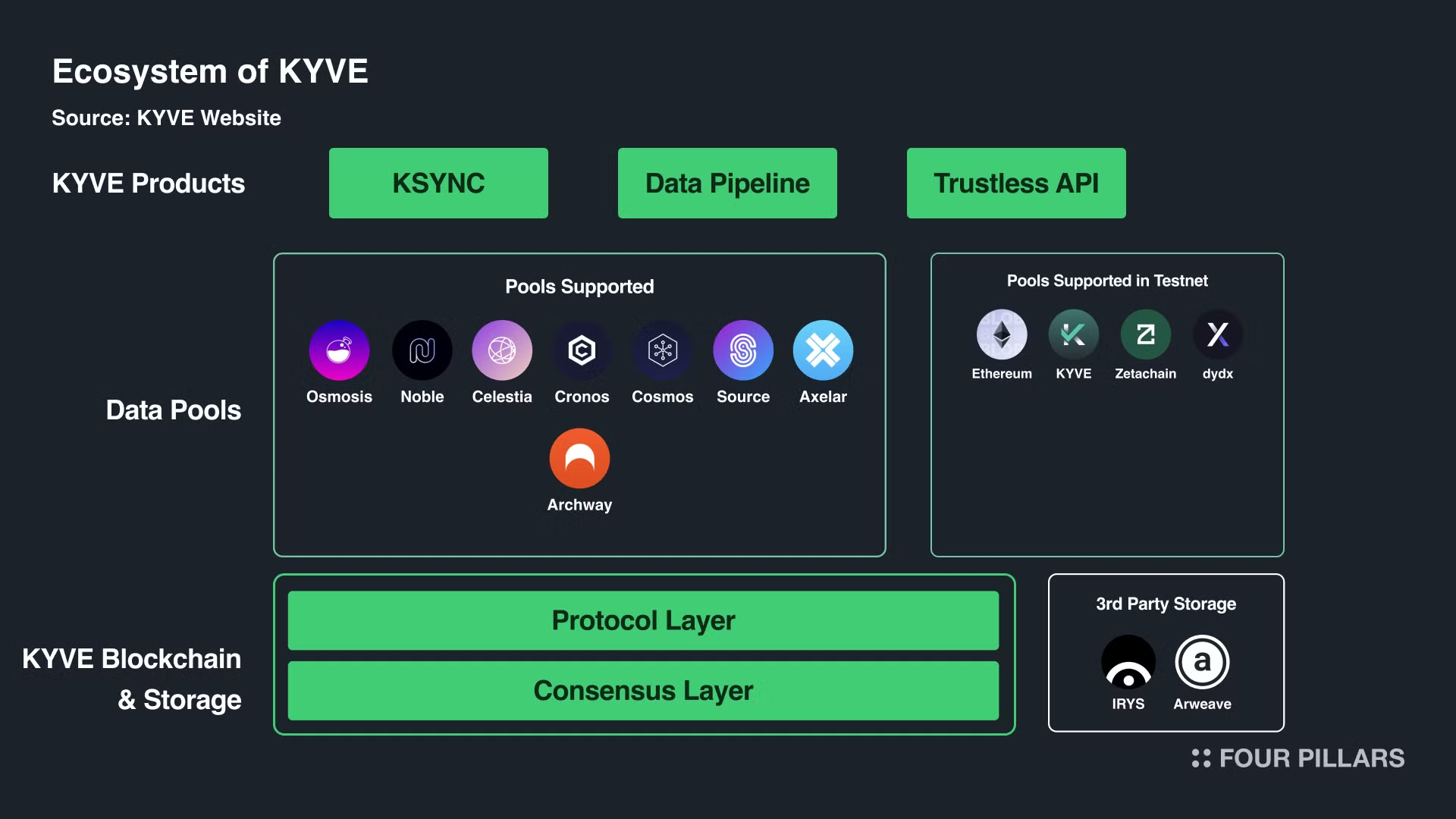
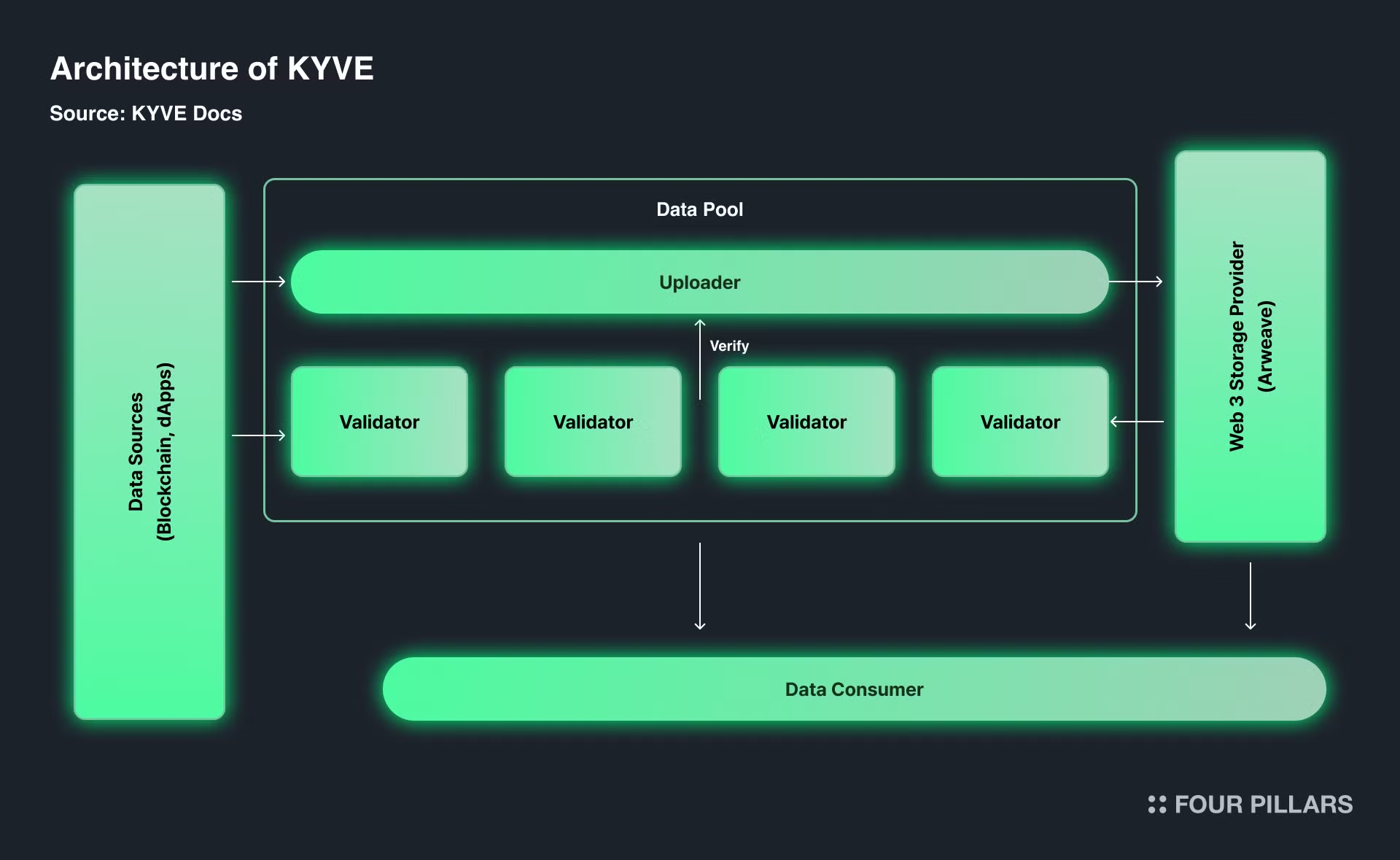
KYVE 데이터 생태계의 데이터 소스는 주로 블록체인 데이터 그 자체를 의미한다. 블록체인의 과거 데이터들을 포함하며 Tx 리스트, 컨트랙트 데이터 등이 포함된다. 이러한 데이터 소스를 더 접근하기 쉽게 KYVE만의 인프라를 통해 데이터 풀이라는 형태로 저장하며 이를 프로토콜 벨리데이터들이 검증한다. 이러한 벨리데이터들은 각 블록체인 데이터를 수집하고, 이를 번들링하여 분산형 스토리지 솔루션에 업로드하는 역할을 담당한다.
KYVE는 이러한 데이터 소스와 데이터 스토리지 솔루션 사이의 가교 역할을 하며, KYVE의 프로덕트들을 통해 데이터 검증 및 아카이빙을 가능하게 한다. 이에 대해 더 자세히 알아보자.
KYVE 블록체인은 다른 블록체인 데이터를 탈중앙화된 아카이빙과 캐싱을 제공하여 데이터 스토리지를 코디네이션하는 데 필수적이다. KYVE의 시스템은 데이터를 탈중앙화된 스토리지 플랫폼에 백업되는 “번들”로 변환한다. Irys 및 Arweave와 같은 타사 솔루션을 사용해 데이터를 영구적으로 저장하여 필요할 때마다 액세스할 수 있도록 한다. 이를 통해 데이터 영속성을 보장하고 여러 블록체인에 대한 데이터 접근성을 높인다. 주요 구성 요소는 다음과 같다.
KYVE L1 블록체인
KYVE 데이터 풀에 접근하게 해주는 3가지 프로덕트
데이터가 저장되는 타사 스토리지
1.2.1 KYVE 블록체인 - 핵심 코디네이션 인프라
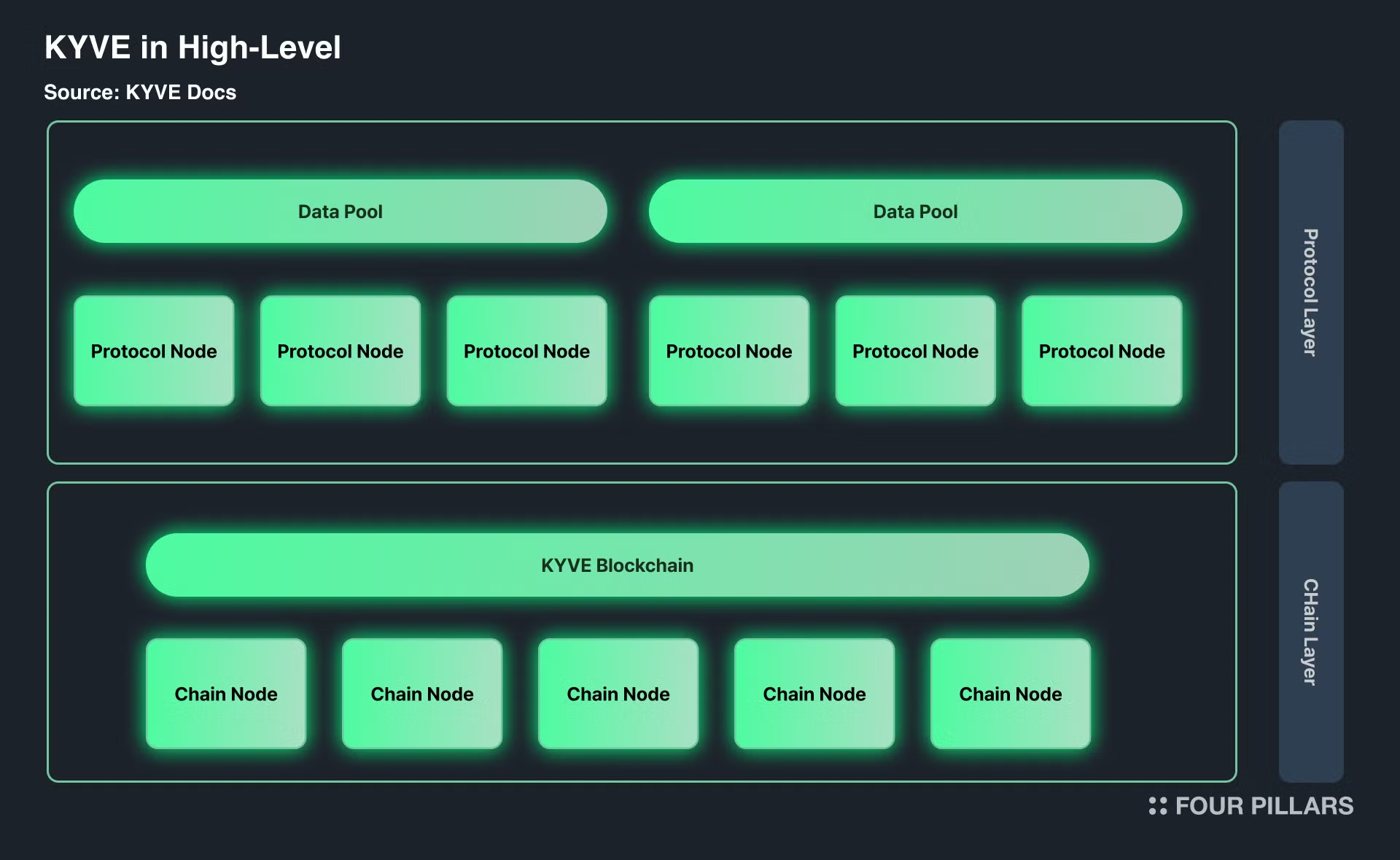
KYVE의 인프라는 코스모스 SDK와 함께 L1으로 구축되어 데이터 스토리지 코디네이션을 위해 구축되었다. KYVE는 탈중앙화된 스토리지 공급자에 데이터 스트림을 검증하고 저장하는 역할을 한다. KYVE는 데이터가 최종적으로 저장되는 데이터 풀 네트워크와 함께 지분 증명 블록체인을 사용한다.
KYVE에 저장된 데이터는 특정 데이터 소스에 초점을 맞춘 엔티티인 데이터 풀에 의해 관리된다. 누구나 거버넌스를 통해 데이터 풀을 생성하고 모든 데이터 스트림을 저장할 수 있다. 데이터 풀은 온체인으로 운영되므로 완전히 신뢰할 필요가 없다. 이러한 풀은 데이터를 검증하고 보관하며, 참여자(프로토콜 검증자 운영자)가 온체인에서 검증 프로세스에 참여하고 관리할 수 있도록 한다.
Source: High-level Overview | KYVE
1.2.2 세 가지 프로덕트 - KYVE 데이터 풀에 액세스하는 툴
이러한 데이터 풀에서 데이터 검색을 간소화하는 세 가지 프로덕트가 있다:
KSYNC: 이 프로덕트를 사용하면 KYVE 데이터 풀에 기록된 블록체인의 블록과 상태 동기화 스냅샷을 통해 노드 싱크를 진행할 수 있다. 구체적으로 KSYNC는 체인 동기화를 위해 세 가지 주요 기능을 제공한다: 첫째로 블록 동기화를 통해 노드는 제네시스 블록에서 현재 라이브 높이로 동기화할 수 있으며, 이는 과거 블록이 점점 접근하는데 희소해짐에 따라 불편함을 겪는 아카이브 노드 러너에게 필수적인 기능이다. 둘째로 상태 동기화는 특정 간격으로 제네시스에서 실시간 높이까지 동기화할 수 있어 중앙화된 공급자가 필요했던 이전의 한계를 극복할 수 있다. 마지막으로 높이 동기화는 블록과 상태 동기화를 결합하여 생성부터 라이브까지 모든 블록 높이에 빠르게 접근할 수 있으며, 이전에는 상당한 노력과 리소스가 필요했던 프로세스이다.
Trustless API: 사용자는 Trustless API를 사용하여 자신의 애플리케이션과 검증된 데이터에 연결할 수 있다. 이는 페이월 없이 원활하게 액세스할 수 있는 KYVE 재단에서 구축한 공공재이다.
데이터 파이프라인: 사용자는 블록체인에서 검증된 KYVE 데이터를 빅쿼리, 포스트그레스 등 사용자가 선호하는 데이터베이스에 동기화하고 로드할 수 있다. 또한 CLI 도구 등으로 실시간으로 효율적으로 업데이트 할 수 있다.

1.2.3 타사 스토리지 - 블록체인 데이터의 영구 저장
KYVE 블록체인은 Arweave와 같은 타사 스토리지 솔루션을 사용하여 데이터를 영구적으로 저장한다. 이러한 탈중앙화된 스토리지는 데이터를 항상 사용할 수 있도록 보장하며, 이는 분석 및 앱 개발을 위해 완전한 과거 기록을 유지하는 데 매우 중요하다.
KYVE는 Arweave와 같은 플랫폼에 데이터를 저장하는 이유는 대량의 데이터를 블록체인에 직접 보관하는 것은 비용이 많이 들고 비효율적이기 때문이다. 이를 통해 벨리데이텅화 사용자의 운영 및 사용 비용을 절감할 수 있게 된다. 구체적으로, KYVE는 번들을 생성하여 Arweave에 저장함으로써 데이터를 간소화하여 데이터에 쉽게 액세스하고 데이터 정확성을 지속적으로 검증할 수 있도록 한다. 이 프로세스는 처리해야 하는 데이터의 양을 줄여 새로운 검증자가 네트워크에 참여할 수 있도록 도와준다.
KYVE 블록체인 데이터 생태계는 주로 노드 운영자, 디앱 개발자, 데이터 분석가를 포함한 데이터 검색자를 지원한다. 이러한 사용자들은 KYVE 네트워크에 저장되고 검증된 데이터에 액세스하고 이를 활용한다.
특히 노드 운영자는 과거 블록체인 데이터의 원활한 동기화 및 검색에 액세스해야 하기 때문에 더욱 중요하다. 노드 운영자가 주로 사용하는 제품은 KSYNC로, 노드 운영자는 노드를 체인의 모든 과거 블록, 상태 또는 높이와 빠르게 동기화하여 효율적이고 안정적인 데이터 검색을 보장할 수 있다.
개발자와 데이터 분석가도 KYVE의 데이터 검색 기능의 이점을 누릴 수 있다. KYVE는 Trustless API를 제공하여 개발자가 애플리케이션을 KYVE의 검증된 기록 데이터에 빠르고 안전하게 연결할 수 있도록 지원한다. 이 API는 KYVE의 데이터를 다양한 분석 플랫폼에 쉽게 통합할 수 있도록 지원하므로 데이터 분석가는 복잡한 데이터 소싱 프로세스 없이도 포괄적인 분석을 수행할 수 있다.
KYVE는 유사한 아키텍처를 가진 직접적인 경쟁자는 없지만, 두 개의 주요 경쟁 주체가 있다.
Alchemy와 DSRV의 allthatnode와 같은 중앙 집중식 제공업체는 기록 데이터 저장 및 액세스를 포함한 인프라 서비스를 제공한다. 이러한 중앙 집중식 서비스는 다양한 프로덕트 라인을 제공하는 경우가 많기 때문에 데이터를 검색하려는 개발자와 기업들이 주로 선택하는 옵션이다. 하지만 이러한 서비스들은 중앙 집중화 위험이 있기에 과거 데이터의 영속적인 저장을 필요로 하는 주체들에게는 리스크가 있는 옵션이다.
개별 벨리데이터들은 자체 서버를 통해 통해 기록 노드 데이터를 제공하여 사용자에게 서비스를 제공한다. 이는 공공재로서 여러 벨리데이터가 수행한다.
이 글을 작성하는 시점(2024년 8월 21일)을 기준으로 카이브의 메인넷은 15개월이 조금 넘었다. 이 기간 동안 KYVE는 약 6TB의 데이터를 보관하고 5,700만 건의 트랜잭션을 처리했다. 이러한 성장은 KYVE와 같은 서비스에 대한 수요가 상당하다는 것을 보여준다.
이러한 성과에도 불구하고 KYVE는 현재 코스모스 기반 블록체인만을 통합하고 있습니다. KYVE의 몇 가지 지표를 살펴보자.
2.2.1 지원되는 데이터 풀의 수
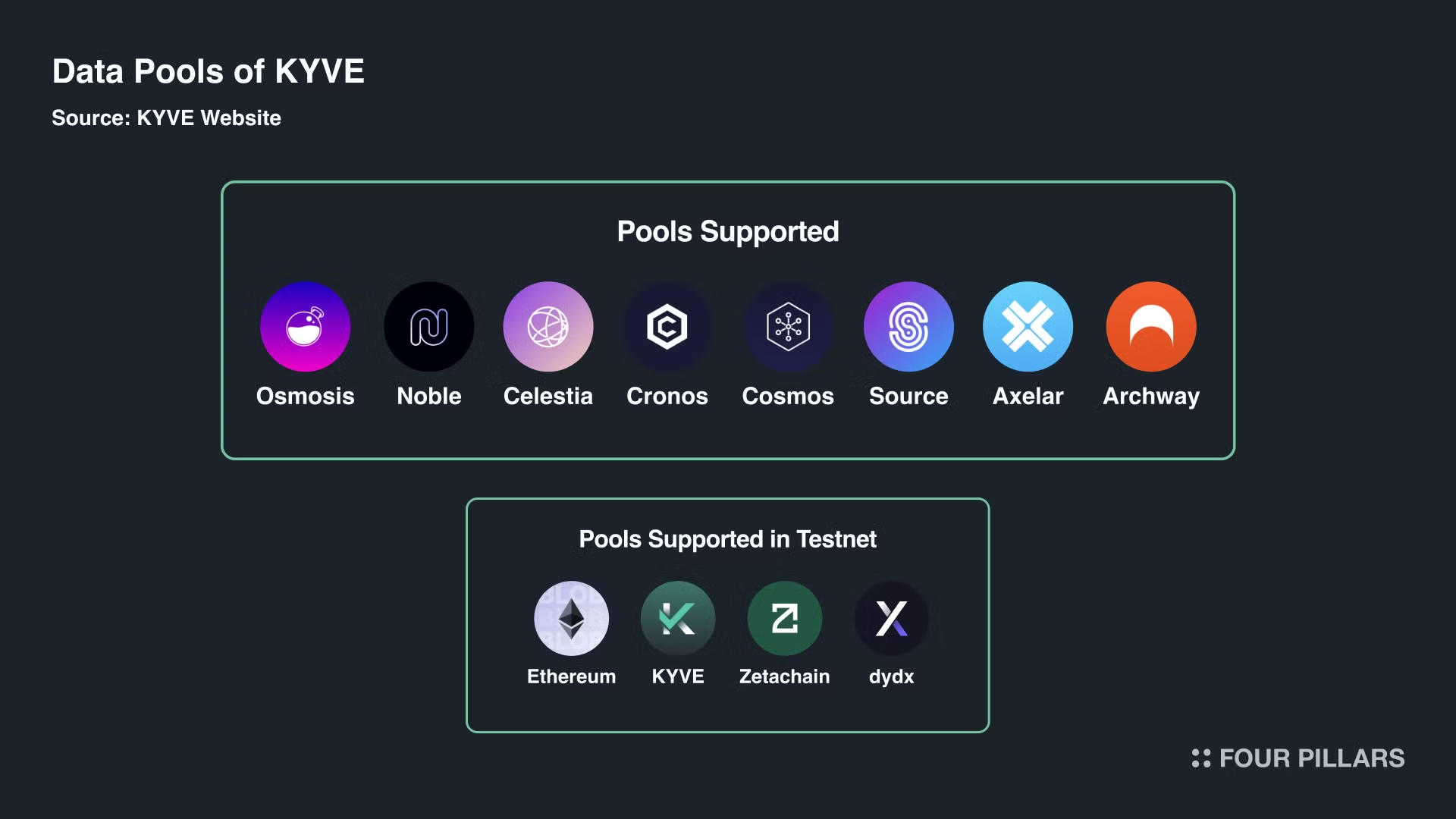
현재 8개의 풀이 운영 중이며, 이더리움, dYdX, 제타체인, KYVE 등에 대한 테스트넷 지원이 예정되어 있다. 테스트넷 지원은 아직 탈중앙화 플랫폼에 데이터가 저장되지는 않았지만 모든 도구가 작동한다는 의미이다.
현재 L1 및 L2 블록체인의 수를 고려할 때 KYVE의 시장 정유율은 높지 않다. 약 57개의 코스모스 블록체인, 다른 대체 L1, 그리고 올해 말 출시 예정인 수백 개의 L2가 있다. 풀 노드의 탈중앙화 데이터에 대한 수요가 높은 블록체인을 지원할 수 있는 잠재력을 가지고 있다.
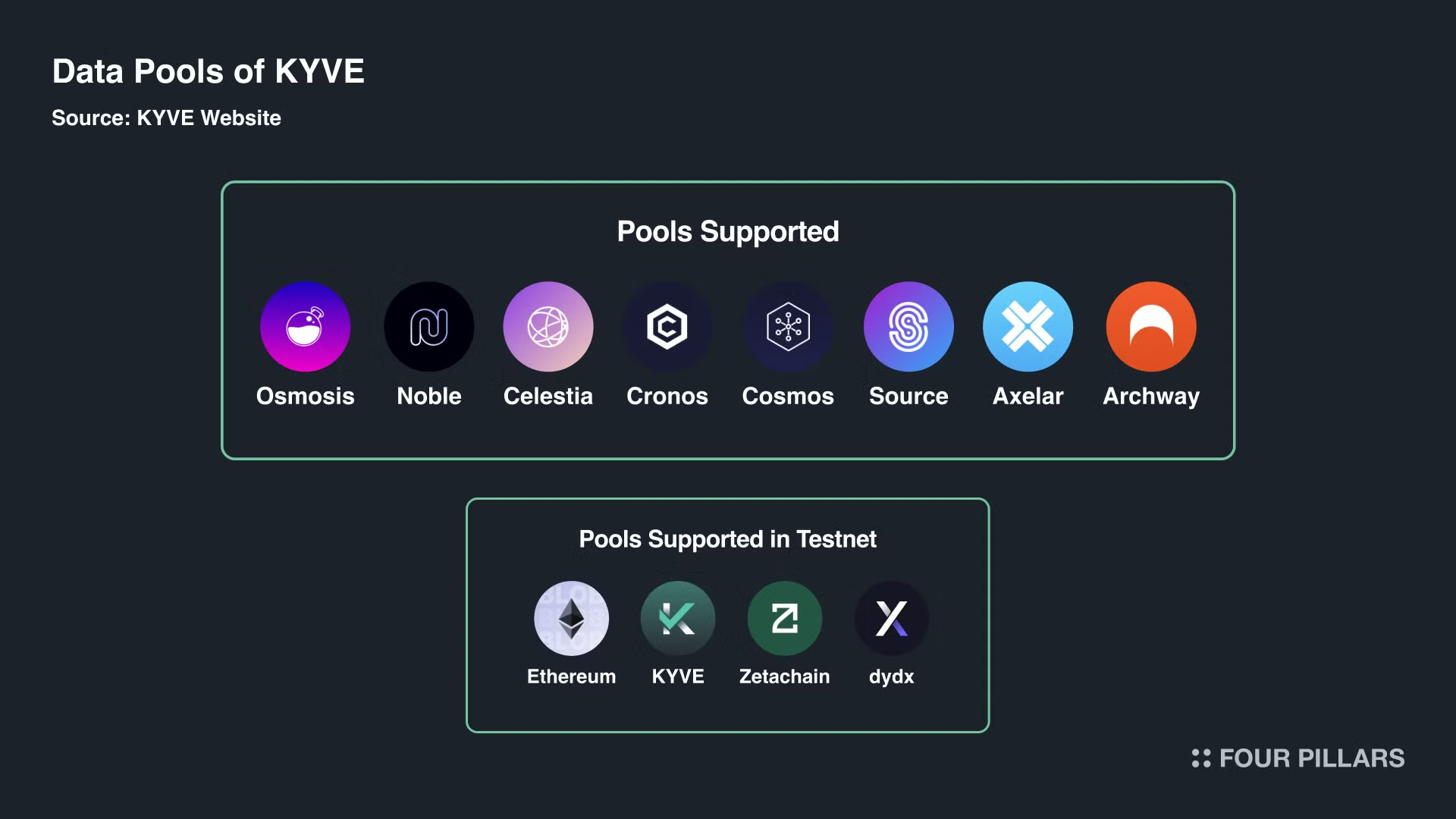
Source: The KYVE Data Ecosystem
2.2.2 현재 사용량 - 생성된 번들 수
KYVE 블록체인에서 “생성된 번들”이라는 용어는 데이터를 데이터 풀에 번들로 집계하고 저장하는 과정을 의미한다. 번들을 생성하는 과정에는 데이터 수집, 유효성 검사, Arweave와 같은 영구 데이터 스토리지 솔루션에 저장하는 등 여러 단계가 포함된다. 이 메트릭은 KYVE의 현재 사용량을 나타낸다.
아래 그래프는 시간이 지남에 따라 꾸준히 증가하는 것을 보여주며, 이는 KYVE 네트워크에서의 활동 또는 채택이 증가하고 있음을 보여준다. 번들 생성의 지속적인 증가는 탈중앙화 데이터 관리를 위한 기술을 활용하는 새로운 프로젝트나 파트너십으로 인해 KYVE 서비스에 대한 수요가 증가하고 있음을 나타낸다.
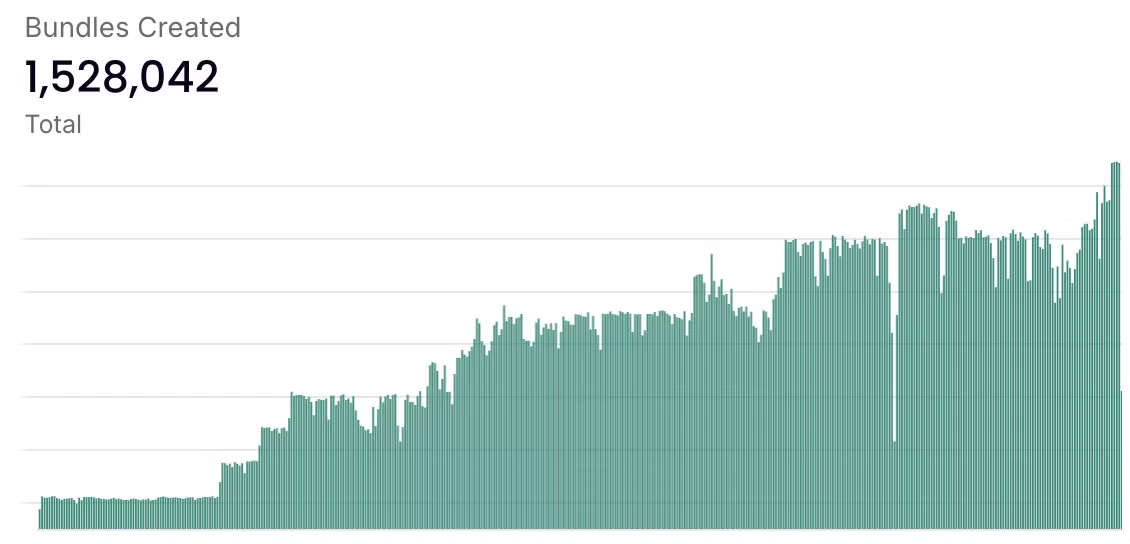
Source: KYVE - Activity
“KYVE는 출시 이후 인터체인 지원을 전문으로 하는 데 두 배로 집중해왔다. 그러나 저희 데이터 솔루션은 사용자 정의가 가능하기 때문에 EVM을 시작으로 웹3.0의 모든 개발자에게 더 나은 데이터 툴을 제공하기 위해 다른 에코시스템으로 확장하고 지원할 준비가 되어 있다.”
Related Articles, News, Tweets etc. :