
As time passes, the size of the blockchain becomes increasingly immense, leading to issues with data accessibility.
To address this, KYVE operates as an independent blockchain that facilitates data storage and access, making it easy for other blockchains to access data.
Now, one year after the mainnet launch, KYVE provides data services to approximately seven blockchains. Moving forward, KYVE’s expansion of its ecosystem through aggressive policies such as inflation splitting is highly anticipated.
After the Terra and FTX incidents, the trend of new Layer 1 chains emerging seemed to wane. However, as on-chain activity picked up again and the scalability limits of Ethereum and rollups became evident, the market’s demand for “fast and independent blockchains” resurfaced. This led to significant attention being paid to new Layer 1 chains supporting transaction parallel processing, particularly EVM parallel processing. Blockchains like Sui and Solana, which identify transaction dependencies for parallel processing, and blockchains like Sei, Monad, and Aptos, which optimistically execute parallel processing before identifying dependencies, have gained considerable attention. Additionally, blockchains with a finality time of less than one second, such as Injective, Sui, Sei, and Aptos, have also garnered significant interest.
The ability of blockchains, once perceived as slow, to process transactions instantly and increase the number of transactions processed in a given time through parallel processing is a significant improvement in user experience. This can be seen as an effort to make blockchains genuinely ‘usable.’ However, these blockchains are not without their issues. Even disregarding the much-discussed ‘decentralization’ concerns, the rapid processing of numerous transactions leads to an increase in the blockchain’s state size, making it challenging for validators to sync the state. The faster the blockchain, the more transactions it must handle in a short time, necessitating the rapid processing of a large volume of blocks. Consequently, this results in 1) increased node operation costs, 2) a general decline in blockchain performance, and 3) difficulties in syncing nodes (these issues will be discussed in more detail later).
Of course, the foundations developing these “fast blockchains” are aware of these problems and are trying to address them in their ways. However, it is also true that it is costly and time-consuming for each chain to devise its solutions. Therefore, today I want to introduce a project that aims to solve the data issues faced by other blockchains as an independent blockchain: the KYVE Network.
With the emergence of numerous blockchains, my criteria for evaluating their value is simple: “Is the problem they aim to solve clear?” While all blockchains have their own set of issues they address, the crucial point is whether these issues are necessary for the market. When I first learned about KYVE during their announcement of a collaboration with Solana, I realized that KYVE was tackling a genuinely critical problem. Let’s delve into the issues KYVE aims to solve and understand why they are essential.
The first issue is cost. To access and manage historical blockchain data, archival nodes are essential. However, operating these nodes incurs significant expenses for developers. For developers to seamlessly access data, they need to store the entire blockchain data, and storage costs increase over time. Moreover, without specific incentives provided by the blockchain itself, there is little motivation for participants to operate archival nodes voluntarily. Consequently, the number of archival nodes decreases as the blockchain ages.
A reduction in the number of archival nodes inevitably leads to centralization issues. Accessing historical data becomes dependent on a few archival nodes. Most existing data management solutions are centralized, which contradicts the fundamental reasons for using blockchain. A logically consistent decentralized network requires decentralized data management solutions to ensure the purpose of using blockchain is not diluted. This is one of the reasons KYVE is also built on blockchain.
With resource issues leading to fewer archival nodes and resulting centralization problems, accessing and validating blockchain data becomes increasingly challenging. This issue is inevitable for most blockchains, not just the so-called ‘high-performance blockchains,’ because blockchains are inherently expanding networks. What does this mean? From the genesis block to the most recent block, someone has to store and continuously add new blocks in real-time. This means that as time passes, the size of the blockchain inevitably grows, making it more challenging to store and access the vast amount of data.
As the number of archival nodes decreases and reliance on centralized data solutions increases, accessing and validating data becomes more difficult. If nodes take longer to process transactions, this indicates a decline in blockchain performance. This could transform high-performance blockchains into low-performance ones and make already slow blockchains even slower. If blockchain performance deteriorates further, it would deter people from using blockchain. Therefore, KYVE, though a third-party blockchain, aims to resolve data access and validation issues by handling them separately, thus addressing the data access and validation challenges of other blockchains.
In summary, KYVE not only enhances the efficiency of data storage, access, and validation but also helps other blockchains save costs. By introducing its own blockchain, KYVE ensures that blockchains relying on it are not exposed to centralization issues. So, how is KYVE structured to provide these services efficiently? The KYVE network has a unique structure compared to other blockchains, which we will explore in the next chapter, focusing on its structure and operation.
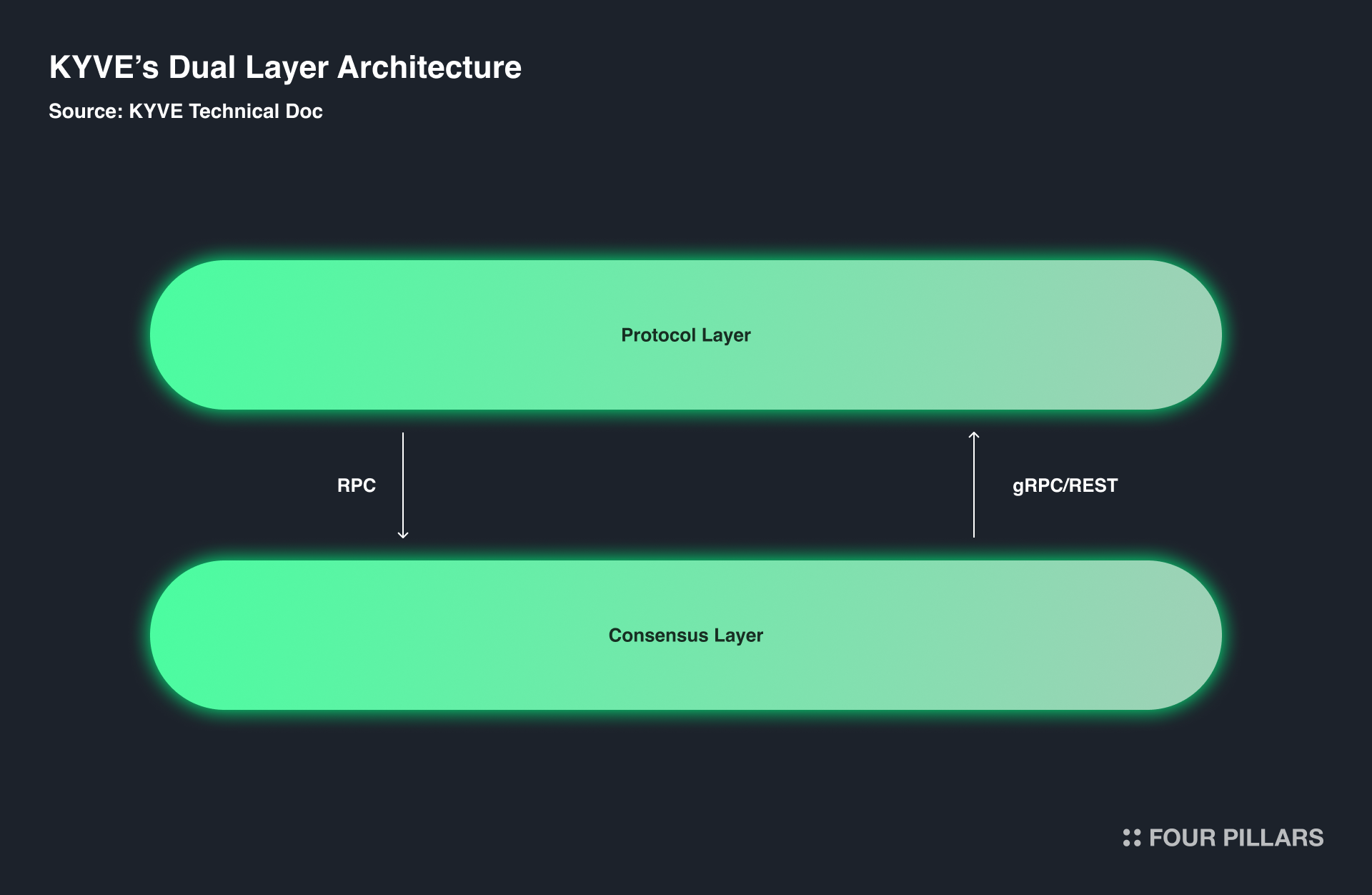
Through my research on various blockchains, I have examined many different structures, but the KYVE Network stands out as one of the most unique. While KYVE Network is classified as a Layer 1 blockchain with its own consensus mechanism, it features a modular design with two distinct layers. KYVE refers to this as a dual-layer structure, which consists of the Consensus Layer and the Protocol Layer, each performing separate functions. Why did KYVE choose to design its network in such a unique way?
Before diving into the structure of the KYVE Network, let’s define some key concepts to understand it fully.
2.1.1 Data Pool or Storage Pool
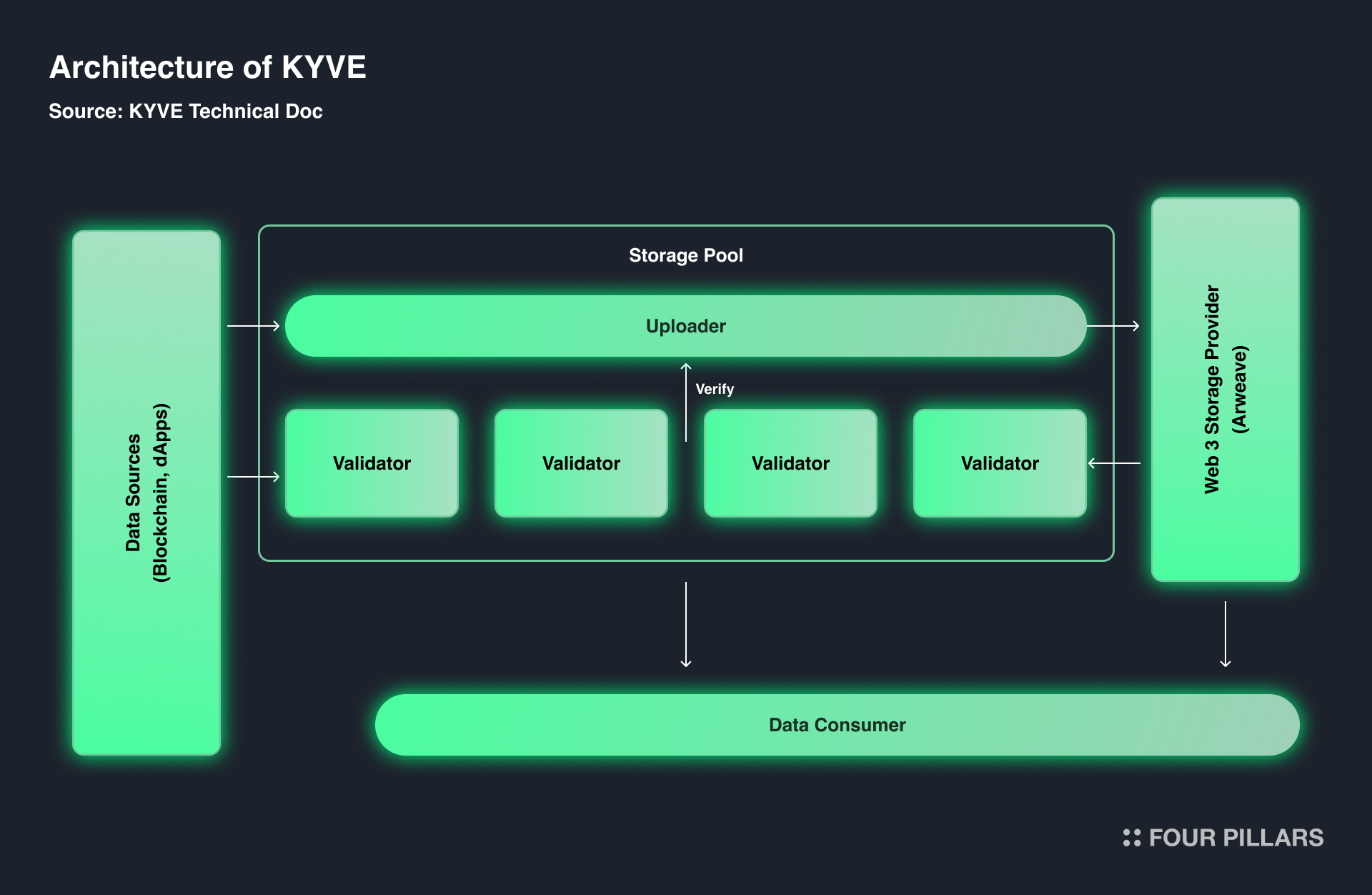
First and foremost is the Data Pool or Storage Pool. As the name suggests, these pools are centered around data sources (each data pool can only hold data from a single data source. For example, a data pool that sources data from the Cosmos Hub can only store and verify data coming from the Cosmos Hub). Anyone can freely create a pool through governance and set the data streams they wish to store in that pool. Additionally, data pools operate 100% on-chain, ensuring they run in a transparent and decentralized environment. This raises the question: who should create and manage these pools, and why? This is where KYVE’s protocol layer comes into play. As I will explain later, validators within the protocol layer participate freely in these pools to verify the data, thus managing the pool.
In other words, the data in the data pools can be seen as unverified data collected in one place. Validators then verify this data, and the verified data is subsequently stored.
2.1.2 Data Bundle Proposal
A data bundle refers to the aggregation of multiple data points into a single bundle. Why bundle data? While storing data itself is straightforward, sourcing and storing data from various places is complex. KYVE addresses this with data bundle proposals, which group data for more efficient processing.
Instead of continuously fetching data, KYVE submits bundles in rounds, enabling efficient data transmission and storage. Each round presents a bundle containing data from various sources, which is then submitted to the data pool for validator verification.
2.1.3 Uploader and Uploader Selection
Uploaders are responsible for submitting the data bundle proposals to the data pool. They fetch data from sources, store it in decentralized storage, and send it to the data pool for validator verification.
Uploaders are selected from the protocol validators (not chain validators) in each round, with a higher chance of selection given to validators with more delegated tokens (voting power).
2.1.4 Protocol Validator
Protocol validators verify the validity of the data bundles submitted by the uploaders. They retrieve data from distributed storage, compare it with the uploader’s data, and vote on whether it is valid or invalid.
*Note that KYVE Network has two types of validators, and here we are discussing the Protocol Layer validators.
2.1.5 Funder
Funders financially support KYVE’s data pools. They are entities with a vested interest in the data stored within a specific pool, such as projects needing the data or foundations wanting to store their data. Anyone can become a funder, but there are no specific rewards for funding a pool.
If you have understood the above concepts, let’s delve into KYVE’s unique dual-layer structure and examine why KYVE, despite being a Layer 1 blockchain, divides tasks across two layers.
2.2.1 Consensus Layer
The Consensus Layer is responsible for consensus and protocol security, similar to traditional Layer 1 chains. KYVE is built on the Cosmos SDK and uses a dPoS system, like other Cosmos SDK-based blockchains. The role of chain validators is also similar to validators in other Cosmos SDK-based blockchains, so we will skip a detailed explanation of chain validators.
2.2.2 Protocol Layer
While the Consensus Layer resembles traditional blockchains, the Protocol Layer sets KYVE apart. The Protocol Layer’s primary function is managing the data pools described earlier. This layer is where KYVE’s practical use cases emerge. Protocol Layer validators collect data, store it in a decentralized permanent storage protocol like Arweave, and verify the stored data to ensure it meets user requirements (they also retrieve and verify data stored on Arweave to deliver to requesting users).
As we will discuss later, users can delegate tokens to both chain validators and protocol validators.
2.2.3 Why Dual Layer?
Upon encountering KYVE’s dual-layer structure, the initial impression might be that it is quite complex. Why did KYVE adopt this dual-layer structure despite the added complexity? There are several reasons, but the primary one is optimization. If the same validators managed data pools and ensured blockchain security, it could lead to suboptimal performance in one area. Chain validators do more than maintain the network; they also handle governance and other tasks. Adding the responsibilities of verifying, retrieving, and storing data from data pools could reduce overall performance.
Secondly, the dual-layer structure offers advantages in terms of scalability. By separating layers with different functions, the Protocol Layer can scale independently to meet increasing data demands without affecting the Consensus Layer.
Lastly, KYVE supports various chains (as it often serves other blockchains and developers). Since the Protocol Layer operates independently of the Consensus Layer, KYVE can support multiple chains without altering the core blockchain, which is another significant advantage of the dual-layer structure.
Having understood KYVE Network’s unique structure, let’s explore how KYVE Network operates.
2.3.1 How does Data Pool work
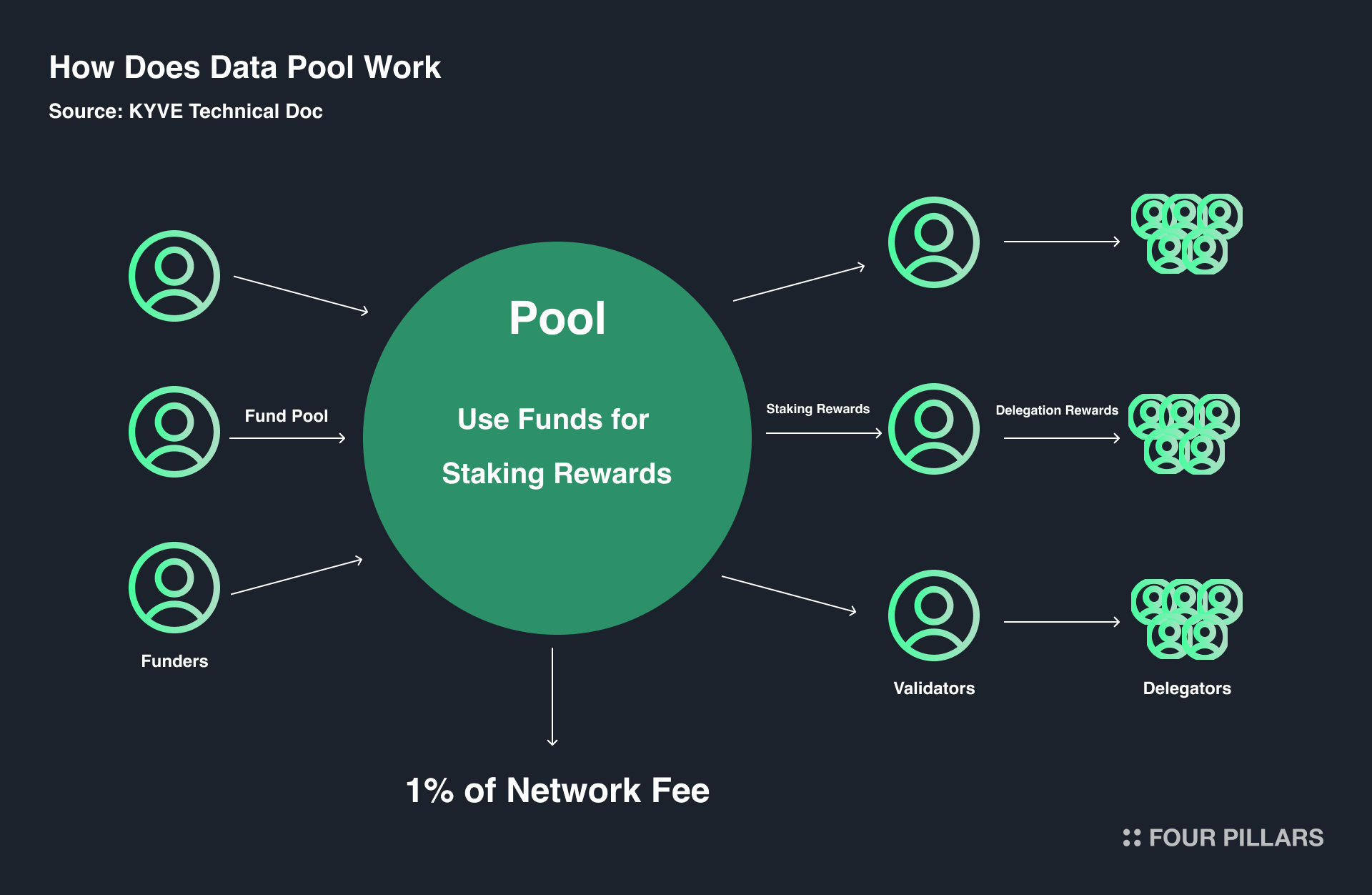
To operate a data pool, the following steps must occur: 1) someone needs to collect and bundle the data, 2) submit the bundle to the pool, 3) verify the submitted data, and 4) store the data in decentralized storage. Given that incentivizing actions through rewards is a core principle of blockchain, KYVE has designed an incentive structure to autonomously execute these four tasks within the data pool.
The rewards for KYVE’s data pools come from funders. Since the data verified and stored by KYVE is ultimately needed by someone, the entities supporting the pool (funders) are likely to be projects or foundations that require the verified data that KYVE provides. However, anyone can become a funder. Funders benefit from efficient access to verified data through KYVE, while protocol validators are rewarded for their roles in collecting, storing, and verifying the data.
What about ordinary users? They can also earn pool rewards through delegation. As previously mentioned, users can delegate tokens to either chain validators or protocol validators. When tokens are delegated to protocol validators, users receive a portion of the rewards earned by these validators based on the amount delegated. Conversely, if a validator incorrectly verifies data or retrieves incorrect data, they may be slashed, so users must carefully choose which protocol validators to delegate their tokens to.
The reason for implementing this PoS mechanism not only at the chain level but also at the protocol level is to apply the principles that sustain the blockchain to the data pool. Validators with more delegated tokens have a higher chance of being selected to verify or upload data, thus earning more rewards(This also ensures that on the protocol, if the uploader behaves in a malicious manner, they will be penalized by slashing).
This structure ensures that KYVE maintains the integrity and efficiency of both blockchain operations and data pool management, leveraging delegation to optimize performance and incentivize correct data handling.
Interpool Security
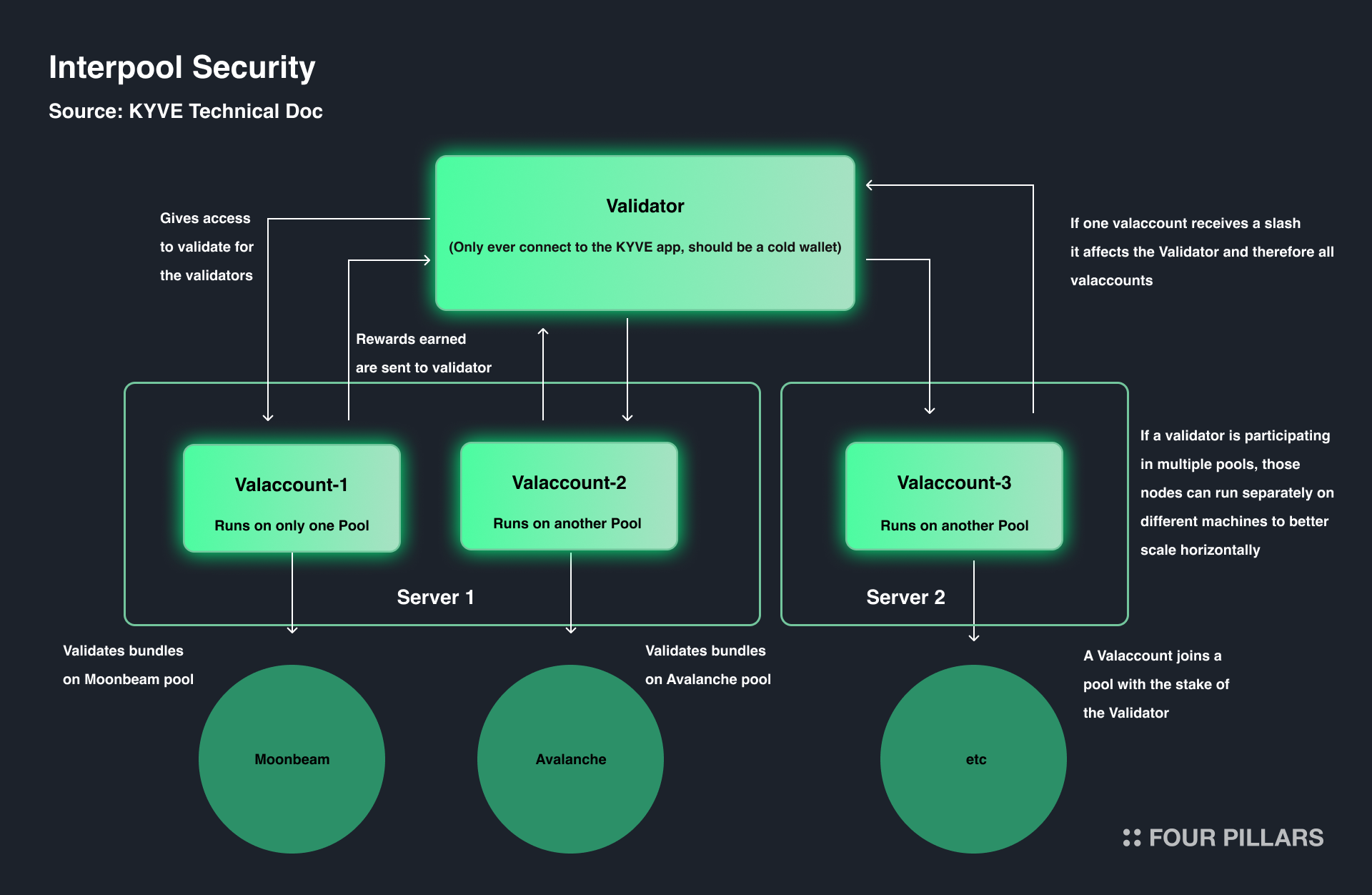
Previously, KYVE allowed each protocol validator to manage only one data pool. However, this approach caused inefficiencies in several ways. Limiting each validator to a single pool reduced the number of data pools managed by more stable validators with significant delegations, thereby hindering the scalability of KYVE’s services. Since the stability of a data pool depends on how many tokens the managing validator has been delegated, KYVE introduced a new initiative to enable trusted validators to manage a wider variety of data pools.
To facilitate this, KYVE introduced a new concept: Valaccounts. Validators can assign verification authority to each valaccount without sharing their private keys or mnemonic phrases. This design allows validators to securely manage multiple data pools, enhancing the security of the data pools and creating a win-win situation where both validators and stakers can earn their rewards.
2.3.2 Lifecycle of Data in KYVE
Now that we understand how data pools operate, let’s explore the lifecycle of data in KYVE and how it flows through various processes.
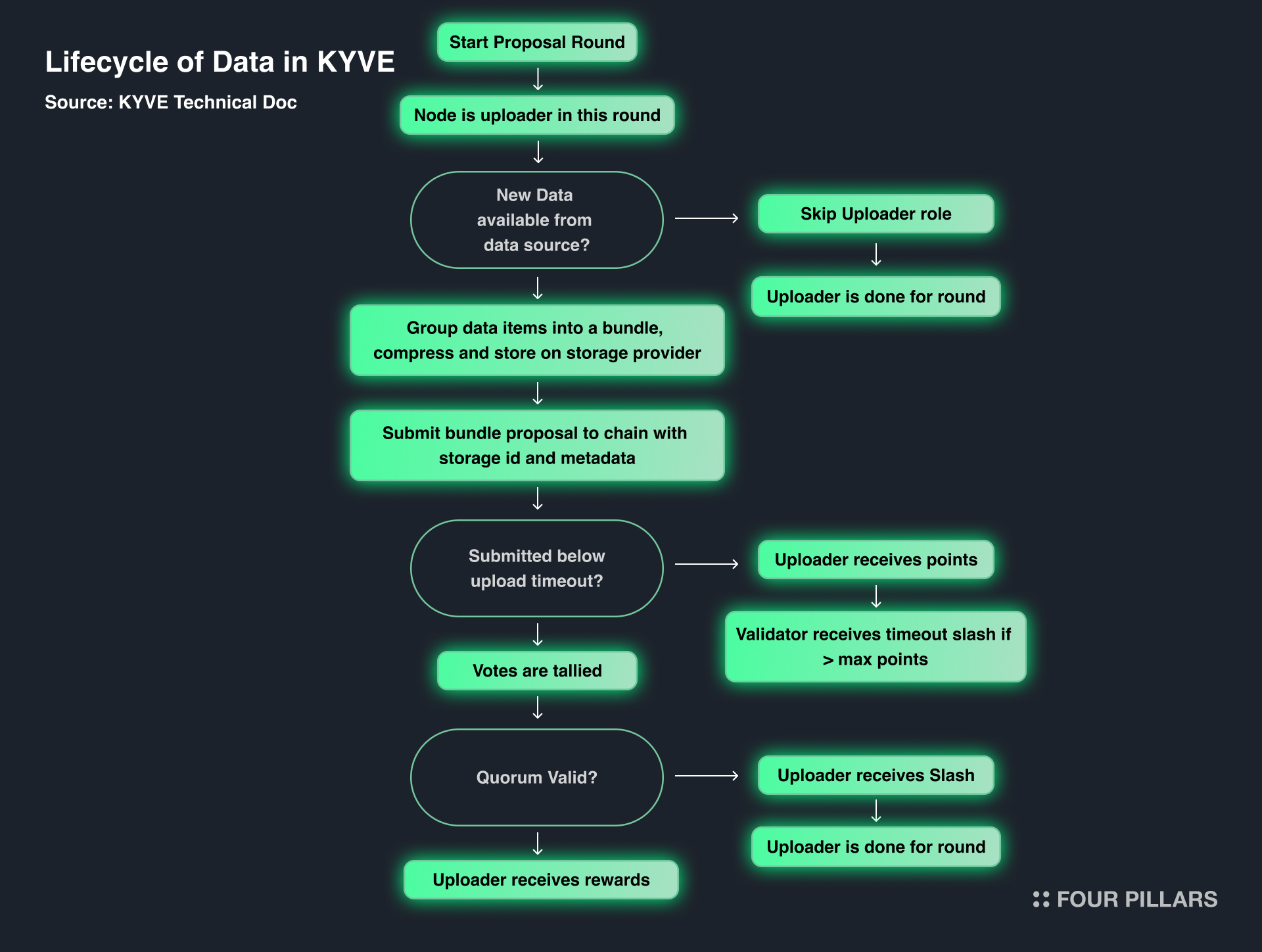
First, let’s examine the three pathways through which data moves within KYVE to understand its operation. Typically, the archiving process begins when new data is available from the data source, so we will start with the scenario where new data is present at the data source.
Case 1: Data received from the source but not presented within the given time
When additional data is available from the source, it is gathered and bundled together → The bundle, along with the storage ID and metadata, is presented to the data pool → The allotted time elapses → The uploader receives a penalty (points) for failing to present the bundle within the given time → If the uploader accumulates a certain number of points, they are slashed.
Case 2: New data from the source, bundle presented but failed verification
When additional data is available from the source, it is gathered and bundled together → The bundle, along with the storage ID and metadata, is presented to the data pool → Validators begin voting on the data in the bundle → It is concluded that the data is invalid → The uploaders are slashed as a penalty for presenting invalid data.
Case 3: New data from the source, bundle presented and verified successfully
When additional data is available from the source, it is gathered and bundled together → The bundle, along with the storage ID and metadata, is presented to the data pool → Validators begin voting on the data in the bundle → It is concluded that the data is valid → The uploaders receive a reward, and the bundle is stored in decentralized storage.
We have examined KYVE Network’s unique structure and operation. However, understanding how this structure is maintained and strengthened raises questions about KYVE’s economic model, which also sets it apart from other blockchains. This chapter explores KYVE’s tokenomics and how KYVE tokens are distributed and rewarded.
At the chain level, KYVE’s tokenomics are similar to those of other Cosmos SDK-based chains. The key difference is the implementation of a burn model. KYVE adopts elements of the EIP-1559 model to align the interests of validators (who benefit from ongoing token rewards through inflation) and token holders (who benefit from the token’s value appreciation). By continually burning a portion of protocol fees without capping inflation, KYVE aims to enhance the token’s value.
As previously mentioned, the protocol level’s tokenomics differ from the chain level. Instead of being maintained by inflation, it is funded by third-party sponsors. Entities that need data services buy KYVE tokens and allocate them to the desired data pool, incentivizing protocol validators to manage that pool.
If sponsorship for a specific pool ceases, the pool stops operating until new sponsorship is received. This mechanism encourages continuous sponsorship from projects or foundations that rely on the data in the pool.
One might question the sustainability of data pools solely supported by sponsorships. While KYVE’s protocol layer is a key differentiator, it lacks initiatives to ensure its long-term viability at the network level. To emphasize the protocol layer’s importance and enhance its sustainability, KYVE introduces inflation splitting.
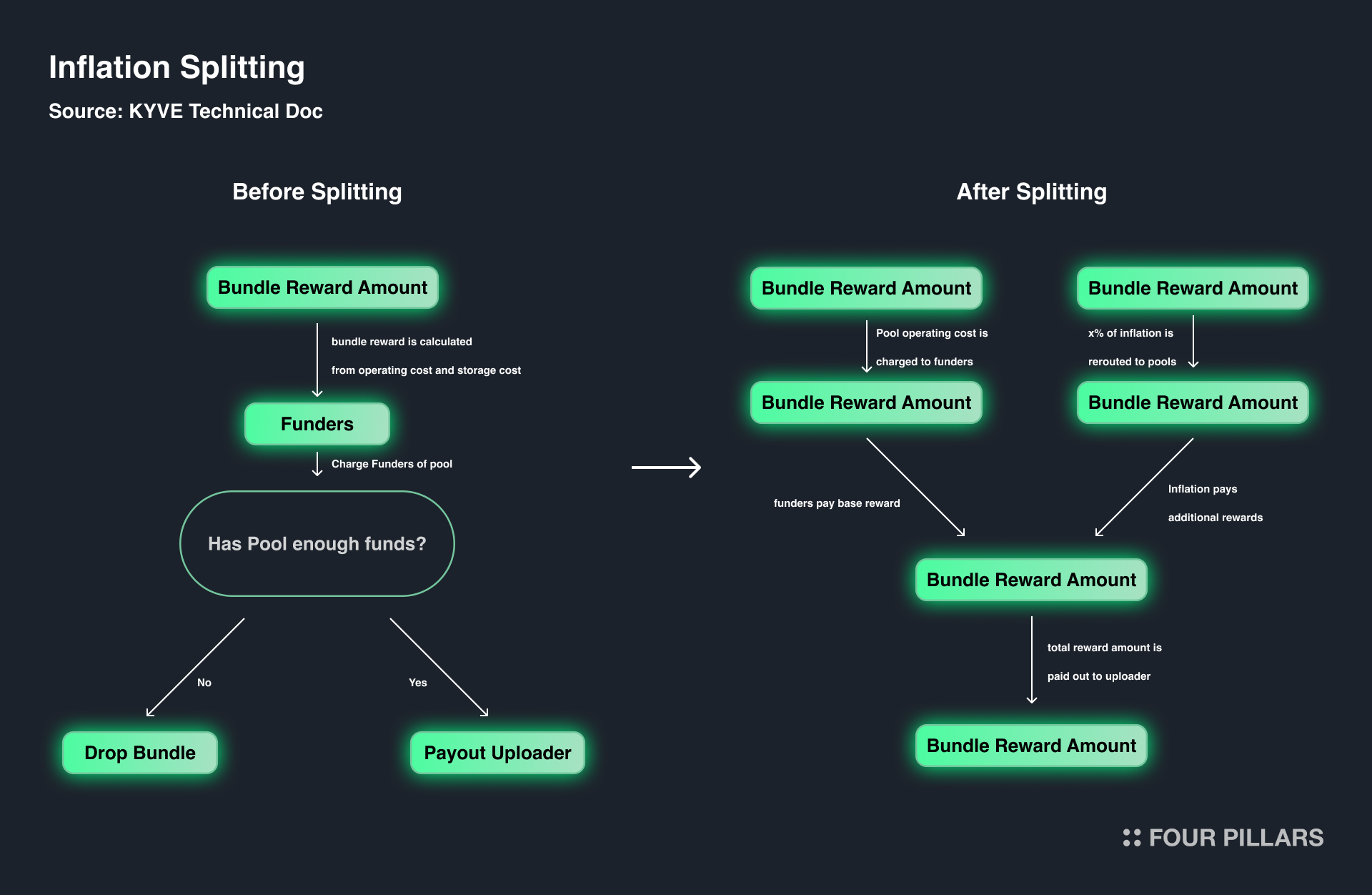
Inflation splitting allocates a portion of the inflationary rewards from the chain level to support the protocol layer. This ensures that the protocol layer remains robust and can continue to provide valuable services, creating a more balanced and sustainable economic model for the entire KYVE Network.
With the v1.5 upgrade, KYVE is planning to introduce a multi-coin funding initiative. This means expanding the current sponsorship model, which has been solely reliant on KYVE tokens, to include tokens from various chains. This initiative is beneficial for both sponsors and stakers. For sponsors, particularly foundations, it allows them to directly use their own tokens for sponsorship without converting them into KYVE tokens. For stakers, it provides the opportunity to receive rewards in a variety of tokens, not just KYVE.
Users staking in the protocol layer will be able to stake KYVE tokens and receive rewards in $TIA (Celestia), $ATOM (Cosmos), $AXL (Axelar), and other tokens. If you have a positive long-term outlook on KYVE’s partner protocols, staking KYVE tokens in the protocol layer could be a strategic move.
As of the writing of this article (July 30, 2024), KYVE’s mainnet has been live for just over 14 months. In this period, KYVE has archived approximately 6TB of data, processed 57 million transactions, and operated 11 data pools across 7 blockchains. This growth demonstrates a substantial demand for services like KYVE’s, indicating a step toward achieving Product Market Fit (PMF).
Despite its achievements, KYVE currently supports only Cosmos-based blockchains, and high-performance blockchains that truly need KYVE’s services have yet to onboard. Moreover, although KYVE has partnerships with numerous blockchains, it does not provide data pools for all of them.
What should KYVE do to expand its reach? The answer may lie in the initiatives KYVE is already pursuing, and here are some of my thoughts:
Aggressive Business Expansion:
The term “aggressive business expansion” might sound vague, but like any startup, KYVE needs to aggressively expand its business, even at the cost of short-term financial losses. For KYVE, this could mean setting up data pools related to major blockchains and rewarding them with tokens before third-party funders appear. Network-level inflation might be necessary for this, and while excessive inflation could be seen as a deficit, it aligns with the typical startup expansion model.
To retain customers, the first step is to get them to try the service. I believe KYVE’s services and products are excellent, but users won’t know this unless they try them. By increasing expenditure to expand business, KYVE can explore new opportunities. KYVE is already showing efforts to strengthen the protocol layer through initiatives like inflation splitting, so expanding expenditure in this area could be beneficial.
B2C Initiatives:
Although KYVE primarily serves protocols and decentralized applications, making it more B2B than B2C, the biggest challenge for B2B protocols is their lack of retail connection. This can lead to lower awareness and difficulties in onboarding new protocols. Increasing consumer awareness could lead to more protocols being interested in KYVE.
I have a long-standing connection with KYVE. I wrote a research article on KYVE before their mainnet launch and have continued to follow their progress closely. KYVE is one of the few networks that remains focused on its core mission despite the hype and short-term narratives in the crypto space. While the current crypto market is dominated by speculation and memes, networks like KYVE, which steadily perform their intended roles, deserve more attention.
Revisiting KYVE for this research, I observed that both the KYVE community and core contributors are continuously striving to identify and address their shortcomings. Initiatives like multi-coin funding and inflation splitting are examples of their efforts to improve. This gives me hope for KYVE’s future, and I wish to see more people learning about KYVE. As blockchain continues to face increasing challenges with data access and storage, KYVE’s role will become even more critical. Time is on KYVE’s side.
Dive into 'Narratives' that will be important in the next year