
여러 프로젝트들이 근시안적인 관점을 가지고 단기적인 내러티브와 에어드랍에 의존하여 지속가능성에 문제를 일으키고 있는 와중에, 지난 수년간 꾸준히 자신들의 프로덕트를 만들고 보완해온 프로토콜들도 분명히 존재한다.
더 그래프는 그러한 프로젝트들의 대표적인 예시라고 할 수 있다. 더 그래프는 데이터 인덱싱/쿼리잉 인프라로서 지난 3년간 다양한 애플리케이션과 블록체인들에 데이터 쿼리잉과 인덱싱 서비스를 제공해주었고, 에어드랍이나 포인트 시스템이 없이도 사용량은 꾸준히 올라가고 있다는 점에서 매우 고무적인 사례라고 할 수 있다.
뿐만 아니라, 더 그래프는 지난 3년간 구축된 인프라를 활용하여 AI와 크립토가 결합하는데에 있어서 핵심 인프라가 되려고 하고, 벌써부터 AgentC와 같은 흥미로운 프로덕트를 출시하고 있다. 항상 말보다 행동으로 보여줬던 더 그래프이기에, 앞으로 더 그래프가 보여줄 프로덕트들이 매우 기대가 된다.
필자가 이전 아티클에서도 설명한 바 있지만, 이 시장에서 새로운 기술과 새로운 내러티브 만큼이나 중요한 것이 바로 꾸준함과 지속가능성이다(적어도 필자는 그렇게 믿고있다). 리서처로써의 의무는, 새로운 내러티브와 업계의 트렌드를 설명하고 소개하는 것 만큼이나 이 시장에서 꾸준하게 자신들의 가치와 문제의식을 투영하는 프로젝트를 조명하고 그들의 역사와 앞으로의 가능성을 서술하는 것이기도 하다. 그런 측면에서 필자가 오늘 소개할 프로토콜은 매우 흥미로운 역사와 변화를 맞이하고 있다는 점에서 한 번 조명받아 마땅하다고 생각했다. 더구나 블록체인과 AI의 결합이 다방면으로 시도되고있는 지금, 오늘 필자가 소개할 이 프로토콜의 역할이 매우 중요해질 것이라고 생각한다. 필자가 오늘 소개할 프로토콜은, 가장 오랜시간동안 탈중앙 인덱서로써 시장을 지키고 있었던 더 그래프(the Graph)의 이야기다. 필자는 이번 아티클을 통해서 1) 왜 지금 더 그래프에 주목을 해야 하는지 2) 왜 더 그래프의 미래 성장성이 기대될 수 밖에 없는지를 중점적으로 다뤄볼 생각이다.
필자는 왜 지금 더 그래프에 대해서 다루는가? 프로토콜 레벨에선 지금이 더 그래프에게 있어서 굉장히 중요한 변곡점을 맞이하는 시기이기도 하고(뒤에서 후술하겠지만, 이제는 단순히 인덱싱 프로토콜이 아닌 탈 중앙 데이터 서비스 프로토콜로 거듭나고자 한다), 더 나아가 더 그래프같이 정기적으로 꾸준한 수요(더 그래프를 사용하려고 하는 수요)를 창출하는 프로토콜도 시장에 굉장히 드물기 때문이다. 대부분의 블록체인들, 그리고 그들 위에서 작동하는 수많은 애플리케이션들은, 유기적으로 유저들을 끌어모으기 힘들기 때문에 포인트와 에어드랍을 통해서 일시적으로마나 유저들을 끌어드리려고 하는 반면, 더 그래프는 이러한 가시적인 인센티브 없이도 프로토콜에 대한 꾸준한 수요를 만들어냈다. (밑에서 후술하겠으나, 현재 기준으로 약 한 달에 10억개의 쿼리를 처리하고 있다)
이런 측면에서, 만약 누군가가 블록체인의 펀더멘탈을 중요하게 생각한다면, 더 그래프는 이에 대한 모범답안이 될 것이라고 생각한다. 뿐만 아니라, 앞으로 AI와 블록체인이 결합하는 것이 중요해지는 블록체인 시장의 판도를 미루어볼 때, 더 그래프와 같은 데이터 인덱서에 대한 수요가 많아질 것이라고 생각하기도 하는데, 필자는 이번 리포트를 통해서 더 그래프의 역사와 변화 그리고 블록체인 시장 상황 변화에 따른 더 그래프에 대한 수요변화를 중심으로 이야기를 풀어내어, 왜 지금 우리가 더 그래프에 관심을 가져야 하는지를 풀어내보고자 한다.
우선, 더 그래프에 대해서 자세히 알아보기 전에, 필자가 더 그래프에 주목하는 두 가지 이유들에 대해서 먼저 간략하게 살펴보자.
1.1.1 In an Era Where AI and Blockchain Merge, The Graph Can Become the Core Infrastructure
현재 블록체인 시장에선, AI와 블록체인의 결합이 이 시장에 어떤 시너지를 불러다줄 수 있을지에 대한 논의가 한창이다. AI와 사람을 구분하기 위해서 사람임을 인증하게 만드는 프로젝트들도 있는 반면, AI로 인해 부족한 컴퓨팅 자원을 수급하기 위해 잉여자원을 공유하는 프로젝트도 나타나는등, 시장에선 정말 다양한 이야기들이 오가고 있다. 하지만 필자의 관점에서 봤을 때, 이 두 기술이 낼 수 있는 가장 명확한 시너지는 바로 온 체인 데이터를 활용해서 블록체인 애플리케이션들을 좀 더 유저 친화적이게 만들 수 있다는 부분에 있다고 생각한다. 예시를 들어보자. 만약에 AI가 이더리움 생태계에 있는 모든 DEX 관련 데이터를 학습했다고 한다면, 이더리움 DEX들마다 파편화 되어있는 정보들을 하나로 모아서 좀 더 현명한 트레이딩을 하도록 도울 수 있을 것이다. 여기서 한 발짝 더 나아가서, 에이전트들이 복잡한 작업들(에어드랍을 받기 위해서 반드시 수행해야만 하는 작업들을 대신 해준다던지)을 대신 수행해준다면 유저들의 온 체인 경험은 큰 폭으로 개선될 것이다. 하지만 이러한 작업들을 하기 위해서 선제적으로 필요한 것이 있다. 바로 “온 체인 데이터 인덱싱”이다.
또한, 결국 AI도 연산을 해야하고, 연산을 하기 위해선 데이터가 필요하다. 특히나, 온 체인 데이터를 주기적으로 사용해야하는 위 예시들의 경우에는 온 체인 데이터들에 빠르게 그리고 효율적으로 접근하여 연산해야한다. 그런데 만약에 데이터를 제공해주는 주체가 AI 연산을 위한 컴퓨팅 자원까지 지원해준다면 어떨까? 놀랍게도 현재 더 그래프가 나아가는 방향성이 바로 이것이다. 더 그래프는 방대한 온 체인 데이터를 가지고 있는 것과 더불어서 더 그래프를 유지하고 있는 노드들이 컴퓨팅 자원도 가지고 있기 때문에 AI가 필요한 데이터와 컴퓨팅 자원을 동시에 제공해줄 수 있는 AI에 가장 중요한 인프라 자원이 될 수 있다. 그렇기 때문에 온 체인 데이터를 사용하는 AI 관련 서비스가 많아질수록, 더 그래프와 같은 데이터 서비스 프로토콜이 반드시 쓰일 수 밖에 없는 이유는 늘어날 것이고, 이것이 우리가 관심을 가져야 하는 이유이다.
1.1.2 In an Age of Points and Airdrops, The Graph Is a Case of Creating Real Demand
이제는 NFT 마켓플레이스의 선두주자가 된 블러(Blur)의 팩맨(Pacman)이 포인트 시스템을 들고 나왔을 때는, 포인트 시스템이 초기 유저들을 모으는데에 아주 유용한 전략으로 사용되었으나 무엇이든지간에 남용되면 그 가치를 잃는 법이다. 블러의 성공을 본 수많은 프로젝트들은 이제 너도나도 다 포인트 시스템을 활용하여 자신들에 대한 수요를 인위적으로 창출하고 있다(블러가 성공할 수 있었던 이유는, 단순히 포인트 시스템을 도입해서가 아니라, 프로덕트가 좋아서였음에도 불구하고 수많은 프로젝트들은 자신들이 만드는 프로덕트의 퀄리티보다, 블러가 포인트를 통해서 유저들을 모았다는 것에만 집중하고 있는 현실이 안타깝다).
하지만 이런식으로 가짜 수요를 창출하는 행위들은, 결코 지속가능하지 않다. 시간이 흘러서 포인트가 토큰으로 바뀌는 시점이 도래하면 유저들은 언제 그랬냐는듯 해당 프로토콜들을 사용하지 않을 것이다. 그럼에도 불구하고 수많은 프로토콜들이 이렇게 포인트나 에어드랍을 사용해서 유저들을 끌어모으는 행위들을 강행하는 이유는, 안타깝게도 이들이 진정한 PMF를 찾지 못했기 때문이다. 너무 당연한 이야기지만, 이제 사람들은 포인트와 에어드랍에 꽤 지친듯 보인다. 물론 공짜돈은 언제나 좋지만, 이런 것들만 성행해서는 시장이 성장할 수 없다. 이런 맥락에서 더 그래프는 굉장히 유의미한 사례라고 할 수 있다. 왜냐하면 이들은 이들이 하고 싶은 것을 한다거나 시장의 단기적인 유행에 편승하지 않고, 블록체인 시장이 가진 문제점과 시장에서 필요한 프로덕트를 파악한 뒤 이에 맞는 솔루션을 제공하였고, 이는 결국 유기적이고 지속적인 수요를 창출하였기 때문이다.
물론 블록체인 시장은 굉장히 내러티브 주도적이기 때문에, 단기적인 하이프에 편승하는 경우도 많지만 프로토콜의 펀더멘탈을 중요한 가치로 생각하는 분들이라면, 더 그래프는 반드시 지켜봐야하는 프로젝트라고 할 수 있다.
더 그래프가 왜 중요한지는 잘 알겠다. 그런데 도대체 더 그래프는 구체적으로 무엇을 하는 프로토콜일까? 더 그래프에 대한 자세한 설명을 하기전에 필자가 단언하건데, 더 그래프는 사람들이 인지 하지는 못했지만, 가장 많이 사용해본 프로토콜 중 하나일 것이다. 여러분이 만약 파캐스터(Farcaster), 라이도(Lido), 유니스왑(Uniswap), ENS(Ethereum Naming Service), 아베(Aave), 컴파운드(Compound), GMX, 스시스왑(Sushiswap), 커브(Curve) 를 한 번이라도 사용해보셨다면, 더 그래프를 간접적으로 사용하셨을 것이기 때문이다. 이제, 더 그래프의 주요 역할과 구조 그리고 작동 원리를 알아보도록 하자.
1.2.1 The Graph as a data indexing and querying infrastructure
우선 더 그래프의 가장 잘 알려진 역할은 블록체인에 있는 데이터를 인덱싱하고 쿼리잉(Querying) 해주는 일이다. 데이터 인덱싱과 쿼리잉은 무엇일까? 인덱싱은 쉽게 말해서 데이터 베이스에 저장된 데이터를 좀 더 쉽게 찾을 수 있도록 도와주는 역할을 한다고 할 수 있다. 예를 들어 우리가 책을 보면서 책에 있는 정보(키워드와 같은)를 찾을 때 첫 페이지부터 하나씩 읽어가면서 정보를 찾는 거 보다, 내가 원하는 정보가 어디에 있는지 미리 표시해두면 좀 더 효율적으로 정보를 찾을 수 있듯, 인덱서 역시 정보를 찾기 위해서 데이터 베이스 전체를 살피는 것이 아니라 찾고자 하는 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 데이터를 찾고자 하는 사람이 빠르게 찾을 수 있도록 돕는 것을 이야기 한다.
데이터 쿼리잉이란, 데이터 베이스에게 자기가 원하는 데이터를 요청하는 작업을 일컫는다. 즉 더 그래프는 블록체인에 있는 데이터를 쉽게 찾을 수 있도록 도와주고, 데이터를 요청했을 때 그 요청한 데이터를 전달해주는 역할을 한다고 볼 수 있다. 더 쉬운 이해를 위해서 더 그래프가 데이터를 쿼리잉 해주는 과정을 설명하자면 이는 아래와 같다:
Lifecycle of Data Querying

유저들이 디앱(dApp)의 프론트엔드와 상호작용한다.
디앱들은 더 그래프의 SQL 게이트웨이에 데이터를 요청한다.
SQL 게이트워이는 디앱이 요청한 데이터를 제공해줄 수 있는 인덱서를 찾는다.
선택된 인덱서는 디앱이 요청한 데이터를 이미 가지고 있을 것이기에 데이터를 추출하여 제공해주고 쿼리에 대한 수수료를 받는다.
게이트웨이는 해당 데이터를 디앱에 전달한다.
디앱은 해당 데이터를 프론드엔드에 띄워서 보여주거나, 해당 데이터를 사용한다.
Indexing and Querying Blockchain Data is hard
이렇게 설명만으로는 굉장히 쉬운 작업인 거 같지만 블록체인에 있는 데이터를 인덱싱하고 쿼리링 해주는 것은 상당히 어려운 작업이다. 왜냐하면 블록체인은 파이널리티라는 속성도 존재하고, 체인이 리오그 되거나, 고아 블록이 생기는 경우가 종종 있기 때문에 알맞은 정보를 효율적으로 가져오는 것이 굉장히 어려운 환경이기 때문이다. 또, 스마트 컨트랙트에 있는 데이터들를 그대로 가져오는 것은 비교적 어렵지 않지만, 컨트랙트에 직접적으로 없는 데이터들을 복합적으로 사용해야하는 경우, 그 과정이 굉장히 복잡하기 때문에 블록체인에 있는 데이터를 효율적으로 제공해주는 것은 상당히 어려운 작업이라고 할 수 있다. 그렇다면, 더 그래프는 어떤 구조로 이루어져있기에 어려운 작업들을 비교적으로 효율화 할 수 있었을까?
1.2.2 A few concepts we need to know
우선 더 그래프의 구조와 참여자에 대해 알아보기 전에, 선제적으로 알아야 하는 개념들이 있다, GraphQL과 서브그래프(Subgraphs)가 바로 그것들이다:
GraphQL: GraphQL은 데이터 쿼리를 할 때 사용하는 프로그래밍 언어로 페이스북(현 메타)에서 만들었으며 REST(Representational State Tranfer) API에 비해서 훨씬 더 효율적인 쿼링 언어로 알려져있다. 해당 언어의 이름에 Graph가 들어가서 더 그래프에서만 사용되는 언어로 오해할 수 있지만 그렇지는 않고 비교적 신생 언어이나 페이스북에서 오픈소스화를 한 이후로 꾸준히 사용되고 있는 쿼리 언어라고 할 수 있겠다.
서브프래프(Subgraphs): 서브그래프는 더 그래프에서만 사용되는 개념으로, 블록체인에 있는 데이터들을 위해서 제작된 커스텀 API라고 할 수 있다. 쉽게 말해서 서브그래프는 더 그래프가 어떻게 데이터들을 모으고, 정리하고, 어떤 방식으로 데이터에 접근할지를 알려주는 시스템이라고 할 수 있다. 서브그래프는 아래와 같은 과정을 거쳑서 만들어지고, 사용된다:
우선 제일 처음 해야하는 것은 GraphCLI를 까는 것이다. GraphCLI는 개발자들이 서브그래프를 관리할 수 있도록 더 그래프에서 제공하는 커맨드 라인 툴이다.
그 다음엔 서브그래프를 초기 상태로 설정하고 프로젝트 구조를 생성한다(프로젝트 구조들은 Manifest File, Schema, Mapping Script 템플릿으로 이루어져있)
개발자들이 어떤 데이터를 필요로 하는지 정의한다. 이것을 Schema라고 하는데 Schema는 데이터의 타입을 정리하고 이들이 어떻게 연관되어있는지를 정리한 것이라고 볼 수 있다.
Schema를 정의하면, 그 다음엔 Manifest를 작성한다. Manifest는 블록체인에서 어떤 데이터를 인덱싱 해야하는지에 대한 일종에 지침이라고 볼 수 있다.
그 이후엔 Mapping Scripts를 작성한다. 이 스크립트들은 로우 데이터를 어떻게 Schema에서 정의한 대로 변환시킬 수 있을지를 표현한다고 볼 수 있다.
위의 세 가지가 다 준비가 되었다면 이들을 담은 서브 그래프가 더 그래프로 디플로이 된다.
더 그래프는(엄밀히 말해서 더 그래프에 있는 인덱서는) Schema와 Manifest, 그리고 Mapping Scripts를 활용하여 데이터를 인덱싱한다.
데이터가 정리되었다면, GraphQL을 통해서 쿼리잉 될 준비가 되었다는 뜻이다. 개발자는 이제 이 데이터를 쿼리해서 사용하면 된다.
이 개념들은 앞으로 더 그래프를 설명할 때 자주 등장하는 개념이기에 숙지하는 것이 좋다. 그럼 이제 본격적으로 더 그래프의 구조에 대해서 알아보자.
1.2.3 Structure of the Graph

우선 더 그래프 네트워크는 인덱서와 큐레이터 그리고 델리게이터로 구성이 되어있다. 이들은 모두 웹3 애플리케이션에게 데이터를 제공해주는데 기여하는 주체들이라고 할 수 있다. 그리고 이들이 인덱싱하고 쿼리해주는 데이터를 소비하는 개발자도 더 그래프의 일부라고 할 수 있다. 이들이 가진 각각의 역할을 한 번 살펴보자:
인덱서(indexer)
인덱서는 우리가 레이어1 네트워크에 대해서 이야기 할 때 나오는 벨리데이터 또는 노드의 역할과 동일한 역할을 수행한다고 볼 수 있다. 인덱서가 되기 위해서는 그래프 토큰(GRT)을 네트워크에 스테이킹 해야하며 인덱서의 기본 역할은 말 그대로 인덱싱과 쿼리 서비스를 제공하는 것이다. 레이어1 네트워크의 벨리데이터가 트랜잭션 수수료와 인플레이션을 보상으로 받아가듯, 인덱서 역시도 쿼리 수수료와 인덱싱 보상을 대가로 지급받는다. 또한, 레이어1의 벨리데이터가 악의적이면 스테이킹 된 토큰이 슬래싱 되는 것과 같이 더 그래프의 인덱서들도 만약 이들이 악의적인 정보를 제공한다면, 스테이킹 해놓은 GRT 토큰을 슬래싱 당하기 때문에 그래프 토큰의 스테이킹은 프로토콜 전체의 보안과도 밀접한 연관이 있다.
인덱서들이 모든 정보들을 다 인덱싱 하는 것은 아니고, 필자가 밑에서 후술할 큐레이터들이 시그널링을 준 서브그래프에 한해서만 인덱싱을 진행한다.
현재 더 그래프 네트워크에는 약 140개가 넘는 인덱서가 있고, 노드 숫자로 따지더라도 다른 블록체인들에 견주어 봤을 때 절대로 부족한 숫자가 아님을 알 수 있다.
델리게이터(Delegator)
델리게이터 역시 우리가 dPoS(Delegated Proof of Stake)시스템에서 토큰을 스테이킹하고 벨리데이터에게 위임하는 것과 같이, 더 그��프에서도 GRT토큰을 인덱서에게 위임하는 주체들을 일컫는다. PoS 블록체인에서 스테이커들이 ��트워크에서 발생한 수수료의 일부를 가져가는 것처럼, 더 그래프에서도 델리게이터는 인덱서가 받는 쿼리 비용의 일부를 보상으로 받는다(델리게이션을 할 때 0.5%의 세금과 28일의 언본딩 기간이 있으니 혹여나 GRT 토큰을 델리게이션 해줄 용의가 있다고 한다면 필자가 언급한 이 조건들을 자세히 알아보고 델리게이션 하기를 바란다).
큐레이터(Curator)
큐레이터는 말 그대로 인덱서들에게 알맞는 서브그래프를 추천해주는 역할이다. 더 그래프에선 큐레이터로 하여금 좋은 서브그래프를 추천하게 만들기 위해서 GCS(Graph Curation Shares)라는 토큰을 만들었다. 이 토큰은 큐레이터가 큐레이션한 서브그래프가 만들어내는 쿼리 수수료를 나눠주는 기능을 하는데, 더 좋은 퀄리티의 서브그래프가 더 많은 쿼리 비용을 만들어낼 것이기에 큐레이터는 좋은 서브그래프를 인덱서에게 시그널링 해주고, 해당 서브그래프가 만들어내는 쿼리 수수료의 일부를 나눠갖게 함으로써 큐레이터와 인덱서의 이해관계를 일치시킬 수 있다.
개발자(Developer)
위의 세 주체들은 공급자 관점에서의 참여자였다면, 개발자(Developer)는 수요 측면에서의 기여자라고 할 수 있다. 더 그래프의 주요 고객은 결국 데이터를 사용하는 개발자들이다. 서브그래프를 설명할 때도 이야기 했지만 결국 서브그래프를 만들어서 더 그래프 네트워크에 제출하는 주체 역시 개발자다.
1.2.4 더 그래프의 효율성
지금까지는 더 그래프를 이해하기 위해서 숙지해야하는 개념들과, 더 그래프 네트워크를 이루는 참여자들에 대해서 알아보았다면, 이제는 더 그래프가 어떤 부분에서 효율성을 추구했는지 알아보자.
우선, 더 그래프가 가지고 있는 서브그래프라는 개념은 데이터의 종류와 성격에 맞춰서 커스텀을 한 인덱싱 솔루션이기 때문에 나중에 쿼리를 할 때도 굉장히 효율적으로 사용 가능하게 설계되었다. 뿐만 아니라 쿼리잉을 할 때 사용하는 GraphQL 역시나 굉장히 효율적인 쿼리잉 언어기 때문에 쿼리잉을 훨씬 더 효율적으로 개선해준다(위에서 설명했던 것과 같이 REST API보다 훨씬 더 효율적인 쿼리 언어로 알려져 있다). 마지막으로 개발자들이 서브그래프를 더 효율적으로 관리할 수 있도록 더 그래프에서 만든 GraphCLI는 서브그래프를 쉽게 설치할 수 있게 해줄 수 있을 뿐만 아니라 이미 네트워크에 디플로이 된 서브그래프도 관리할 수 있도록 해주기 때문에 더 그래프는 비교적으로 어려운 블록체인 데이터 인덱싱과 쿼리잉도 빠르고 효율적으로 처리할 수 있다.
물론 여기서 끝이 아니다. 더 그래프는 인덱싱과 쿼리잉 환경을 지속적으로 개선하기 위해서 노력하고 있고, 이 노력의 결과물들이 Firehose 랑 Substreams과 같은 결과물들로 나오고 있기도 한데, 이 둘에 대해선 좀 더 자세히 후술하도록 하겠다.
1.2.5 Farcaster Frames as example(how the graph is being used)

Source: limone.eth
지금까지 필자가 설명했던 개념들을 좀 더 이해하기 쉽도록, 현재 많은 사람들이 사용하는 파캐스터를 예시로 들어볼까한다. 파캐스터의 가장 유명한 피처는 바로 애플리케이션을 SNS 포스팅에 엠베딩 할 수 있는 프레임(Frame)이라고 할 수 있다. 유저들은 프레임을 통해서 NFT를 민팅할 수도 있고, 게임을 즐길수도 있다. 그리고 결국 프레임들도 대부분의 경우 온 체인 애플리케이션을 웹상에서 엠베딩 하는 것이기 때문에 온체인 데이터가 필요하다. 이러한 경우 개발자들은 더 그래프가 이미 구축해놓은 서브 그래프를 이용해서 프레임에 필요한 데이터를 가져올 수 있다. 이더리움과 베이스의 데이터를 인덱싱 해놓은 NFT 서브그래프를 사용해서 NFT 브라우저를 만든 3070의 예시나 더 그래프를 활용하여 온 체인 이벤트 데이터를 가져다가 온체인 프로포절에 투표할 수 있는 프레임을 만든 limone의 예시만 보더라도,더 그래프를 활용해서 보다 쉽게 프레임을 구축할 수 있음을 알 수 있다. 현재 더 그래프는 파캐스터의 바운티 프로그램인 바운티캐스터에도 적극 참여하여 파캐스터 유저들이 더 그래프를 다양한 방법으로 사용하도록 장려하고 있다.

Source: the Graph x AI whitepaper
우리는 지금까지 더 그래프가 무엇을 하는 프로토콜인지, 어떻게 작동하는지, 그리고 참여 주체들이 누구인지에 대해 알아보았다. 그러나 처음에 언급했듯이, 이 아티클의 목적은 더 그래프 자체를 설명하는 것보다 (물론 이것도 중요하지만) 왜 더 그래프가 앞으로 중요한 인프라, 단순히 인덱서를 넘어서서 탈중앙 데이터 서비스 프로토콜이 될 것인지에 대해 다루는 데 있다. 따라서 이번 섹션에서는 필자가 위에서 짧게 언급했던 더 그래프를 주목해야 하는 두 가지 이유 중 첫 번째 이유인 AI와 블록체인의 결합, 그리고 더 그래프가 이 둘 사이에서 중요한 역할을 수행하는 이유에 대해 좀 더 자세히 다뤄보도록 하겠다.
AI를 제대로 활용하기 위해서 컴퓨팅 리소스만큼이나 필요한 것이 바로 데이터다. 데이터가 없이는 아무리 훌륭한 인공지능이라도 좋은 답변을 내놓을 수 없다. 결국 이들도 지능으로써 과거의 데이터를 학습하는 주체이기 때문이다. 이런 맥락에서 더 그래프가 지난 수년간 온 체인 데이터를 인덱싱 해온 기록은 매우 중요한 자산으로 다가온다. 만약 인공지능이 온 체인 데이터를 효율적으로 학습해야 한다면 더 그래프 네트워크에 있는 서브그래프들 만한 소스를 찾기는 어렵기 때문이다. 더불어서, 더 그래프가 구축해놓은 방대한 인덱서 인프라는 AI를 운영하기 위한 컴퓨팅 자원까지 마련해준다. 즉, 더 그래프는 AI를 운영할 수 있는 컴퓨팅 자원을 제공해줌과 동시에, 이들이 학습할 수 있는 방대한 자료를 제공해줌으로써, AI와 블록체인 두 기술의 핵심 인프라가 되려는 것이다. 만약 새로운 경쟁자가 뒤늦게 등장한다고 할지라도, 더 그래프가 쌓아놓은 방대한 데이터와 인덱서 네트워크가 구축한 해자를 무너트리기는 쉽지 않을 것이다.
그렇다면 더 그래프를 활용해서 우리는 구체적으로 어떠한 AI 서비스를 기대할 수 있을까? 필자가 봤을 땐, 큰 골자에서는 두 가지 서비스가 있을 것이다: 1) 추론 서비스(inference service)와 2) 에이전드 서비스(Agent Service)가 바로 그것들이다. 한번 각각의 서비스들을 자세히 살펴보자.
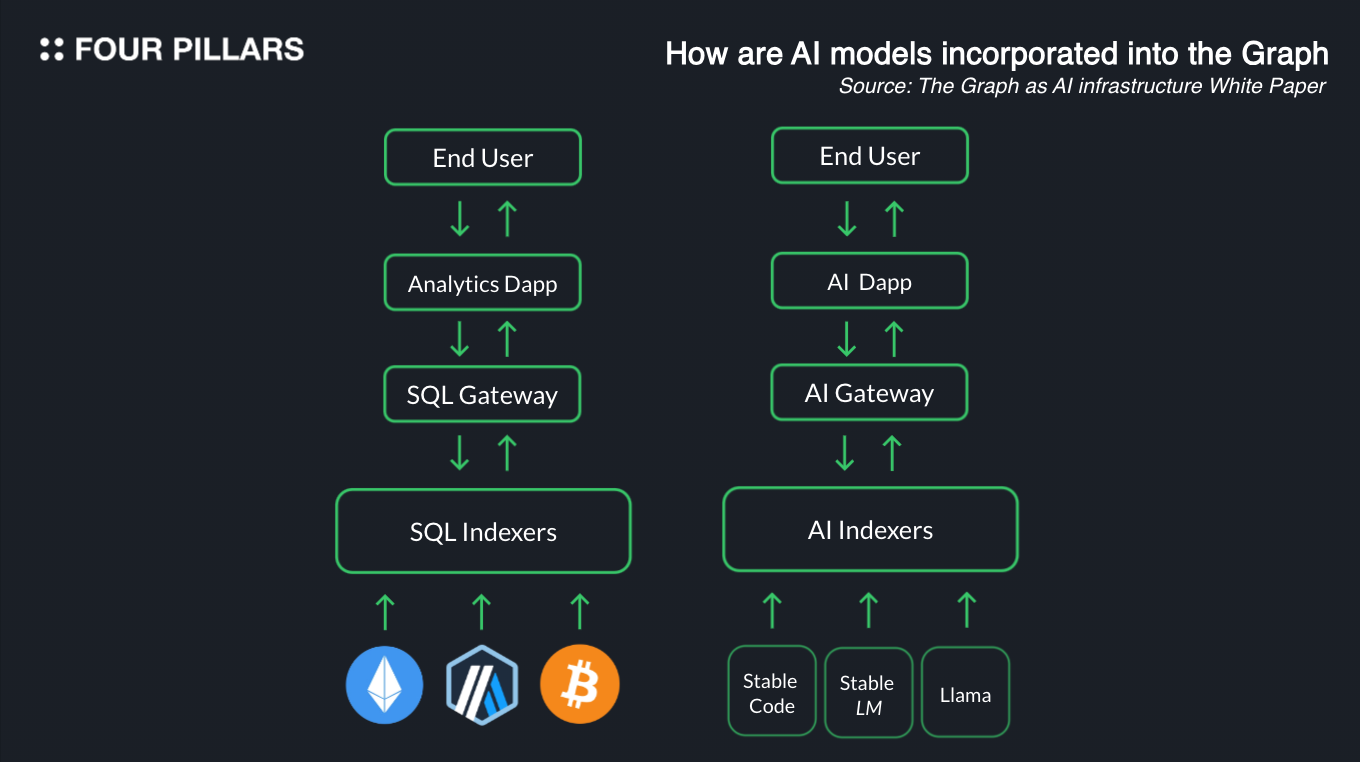
추론 서비스란 말 그대로 더 그래프 네트워크 위에 인공지능 모델을 호스트하는 것을 말한다. 개발자들은 자신들이 구축한 앱의 프론트에 ChatGPT와 같은 피처를 만들어서 유저들의 경험을 개선시킬 수 있을 것이다. 이러한 작업이 가능한 이유는 더 그래프 네트워크의 노드들인 인덱서들이 가지고 있는 컴퓨팅 자산을 활용할 수 있기 때문이다. 이러한 추론 서비스가 가능해진다는 것은 더 그래프가 이제는 단순히 인덱싱과 쿼리잉 인프라가 아니라, AI를 직접 호스팅하는 인프라로써의 진화를 꿰하고 있음을 의미한다. 더 그래프에 AI 모델을 호스팅하는 것은, 데이터 인덱싱/쿼리와 비슷한 과정을 거치는데, 그 과정은 아래와 같다:
유저들이 AI 디앱(dApp)의 프론트엔드와 상호작용한다.
AI 디앱들은 더 그래프의 AI 게이트웨이에 이들이 사용하고자 하는 추론 모델을 요청한다.
AI 게이트워이는 AI 디앱이 요청한 추론 모델를 제공해줄 수 있는 인덱서를 찾는다.
선택된 인덱서는 AI디앱이 요청한 모델을 업로드하고 추론하고, 추론 된 결과값을 게이트웨이에 전달하고 이에 대한 수수료를 받는다.
게이트웨이는 해당 데이터를 AI 디앱에 전달한다.
AI 디앱은 해당 데이터를 프론드엔드에 띄워서 보여주거나, 해당 데이터를 사용한다.
그렇다면, 왜 개발자들은 더 그래프를 활용하여 AI모델을 호스팅해야할까? 그 이유는 1) 다른 중앙화 서비스를 활용하면 그들의 정책에 따라 자신들의 모델을 제한할 수 밖에 없지만, 더 그래프의 경우엔 탈 중앙화 되어있기 때문에 그럴 염려를 할 필요가 없고 2)그렇다고 독자적으로 하드웨어를 운영하기엔 비용도 많이 들뿐더러 AI모델에 대한 전문적인 지식이 필요하기 때문에, 검열이 없으면서 개발자의 니즈에 맞는 모델을 쉽게 선택할 수 있는 오픈 마켓인 더 그래프가 비용이 최적화된 선택지이기 때문이다.
에이전트 서비스란, 말 그대로 제3자가 어렵고 복잡한 작업들을 대신 해주는 것을 이야기 한다. 에이전트 서비스는 단순히 데이터를 처리하는 작업만 하는 것이 아니라 자연어를 쿼리로 바꿔준다던지 하는 복잡한 태스크들도 수행할 수 있게 된다. 이미 더 그래프는 AgentC 라는 프로덕트를 통해 에이전트 서비스가 어떤 편의성을 제공해줄 수 있는지 소개한 바 있다.
2.3.1 AgentC as an example
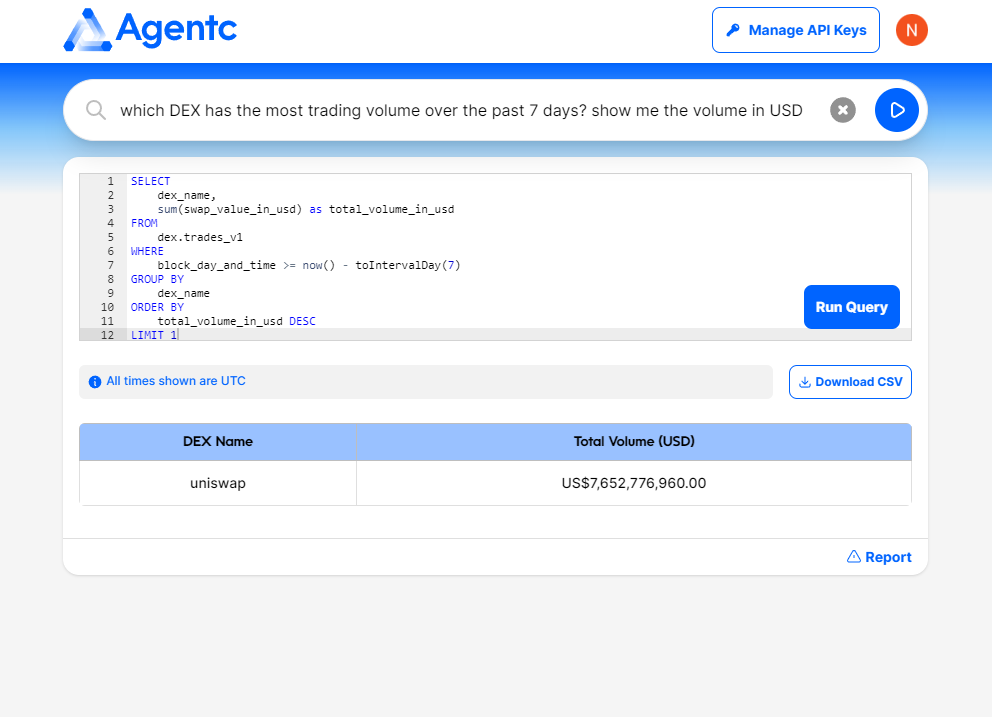
Soruce: AgentC
AgentC는 더 그래프에 있는 탈중앙 거래소에 대한 데이터들을 기반으로 만들어진 ChatGPT같은 툴이라고 볼 수 있다. AgentC는 필자와 같은 리서처들에게 굉장히 유용한 툴일 수 밖에 없는데, 그 이유는 온 체인 데이터를 보기 위해서 복잡하게 데이터를 분석하지 않아도 AgentC가 더 그래프의 데이터를 기반으로 내가 원하는 정보를 알려주기 때문이다. 위의 사진에서도 나와있듯 필자는 그냥 자연어로 어떤 탈 중앙 거래소가 지난 7일간 가장 많은 거래량을 소화해냈는지, 그리고 그 거래량이 얼마인지를 물어봤고, AgentC는 이를 직접 쿼리해서 거래소의 이름과 지난 7일간의 볼륨을 USD로 환산하여 알려줬다. 물론 아직까지 데모이기 때문에 데이터 표본 자체가 크진 않지만(AgentC는 지금 약 7개의 상위 DEX의 데이터만 학습한 상황이다). 더 그래프가 지원하는 모든 체인과 애플리케이션에 대한 데이터를 학습한다면, 필자와 같은 리서처에게 매우 좋은 분석 툴이 될 것이라고 생각한다.
이처럼, 더 그래프는 지난 4년여간의 시간동안 이더리움을 비롯한 다양한 체인들의 데이터를 인덱싱하고 쿼리잉 해왔기 때문에 그 인프라 위에서 정말 다양한 툴들을 개발할 수 있을 것이다. AgentC는 더 그래프의 데이터를 레버리지해서 AI를 결합한 하나의 사례이지만 확실한 것은 AI가 더 그래프를 이용하면 여태까지 불친절했던 온 체인 데이터가 매우 쉽게 쓰여지는 시대가 머지 않았다는 것이다.
이미 AI는 우리의 일상생활에 깊게 침투해있다. 그리고 AI는 블록체인 서비스들에도 깊게 침투해서 여태까지 유저들이 겪었던 UI 문제를 많은 부분에서 해결할 수 있을 것으로 사료된다. 만약, AI가 온 체인에서 다양하게 쓰일 미래가 자명하다면, 우리는 더 그래프에 대해서 좀 더 진지하게 받아들일 필요가 있다. 왜냐하면 1) AI 가 온 체인 데이터를 학습하고 접근하기 위해서는 더 그래프를 사용해야 하는 것도 맞지만 2) 더 그래프 자체적으로도 AI를 호스팅하는 인프라로써 발돋움하고 있기 때문이다. 현재는 AgentC 같은 서비스들이 데모로 나오고 있지만, 만약에 더 그래프 네트워크에 있는 모든 서브그레프의 데이터를 활용해서 AgentC를 만든다면 어떨까? 일단 다른 사람들은 몰라도, 리서치를 업으로 삼고 있는 필자의 입장에선 무조건 써야하는 서비스가 될 것이다. AI의 발전과 더 그래프가 여태까지 인덱싱 해왔던 방대한 데이터가 만나서 어떤 시너지를 낼 수 있을지 무척이나 기대가 되는 부분이다.
AI 시대에 더 그래프의 중요성은 어찌보면, 수요 사이드의 중요성이었다. 하지만 수요 사이드의 중요성 만큼이나, 공급 사이드에서도 더 그래프는 반드시 조명해봐야 하는 부분들이 있다. 특히 더 그래프 네트워크가 출시된지 3년이 넘었음에도 꾸준하게 지속 가능성을 보여주고 있다는 부분은, 토큰을 가지고 있는 모든 네트워크들이 한 번 씩 벤치마킹 해야하는 사례라고 생각한다. 더 그래프는 그러면 어떻게 지속 가능한 프로토콜을 만들어가고 있을까? 우선 첫 번째로 인위적인 수요를 만들지 않아도 필요한 서비스를 제공함으로써 시장의 꾸준한 수요를 창출했다는 부분이고, 두 번째로는 PMF(product market fit)를 찾기 힘든 시장에서 PMF를 찾고 꾸준히 발전시키고 있을 뿐만 아니라 고객 만족을 위해서 프로토콜의 퍼포먼스를 향상시키기 위한 다양한 이니셔티브를 전개하고 있다는 부분이다. 이 두 가지를 차례대로 한 번 살펴보자.
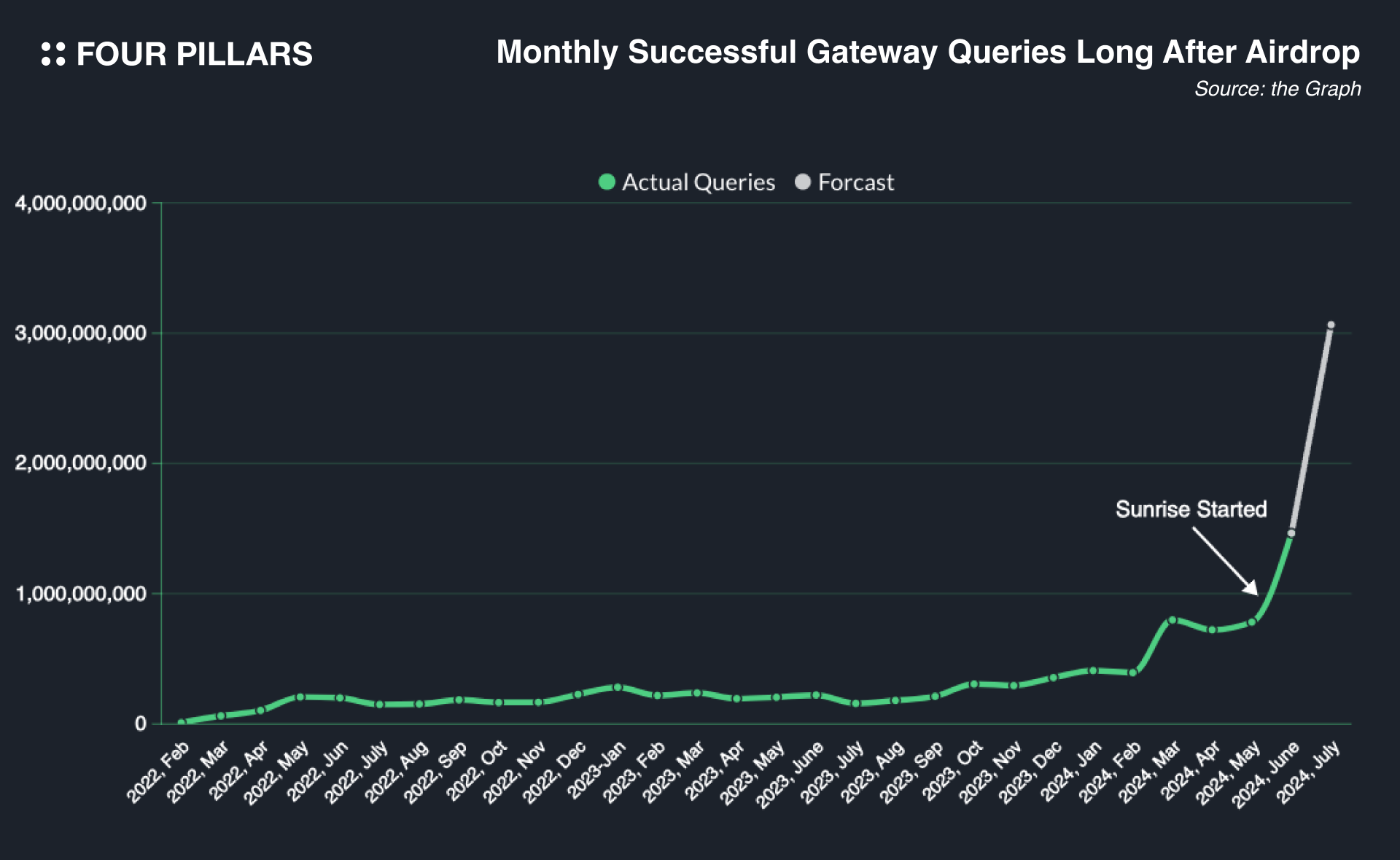
(위 그래프는 더 그래프에서 처리하는 쿼리의 수를 월간으로 정리해서 나타낸 것이다. 쿼리의 수가 갑자기 늘어난 이유는, 여태까지 더 그래프의 대부분 쿼리들이 중앙화 되어있는 주체들에 의해서 처리되었다가, Sunrise 이후로탈 중앙화된 네트워크가 처리하기 시작했기 때문이다. Sunrise는 그것을 탈 중앙화하는 이니셔티브로, Sunrise 이후에 쿼리량이 폭등하는 것을 볼 수 있다. 회색으로 표기한 부분은 앞으로 처리할 쿼리를 예측한 것으로, 7월이 다 끝나지 않은 시점인 지금 7월의 쿼리까지 표기하기 위해서 7월1일부터 지금까지 일간 평균 쿼리양을 기준으로 월간 쿼리양을 계산해서 표기하였다.)
필자가 서론에서도 잠깐 언급했듯, 지금까지 크립토에서 에어드랍은 신규 프로젝트가 런칭함에 있어서 필수 불가결한 도구로 여겨져왔다. 프로젝트의 입장에서 토큰을 발행하여 유저들에게 보상으로 나눠주는 행위는 마케팅 비용을 집행하지 않고도 네트워크 효과를 일으킬 수 있는 좋은 도구였으며, 초기 유저들과 이해관계를 일치시켜서 이들로 하여금 네트워크에 지속적인 기여를 할 수 있게 유도할 수 있다는 장점이 있었다.
포인트도 에어드랍과 비슷한 역할을 해왔다. 다만, 포인트는 토큰이 아니라는 점에서 토큰에 비해 유연한 적용이 가능하다는 측면이 장점으로 작용했고, 포인트가 정확히 몇 개의 토큰으로 교환될 것이라는 것이 정해지지 않은 상태에서는 유저들의 기대심리를 모으기에도 좋은 툴이었다.
하지만 어떤 것이든 과하면 문제가 생기듯, 에어드랍과 포인트 시스템의 목적이 상당부분 희석되기 시작했다. 원래는 네트워크 초기 참여자들을 보상하고, 이들과 이해관계를 일치시키기 위해서 시작된 것이지만, 시간이 지나서 점점 많은 사람들이 에어드랍과 포인트만을 위한 활동을 전개하고 에어드랍이 끝나면 프로토콜의 사용량도 줄어드는 형태가 지속되다보니 에어드랍과 포인트 시스템이 얼마나 지속 가능한지에 대한 다양한 회의론들이 나오기 시작했다.
결국 에어드랍으로 초기 유저들을 모객하는 것도 중요할 수 있지만, 가장 중요한 것은 해당 프로젝트가 정말로 필요한 것을 제공해주는지에 대한 부분, 그리고 정말 이들이 해결하고자 하는 문제가 명확한지에 대한 부분이다. 에어드랍과 포인트 같은 인센티브 시스템은, 애초에 프로덕트가 좋은데 아직 알려지지 않아서 마케팅과 네트워킹이 필요한 프로젝트의 경우에 굉장히 좋은 효과를 발휘할 수 있다.
그렇다면 좋은 프로덕트란 무엇일까? 문제를 해결할 수 있는 프로덕트라고 생각한다. 그런 의미에서, 더 그래프의 경우 좋은 예시가 된다고 생각한다.
물론 더 그래프도 초기 기여자들에게 토큰으로 보상을 해주었다. 그럼에도 놀라운 점은, 더 그래프를 통해 데이터를 쿼리하는 양 자체는 에어드랍 이후에 꾸준하게 더 늘었다는 부분이다. 이는 프로토콜에 대한 수요가 에어드랍을 통해 인위적으로 만들어지지 않았다는 이야기고, 에어드랍 자체도 무의미한 활동에 대한 보상의 개념이 아닌, 초기 참여자들이 기여한 것에 대한 보상의 개념이었다.
더 그래프가 에어드랍 이후로도 꾸준한 수요를 창출할 수 있었던 이유는 간단하다: 데이터 인덱싱과 쿼리잉 이라는, 정말로 시장이 필요한 서비스를 제공해줬기 떄문이다.
에어드랍과 포인트 시스템으로 이야기가 많은 요즘, 더 그래프의 행보에 대해서 한 번 생각해볼 가치가 있다. 에어드랍이 나쁘다는 것이 아니라, 기존에 존재하는 서비스를 그대로 복사&붙혀넣기 후 유저들을 불러모으기 위해서 에어드랍을 감행하는 행위들은 지탄받아야 한다. 에어드랍 자체는 좋은 마케팅 수단이지만, 프로덕트 자체가 문제를 해결할 수 없다면 에어드랍은 아무런 의미가 없기 때문이다.
3.1.1 Expanding outside Ethereum
원래 더 그래프는 이더리움에서 시작했지만, 지금은 이더리움을 제외하고도 수많은 레이어1들의 데이터를 인덱싱하고 쿼리잉 해주고 있다. 현재 더 그래프가 지원하는 네트워크는 이더리움을 제외하고도 아비트럼, 폴리곤, 아발란체, 솔라나, 바이낸스 스마트 체인, 니어 프로토콜, 셀로, 하모니, 알위브, 코스모스, 오스모시스, zkSync, 베이스 같이 현재 웹3를 대표하는 체인들은 거의 전부 지원하고 있고, 현재 더 그래프는 3년만에 50개 이상의 블록체인들을 지원하게 되었다. 더 그래프의 특성상 당연히 더 많은 체인들을 지원할수록 더 많은 쿼리 요청이 들어오고, 더 그래프의 사용량은 더 늘어나게 될 것이라는 점에서 더 그래프의 미래는 긍정적이라고 할 수 있겠다.
더 그래프는 프로토콜이기 때문에 비즈니스 모델을 이해하기 위해선 토크노믹스를 이해해야한다. 더 그래프의 토큰인 GRT토큰은 필자가 위에서 언급한 더 그래프 네트워크의 구성원(인덱서, 큐레이터, 개발자, 델리게이터)간에 가치를 주고받는 수단으로 쓰인다. 이 네 구성원들 중에서 GRT를 받는 주체는 인덱서, 큐레이터, 델리게이터이고 GRT를 내는 주체는 개발자다. 더 그래프의 비즈니스는 매우 간단하다. 더 많은 개발자가 더 많은 쿼리 비용을 지불하면 네트워크는 더 많은 수익을 발생시키는 모델이다. 물론 현재는 호스트 서비스(중앙화 된 서비스)를 제공하기 때문에 개발자들이 네트워크에 지불하는 비용이 적지만(거의 0에 수렴), Sunrise 이니셔티브 이후에는 더 그래프 네트워크 자체가 완전히 탈 중앙화 될 것이기 때문에 개발자가 내야하는 비용은 늘어날 것으로 전망되고 이는 곧 네트워크의 수익 증가로 이어질 것으로 예상된다. 그렇다면 선라이즈는 무엇이고, 구체적으로 어떤 과정을 거쳐서 네트워크를 탈 중앙화 시키는 것일까?
선라이즈는 모든 서브그래프가 이젠 호스팅 서비스가 아닌 탈 중앙화 되어있는 네트워크에 완벽하게 이전한 단계라고 볼 수 있다. 즉, 선라이즈 시점부터는 모든 서브그래프가 완전히 탈 중앙화 되어있는 환경에 놓여진다고 볼 수 있다. 그리고 필자가 아티클을 작성한 시점으로 선라이즈 이니셔티브를 통해서, 서브그래프를 탈 중앙화 되어있는 네트워크에 성공적으로 이전하였다. 현재 약 6,000개가 넘는 서브그래프가 탈중앙 네트워크에 성공적으로 이전했다.
Sunrise of profitable future
선라이즈 이니셔티브 이후에 더 그래프 자체의 수익성은 더 좋아질 예정이다(그리고 실제로 선라이즈 이니셔티브 이후로 지난 30일간 데이터 서비스 수수료가 전년대비 376% 증가하는등 벌써부터 수익성에 청신호를 킨 모습이다). 왜냐하면 호스팅 서비스에선 사실상 네트워크가 받는 수수료는 0에 가까웠기 때문이다. 네트워크가 하루에만 약 십억개 이상의 쿼리를 처리하는 상황에서, 온전하게 탈 중앙화 되어있는 네트워크로 넘어간다는 것은 더 그래프 네트워크의 수익성이 올라가는 것 뿐만 아니라 더 그래프 생태계의 기축통화인 GRT 토큰의 수요도 점진적으로 상승할 것이라는 이야기다. 이는 전체 생태계에 아주 좋은 영향을 줄 것이다.
더 그래프가 인상깊은 이유는, 네트워크는 점진적으로 탈 중앙화 시키면서도 인덱싱 기술은 지속적으로 발전시켜서 탈 중앙화와 퍼포먼스를 둘 다 잡으려고 한다는 것이다. 퍼포먼스를 향상시키기 위한 대표적인 기술들이 바로 파이어호스(Firehose)와 서브스트림(Substreams)이다.
3.3.1 Firehose

Source: the Graph Doc
파이어호스는 스트리밍 패스트라는, 더 그래프의 코어 개발자들이 개발한 기술이며, 이 기술을 사용하면 블록체인 데이터를 굉장히 효율적이고 빠르게 처리할 수 있다. 파이어호스는 데이터를 실시간으로 가져올 수 있기(데이터를 파이어호스가 적용된 블록체인 노드들로부터 직접적으로 가져온다) 때문에 레이턴시를 낮추고 실시간으로 블록체인 데이터에 접근해서 처리할 수 있다. 또한 Go 프로그래밍 언어로 쓰여졌기 때문에 병렬 컴퓨팅도 지원하기 때문에 더 높은 퍼포먼스를 낼 수 있다. 파이어호스를 통해 서브그래프는 더 효율적으로 데이터를 전달받아 여태까지는 경험하지 않았던 데이터 처리 속도를 보여줄 것이다.
3.3.2 Substreams

Source: the Graph doc
파이어호스는 데이터를 저장하고 불러오는 퍼포먼스에 초점을 맞췄다면, 서브스트림은 해당 데이터를 처리하면서 다양한 생태계간의 호환하는 것에 초점을 맞췄다고 볼 수 있다. 즉, 서브스트림을 사용하면 다양한 블록체인들로부터 데이터를 가져다가, 러스트 함수(Rust Fuctions)를 활용해 데이터들을 가공하여 어디든 해당 데이터를 보낼 수 있다.
더 그래프는 이 두 기술을 적극적으로 활용하여, 어려운 블록체인 데이터 익덱싱과 쿼리잉을 훨씬 더 효율적으로 빠르게 만들어서 더 많은 애플리케이션이 더 그래프를 사용하게 만드는 것이 목적이다. 단순히 퍼스트 무버로써 가지는 해자에서 만족하지 않고, 서비스를 더 강화하여 데이터 인프라로써 그 입지를 공고하게 하려는 것이다.
블록체인 시장은 특히나 “필요한 것” 보다 “그럴싸해 보이는 것”에 더 많은 집중을 하는 경향이 있다. 프로덕트가 다루는 문제가 정말로 풀어야 하는 문제일지, 또 그 프로덕트가 제공하는 솔루션이 정말로 해당 문제를 해결할 수 있을지 불문명하지만 단순히 그 프로덕트가 다루는 문제가 이 시장의 하이프를 탔다는 이유만으로 높은 가치와 기대를 끌어모으는 것이 일반적인 모습이다.
하지만 더 그래프는 수년간 같은 문제를 인식해왔고, 해결하고자 노력했으며, 그 문제들은 비교적으로 명확하고 해결이 필요한 문제들이었다. 우리는 어떤 프로토콜의 중요성을 평가할 때, 그 프로토콜이 사라지면 이 시장에 어떤 영향을 줄지 상상해보고는 한다. 만약 더 그래프가 당장 사라졌다고 생각해보자, 아마 지금도 하루에 수십만개의 쿼리를 보내는 애플리케이션들은 먹통이 되고 유저들은 불편함을 겪을 것이다. 우리는 알게 모르게 더 그래프가 제공하는 서비스를 사용하면서 편의를 누리고 있는 것이다. 그런점에서 더 그래프에 대해서는 한 번 쯔음 공부해볼 필요가 있다. 그리고 이러한 프로토콜이 지속적인 관심을 받아야 시장은 “그럴싸한 하이프”가 아니라 “시장이 정말로 해결해야하는 문제”에 집중할 수 있다.
이제 더 그래프는 단순히 인덱싱 프로토콜이 아닌, 종합 데이터 서비스 프로토콜로 거듭나고자 한다. 특히 AI 와 블록체인의 결합의 가능성이 가시적으로 눈에 보이는 상황에서 더 그래프는 이 두 기술의 가장 핵심 인프라가 되고자 한다. 추가적으로, 더 그래프는 이제 본격적으로 완전히 탈 중앙화 되어있는 데이터 프로토콜로 거듭난다. 이 소식은 단순히 탈 중앙성 측면에서 중요한 것 뿐만 아니라 앞으로 GRT 토큰이 더 그래프 생태계 내에서 갖는 중요성이 얼마나 중요해질 수 있는지를 보여주는 이벤트라고 생각한다.
더 그래프 네트워크가 나온지 이제 3년이 지났지만, 더 그래프는 이제 본격적으로 시작이라고 본다. 지난 3년간은 더 나은 데이터 서비스가 되기 위한 준비운동 기간이었고, 이제야 본격적으로 온전히 탈 중앙화 되어있는 데이터 서비스 인프라로 자리매김하고자 한다. 온 체인 데이터가 그 어느때보다도 중요해지는 시점에서, 더 그래프의 성장이 매우 기대되는 부분이다.