
“트랜잭션 병렬처리”는 지난 1년간 블록체인 업계를 달궜던 핵심 키워드중에 하나였다. 하지만 트랜잭션 병렬처리가 제대로 구현되기 위해서는 다양한 분야에서의 혁신이 필요하고, 이들중에서 가장 중요한 것이 바로 블록체인 데이터 베이스의 개선이라고 할 수 있다.
물론 EVM 병렬처리의 선두주자 중 하나인 세이도 이 사실을 알고 있었고, 작년부터 데이터 베이스 최적화에 대한 지속적인 고민을 해왔다. 그리고 그 고민의 결과물이 바로 세이 DB다.
세이 DB는 기존의 단일 데이터 베이스 구조를 모듈러한 구조로 바꿔서 두 레이어로 나누고, 불필요한 메타 데이터를 없앴을 뿐만 아니라, 스테이트 접근을 효율화하여 데이터 베이스 레벨에서 발생하는 비효율을 없애고 전체적인 블록체인의 성능을 향상시켰다. 이러한 세이의 접근은, 트랜잭션 병렬처리를 추구하는 블록체인들 뿐만 아니라 블록체인의 전반적인 효율화를 꿰하는 빌더들에게도 좋은 사례가 될 것이다.
2023년과 2024년 블록체인 시장의 사이클을 뜨겁게 달궜던 키워드들은 꽤 많다. 밈코인(meme coin), 파캐스터(Farcaster), 리스테이킹(restaking)등이 바로 그것들이다. 하지만 수많은 키워드들 중에 필자가 기술적으로 가장 흥미롭게 봤던 것은 바로 “트랜잭션 병렬처리(Transaction Parallel Execution)”였다. 시장에서는 EVM 병렬처리로 알려져 있지만, 필자가 보기엔 EVM 자체보다는, 트랜잭션을 병렬처리하여 블록체인의 성능을 개선하는 것이 더 근본적으로 중요한 부분이라고 생각했다.
여러분들의 경우엔 “트랜잭션 병렬처리”하면, 어떤 체인들이 떠오르실지 모르겠지만, 필자의 머리속에서 가장 먼저 떠오르는 체인은 바로 세이 블록체인(Sei Blockchain)이다. 물론, 이들이 트랜잭션 병렬처리라는 개념을 가장 처음 소개했던 블록체인은 아니나, 적어도 이 시장에서 트랜잭션 병렬처리라는 키워드를 뜨겁게 달궜던 플레이어라는 점에서 그 의미가 깊다. 그리고 어찌되었건, 세이 네트워크가 지금 이 글을 쓰는 시점을 기준으로 봤을 때 최초로 EVM 병렬처리가 가능한 레이어1 블록체인이 되었다. 왜냐하면 이들은 이미 EVM 병렬처리를 지원하기 위한 거버넌스 프로포절을 통과시켰기 때문이다.
세이 V2에 대한 거버넌스 프로포절이 통과되었다는 것은, 실질적으로 적용되기 어렵다고 평가받던 트랜잭션 병렬처리가 이제는 적용 가능한 단계까지 왔다는 점에서 의의가 있다. 그렇다면 트랜잭션 병렬처리가 어떠한 이유에서 적용되기가 어려웠을까? 필자가 살펴본 결과, 여태까지 트랜잭션 병렬처리를 구현하기 어려웠던 이유들은 꽤나 다양했다. 하나하나 살펴보자면, 우선, 같은 스테이트를 건드리는 트랜잭션들(같은 계정의 같은 잔고를 건드리는 트랜잭션간의 충돌)간에 충돌이 발생할 수 있는 여지가 크고, 트랜잭션들의 순서를 매길때도 복잡성이 늘어나는데다, 무엇보다 실행 레이어에서 트랜잭션을 병렬처리 하더라도 데이터 베이스 레벨에서의 최적화가 일어나지 않으면 확장성을 드라마틱하게 개선하기 어렵다는 부분들이 트랜잭션 병렬처리가 실제로 적용되는데에 있어서 많은 어려움을 가져왔다.
실제로 세이의 코파운더이자 CTO인 Jayendra는 여러 매체를 통해 해당 문제점(데이터 베이스 레벨에서의 최적화)을 지속적으로 지적해왔다. EVM 병렬처리, 더 나아가, 트랜잭션 병렬처리를 단순히 블록체인의 “실행”레벨에서의 최적화라고 생각한다면, 블록체인은 드라마틱한 확장성 개선을 이뤄낼 수 없다. 해서, 병렬처리를 통한 블록체인 성능 향상을 논하기 위해선, 데이터 베이스 레벨에서의 최적화가 어떻게 이루어지고 있는지에 대한 부분이 반드시 논의되어야 한다.
해서, 오늘은 세이 블록체인이 어떤 방식으로 데이터 베이스를 최적화하고 있는지에 대한 이야기를 해보려고 한다. 참고로 데이터 베이스 최적화의 문제는 비단 병렬처리를 지원하는 블록체인들만의 문제는 아니고, 수많은 트랜잭션들을 처리해야하는 모든 고성능 블록체인들이 마주하고 있는 문제이기 때문에, 독자들은 이 글을 통해 세이 V2에 대해 조금 더 자세히 알아가고, 고성능 블록체인을 설계하는 사람들은 고성능 블록체인의 데이터 베이스를 설계함에 있어서 참고할만한 지식을 얻어갔으면 좋겠다.
스토리지의 문제를 이야기하기 이전에, 우리는 스테이트(State)가 무엇인지에 대한 정릐를 할 필요가 있다. 블록체인에서 스테이트란 무엇일까? 스테이트란, 블록체인 내에 있는 모든 계정들에 대한 정보(계정들 그 자체에 대한 정보, 계정들의 잔고, 컨트랙트 코드등에 대한 정보)를 의미한다고 할 수 있다. 해서, 블록체인에서 트랜잭션이 발생하면 특정 스테이트에 영향을 줄 수 밖에 없다. 예를 들어서 A라는 사람이 B라는 사람에게 Sei 토큰을 전송한다고 하면, A와 B의 잔고는 변경되어야 한다. 이게 바로 스테이트가 변경된다는 것의 의미다. 스테이트가 변경되면 스테이트는 어떤 영향을 받을까? 보통 스테이트가 변경되면 스테이트가 커지지 않는다고 생각하지만 사실은 스테이트만 변경하는 트랜잭션의 경우에도 블록체인의 히스토리에 트랜잭션 레코드(밑에서 후술하겠으나, 이러한 종류의 데이터를 과거 스테이트(historical state라고 한다))가 남기 때문에 미비하지만 스테이트가 커진다고 볼 수 있다. 즉, 온 체인에서 일어나는 트랜잭션들은 전부 스테이트가 커지는데 기여하고 있다고 볼 수 있는 것이다.
필자가 위에서 설명했듯, 온 체인에서 일어나는 트랜잭션들이 스테이트 성장에 기여하고 있다면, 세이같이 빠른 블록체인의 스테이트는 타 블록체인에 비해서, 주어진 시간동안 처리하는 트랜잭션이 많을 것이기 때문에, 그 스테이트도 매우 빠르게 성장할 것이다. 만약, 여기에 한 술 더 떠서, 트랜잭션 병렬처리까지 지원한다고 하면 그 스테이트는 더욱더 빠른 속도로 성장할 것이고 이는 아래와 같은 문제들을 야기하게 된다:
노드 운영 비용의 증가: 풀노드들은 블록체인 스테이트의 전체를 저장해야하기 때문에, 스토리지 비용이 늘어나고 이는 결국 노드들로 하여금 해당 블록체인에 노드를 운영하는 것을 어렵게 만든다. 이는 중앙화라는 결과를 낳을 수도 있다(풀 노드를 띄우기 위한 진입장벽이 높아지기 때문에).
블록체인의 퍼포먼스 저하: 스테이트의 크기가 커지면 노느들이 트랜잭션을 처리하고 검증하는데에 걸리는 시간도 늘어남을 의미한다(블록체인의 상태를 변경하는 트랜잭션들이 발생할 때마다 노드들은 이와 관련된 스테이트 값들을 읽고 업데이트 해야하는데 스테이트가 성장할수록 접근해야 하는 데이터가 많아지고, 변경해야하는 스테이트 값들도 많아질 것이기 때문에). 결과적으로 이는 블록체인 자체의 속도 저하 문제로 이어진다.
노드간에 싱크 문제: 블록체인은 결국 여러 노드들간에 장부를 공유하고, 유효한 장부들을 꾸준히 서로간에 싱크하는 것이 전부라고 봐도 과언이 아니다. 그런데 스테이트가 비대해지면, 새로운 노드가 참여하는 것도 굉장히 버겁고(새로운 노드가 메인넷을 이미 런칭하고 운영중인 체인에 참여하기 위해선, 해당 체인의 전체 렛저를 다 다운로드 받아야 한다. 이를 위해서 체인들마다 “스냅샷”이라는 것을 찍는데, 스냅샷은 특정 지점에, 체인에 대한 전체 기록을 저장해두고 새로운 노드가 들어올 때 마다 싱크를 맞추는데에 사용한다. 하지만 체인이 비대해지면 스냅샷 자체를 찍는데에도 오랜 시간이 걸리고, 그 시간동안 블록체인은 계속해서 새로운 트랜잭션과 데이터를 추가할 것이기에 ���기서 생기는 괴리감으로 인해 새로운 노드로 하여금 싱크를 어렵게 만드��� 경우도 있다) 혹시나 싱크에 뒤쳐진 노드가 있다면 놓쳐버린 싱크를 다시 맞추는데에도 많은 시간과 비용이 들 것이다. 이는 블록체인의 성능 저하뿐만 아니라, 새로운 노드들이 참여하는 것도 어렵게 만들기 때문에 중앙화 문제 역시 야기할 수 있다.
이렇게 블록체인의 스테이트가 비대해져서 발생하는 문제를, 스테이트 블롯(State Bloat)이라고 부른다. 만약 DB의 개선 없이 단순 실행 레이어서의 트랜잭션 병렬처리를 이뤄낸다고 한다면, 스테이트는 더 비대해질 것이고 이는 결국 필자가 위에서 언급했던 다양한 문제들을 야기하게 될 것이다. 그리고 이러한 문제들은 결과적으로 트랜잭션 병렬처리를 통해서 얻고자 했던 것들을 달성할 수 없게 만든다. 물론 필자가 언급했듯, 세이는 해당 문제에 대해서 처음부터 인식하고 있었고, 그 인식의 결과물이 세이 DB인 것인데, 그렇다면 세이 DB는 어떤 것에 포커스를 맞춰서 데이터 베이스를 설계했으며, 어느정도까지 데이터 베이스를 개선했을까?

세이 V1은 기존의 Immutable Adelson-Velsky and Landis(IAVL, 코스모스 SDK에서 스테이트를 저장하기 위한 자료구조이며 이더리움에선 비슷한 개념으로 MPT(Merkle Patricia Trie)를 사용한다) 트리 데이터 구조로 이루어진 바닐라 데이터베이스 구조를 사용했다. 하지만 이러한 구조는 여러 방면에서 비효율적이었는데 우선 1) 각각의 노드에 수많은 메타데이터를 저장하는 구조인데다 2)트리 안에서 균형을 유지해야 하기 때문에 디스크에 여러번 접근해야 하고, 이는 메모리 접근을 더 느리게 만든다. 마지막으로 3) 의도한 데이터의 양보다 더 많은 데이터를 저장하는 비효율도 생긴다. 그래서 세이는 하나의 데이터 베이스에 모든 것을 저장하는 것이 아니라 데이터 베이스를 두 가지 레이어로 나눠서 모듈러하게 가져가는 것이 골자인 Sei DB를 발표하였다.
그런데 왜 두 가지 레이어로 나누는 것일까? 그 이유는 스테이트의 종류 역시 과거의 스테이트(historical state)와 활성 스테이트(active state)로 나뉘기 때문이다. 잠깐, 그렇다면 이 두 종류의 스테이트는 각각 무엇을 의미하는지 알아야 좀 더 세이 DB를 잘 이해하지 않을까? 그래서 필자는 이 두 가지 스테이트의 정의를 아래와 같이 하였다:
과거 스테이트(Historical State)
과거 스테이트는 말 그대로 현재 블록체인이 가진 가장 최신 블록 높이 이전에 기록된 모든 스테이트들을 일컫는 말이다. 즉, 지금 처리중인 블록을 제외한 과거에 있는 모든 블록체인의 기록을 담고 있는 스테이트를 과거 스테이트라고 부른다. (과거에 유저들이 가지고 있던 잔고 기록들은 전부 과거 스테이트에 해당된다)
활성 스테이트(Active State)
활성 스테이트는 가장 최신 블록 높이에 있는 정보들과 관련된 스테이트를 일컫는다. 좀 더 쉽게 말하면 블록체인에 기록되어있는 가장 최신의 정보들이라고 볼 수 있다. 예컨데, 현재 유저들의 잔고 상태들도 활성 스테이트의 일부이다.
이 둘의 정의만 보더라도, 과거 스테이트와 활성 스테이트는 엄연히 다른 정보들을 담고 있고, 과거 스테이트가 활성 스테이트보다 훨씬 무겁다는 것을 알 수 있다. 해서, 세이는 이 두 종류의 다른 스테이트를 다른 방식으로 다뤄서 데이터 베이스를 최적화 하려는 것이다.
세이 DB는 1) 스테이트 커밋 레이어(state commitment layer)와 2) 스테이트 저장 레이어(state storage layer)로 나뉘게 되는데, 각각 레이어들의 역할과 이들이 어떻게 상호작용 하는지를 한 번 살펴보자.
스테이트 커밋 레이어는, 세이 블록체인의 활성 스테이트(active state) 영역을 관리하는 레이어다. 스테이트 커밋 레이어에서 가장 중요한 부분은 바로 Memory-Mapped IAVL Tree(이하 MemIAVL)라고 할 수 있는데 이는 기존에 코스모스 SDK에서 사용하던 IAVL트리를 변경한(왜 변형했는지는 위에서 서술하였다) 형태의 트리로, 스테이트 접근에 굉장히 최적화 되어있는 트리라고 볼 수 있다. 그렇다면 MemIAVL은 왜 스테이트 접근에 용이할까? 이를 이해하기 위해선 세이에서 사용한 메모리 매핑(Memory Mapping)에 대해서 이해할 필요가 있다. 보통의 경우, 우리가 파일을 처리할때, 파일 디스크립터를 사용하거나 파일 구조체 포인터를 이용하여 이들에게 접근하게 된다. 하지만 이러한 방법들은 입출력을 위해서 반드시 버퍼를 거쳐야 한다는 단점이 있다. 그래서 나오게 된 것이 메모리 매핑(mmap())이다. 메모리 매핑은, 파일을 프로세스의 가상 주소 공간으로 매핑해서, 매핑된 데이터는 read나 write 함수를 사용하지 않고도 데이터를 읽거나 쓸 수 있게 된다.
그렇다면, MemIAVL을 사용했을 때 스테이트 접근 속도는 얼마나 빨라질까? 세이에 의하면 MemIAVL은 스테이트 접근을 수백 나노초(hundreds of nanoseconds)단위로 가능하게 된다(이는 스테이트를 읽는데 걸리는 시간을 기준으로는 10배 빠른 속도이며, 스테이트를 쓰는데 걸리는 시간을 기준으로는 최대 287배가 빠른 속도이다).
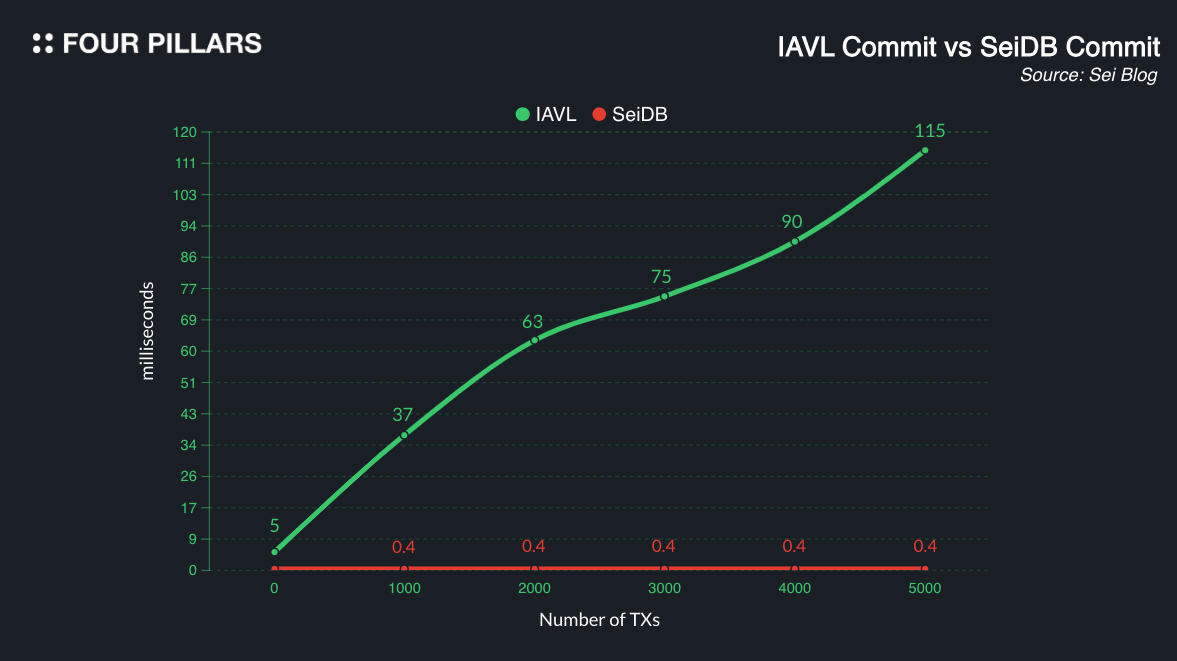
(위 그래프는 스테이트 커밋, 즉 스테이트에 정보를 쓰는 시간을 기준으로 비교한 그래프이며, 해당 지표는 세이 DB와 비동기 커밋(Asynchronous commit)이 합쳐져서 낸 결과물이다)
좀 더 쉬운 이해를 위해 MemIAVL을 적용했다고 가정하고, 트랜잭션이 블록체인에 반영되는 전반적인 라이프 사이클을 그려보자:
트랜잭션이 발생한다(MemIAVL에서 스테이트를 읽는다): 트랜잭션이 실행되고 스테이트가 변경된다(토큰을 전송하는 것이던, 스마트 컨트랙트의 상태를 변경하는 것이던).
변경된 스테이트에 대한 정보들이 MemIAVL에 먼저 저장되고, 활성 스테이트가 변경된다. 그리고 이걸 기반으로 스테이트 루트값이 다시 계산된다.
새로 계산된 스테이트 루트값이 블록 헤더에 포함된다. 이로써 트랜잭션이 성공적으로 블록체인에 반영된다.
저장되기 전에 write-ahead log(WAL)에 기록된다.이러한 작업을 하는 이유는, 변경된 스테이트에 대한 정보들이 적용되기 이전에 한 번 저장해줌으로써, 만약 시스템이 멈추더라도 변경된 정보들이 복원될 수 있도록 하기 위함이다(만약 노드가 멈춰서 복구를 해야하는 경우에는 가장 최근에 찍힌 스냅샷과 함께, WAL에 저장된 정보들을 적용하여 복구할 수 있다).
이러한 변화는 본질적으로 CPU와 메모리 사용량을 줄이게 되고, 이로인해 세이는 결과적으로 높은 하드웨어 사양을 요구하지 않고도 굉장히 빠른 블록체인을 구축할 수 있게 된다.
스테이트 커밋 레이어가 현재에 가장 중요한 활성 스테이트를 관장하는 레이어라면, 스테이트 스토리지 레이어는 활성 스테이트 이전에 있는 모든 기록들(Historial State)을 관리하는 레이어라고 볼 수 있다. 세이 v2의 스테이트 스토리지 레이어엔 세 가지 중요한 부분들이 있는데 이들을 각각 살펴보도록 하자:
2.2.1 Raw Key-Value Storage
블록체인을 공부하신 분이라면, 키값쌍(Key-value pair)에 대해서 들어보셨을 것이다. 키값쌍은 데이터 저장 구조로, 여기서 키는 고유한 식별자(unique identifier)를 의미하고, 값은 이것과 연관된 데이터들을 의미한다. 이해를 돕기 위해서 예시를 들어보면, 블록체인의 경우 계정의 잔고나 컨트랙트의 상태등이 키에 해당되고, 해당 데이터들을 나타내는 가치들(계정 잔고의 경우, 해당 잔고에 얼만큼 가치의 토큰이 있는지)이 값에 해당된다.
사실 Key-value storage는 다른 블록체인들 또는 데이터 베이스에도 존재하는 구조라서 세이라고 크게 다를 것은 없다. 하지만 세이는 메타데이터를 최소화해서 저장하는 데이터의 양을 줄였다. 또한 키가 값과 직접적으로 매핑되어서 데이터 추상화를 위해 추가적인 과정이나 별도의 레이어를 거치지 않기 때문에 접근이 더 빨라진다는 점도 전체적인 블록체인의 효율성 향상에 긍정적인 영향을 미친다.
2.2.2 Flexible DB Backend
DB 효율성을 따질 때 그 구조 만큼이나 중요한 것이 다양한 스토리지 백엔드를 지원하느냐의 여부다. 노드 오퍼레이터들에게 단일 스토리지 백엔드를 요구하면, 스토리지 백엔드를 그들의 니즈에 최적화 시킬 수 없다는 부분이 단점인데 세이 V2는 PebbleDB, RocksDB, SQLite 를 지원하여 노드들이 각자의 니즈에 맞게 DB를 선택할 수 있도록 하였다. 아래의 표는 이 세 개의 DB들이 가진 특성을 비교한 표이다:
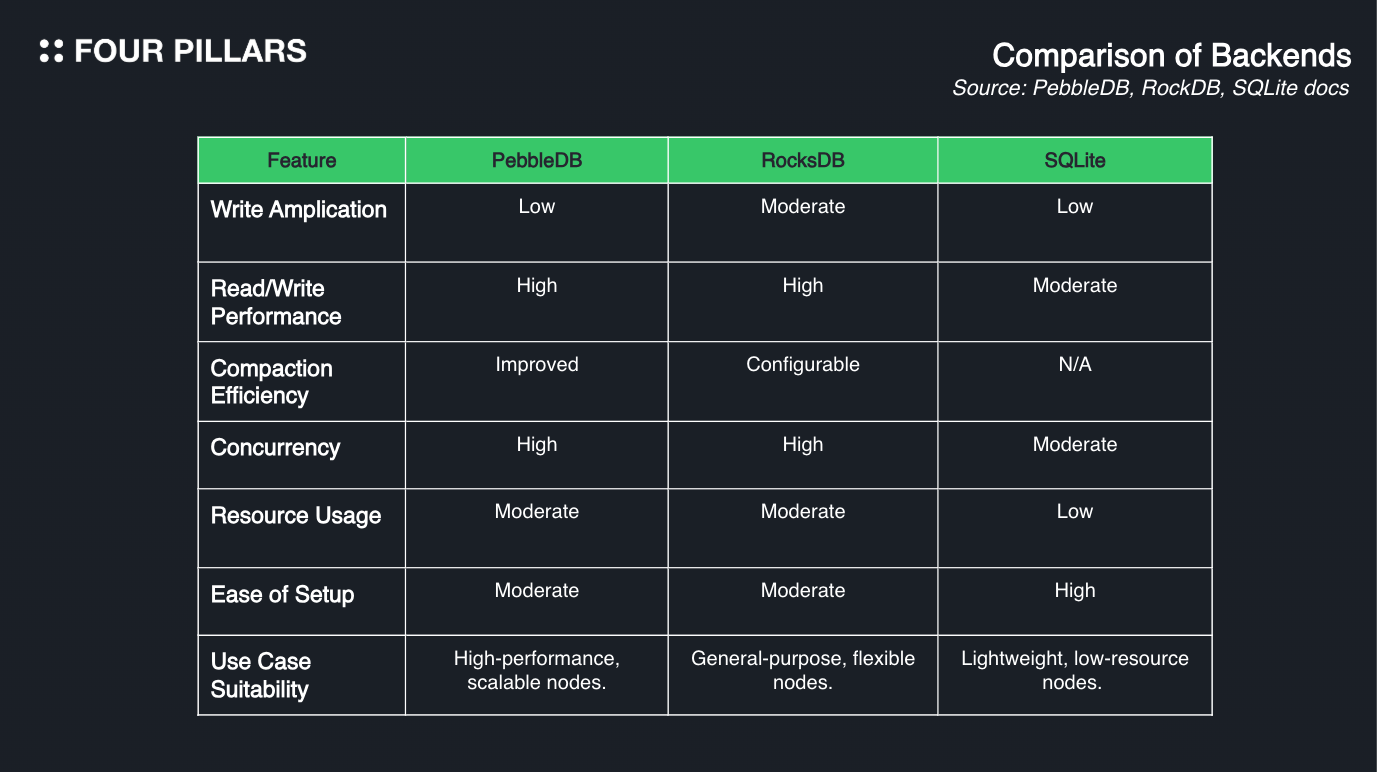
세이 V2에서 지원하는 DB들의 특성을 보면 퍼포먼스에 포커스를 둔 세이에 걸맞는 스펙을 가지고 있다고 생각된다. 이들 모두 최대한 쓰기의 양을 증폭시키지 않고(즉 데이터게 디스크에 직접 쓰여지는 횟수를 줄였다는 뜻) 굉장히 방대한 스케일의 데이터를 효율적으로 처리하는 것에 최적화 되어있기 때문이다.
세이에 따르면 이들중에 Pebble DB가 가장 좋은 성능을 보였다고 한다. 마지막으로, 이들 DB가 무조건 장점만 있는 것은 아니고, 각각의 단점들도 있으니 세이 팀에서 정리한 장단점 도표를 확인하시기 바란다.
2.2.3 Asynchronous Pruning
마지막으로 소개할 부분은 Asynchronous Pruning 으로, pruning(이하 프루닝)은 한국말로 가지치기를 의미한다. 즉 블록체인의 컨텍스트에서 프루닝이라고 하면, 블록체인에서 불필요하거나 오래된 데이터를 지우는 작업을 의미한다. 원래 블록체인에서의 프루닝 작업을 하게되면 네트워크에 악영향을 주는 경우가 많은데, 세이의 경우 프루닝 작업을 뒤에서 작업하기 때문에 블록체인 오퍼레이션에 영향을 주지 않고 불필요한 데이터를 쳐낼 수 있다. 세이 블록체인은 프루닝 작업을 통해서 과거 스테이트를 최적화하고, 노드들에 대한 스토리지 요구조건을 완화시킬 수 있다.
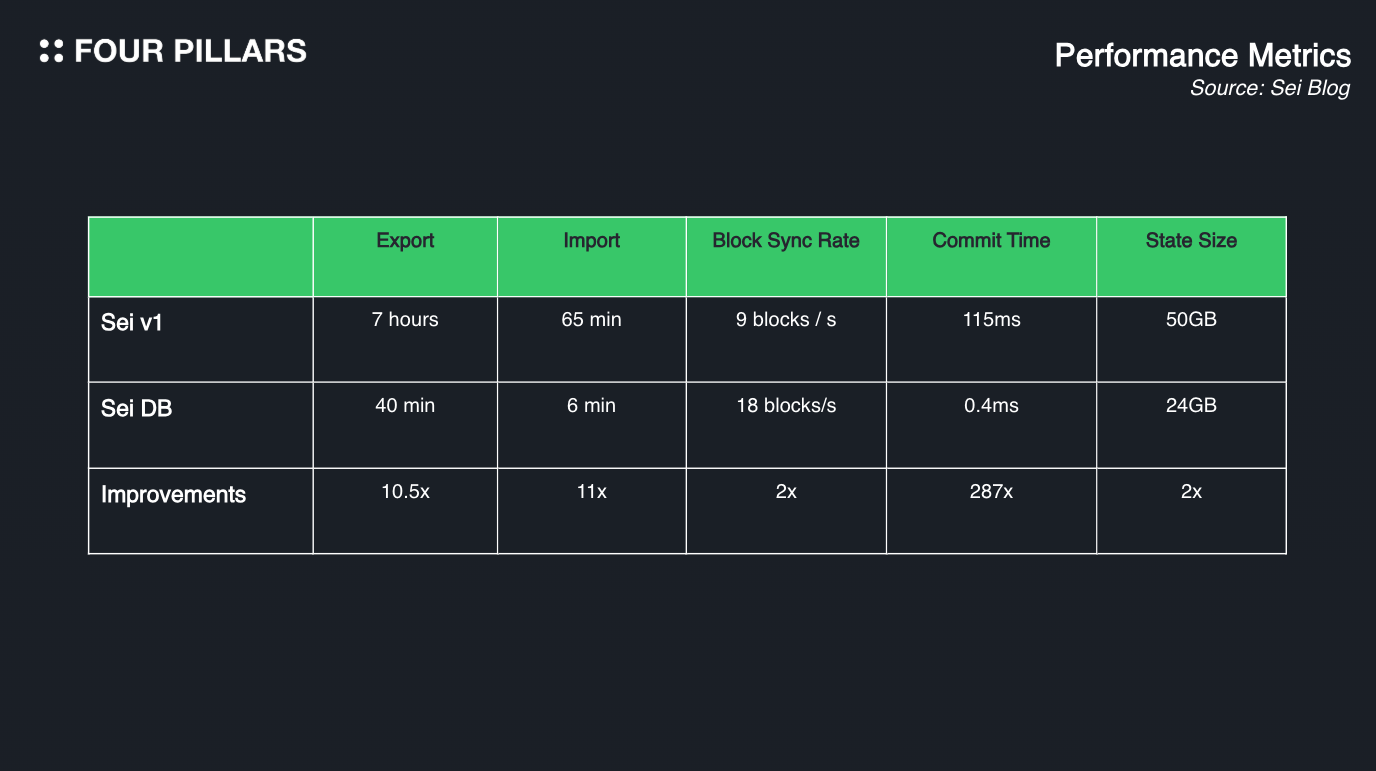
우리는 지금까지 세이DB의 두 가지 레이어들(스테이트 커밋과 스테이트 스토리지 부분)을 알아봤고, 각각 레이어들이 어떤 역할을 하며 어떤 피처들이 있는지를 알아보았다. 위의 설명을 통해 우리는 세이 DB가 ‘이론적으로’ 세이 블록체인의 퍼포먼스를 향상시키고, 데이터 베이스 최적화를 통해서 블록체인을 최적화 시킨다는 것을 알 수 있었다. 하지만, 가장 중요한 것은 역시나 실질적인 결과값이 아니겠는가? 실제로 세이 팀이 Sei DB를 테스트넷 환경에 적용했을 때 아래와 같은 데이터를 얻을 수 있었다고 한다:
활성 스테이트 크기 감소(Active State Size Reduction)
메모리에 저장된 활성 스테이트의 크기를 측정했는데, 활성 스테이트의 크기가 60% 감소한 것으로 나타났다.
과거 스테이트의 성장 속도 감소(Historical Data Growth Rate Reduction)
세이DB를 적용하고서 과거 스테이트의 크기가 얼마나 빠른 속도로 증가하고 있는지 봤는데, 이전 DB와 비교해서 그 속도가 90%이상 감소한 것으로 나타났다.
스테이트 싱크 타임 감소(State Sync Times Reduction)
노드들간에 스테이트를 싱크하는데에 걸리는 시간을 측정했는데, 약 1,200% 빨라진 것으로 측정되었다.
블록 싱크 타임 감소(Block Sync Time Reduction)
스냅샷을 찍게 되면 스냅샷 부근부터 가장 최근의 블록 높이가 있는 곳까지 얼마나 시간이 걸리는지를 측정했더니 기존 DB대비 그 속도가 2배 빨라졌다.
블록 커밋 타임 감소(Block Commit Times Reduction)
블록을 블록체인에 커밋하는데에 걸리는 시간을 측정하였더니, 기존 DB 대비 약 287배가 빨라졌다.
TPS(Transaction Per Seconds)
트랜잭션을 처리하기 위해서 걸리는 시간을 측정하였더니, 기존 DB 대비 2배 이상 빨라졌다.
위의 지표들을 미루어봤을 때, 세이 DB가 적용된 세이 v2의 경우 꽤나 드라마틱한 퍼포먼스 향상을 보일 것으로 예상된다. 어쩌면 EVM 호환이라는 큰 내러티브에 가려져서 큰 주목을 받지는 못했으나, 장기적으로 봤을 때 세이에게 더 중요하게 여겨질 수 있는 개선 사항은 바로 DB레벨에서 일어나는 변화가 아닐까?
이제는 세이 v2의 시대가 도래했다. 내러티브가 중요한 시장이라 세이 v2라고 하면 모두가 그저 “EVM 병렬처리”를 떠올리지만, v2 업그레이드로 변경되는 부분들을 자세히 보다보면 v2 업그레이드는 단순히 EVM 지원과 병렬처리 방식 개선으로 요약될 수 없을 정도로 기술집약적인 변화라고 할 수 있다. 물론 필자가 위에서 언급한 지표들은 v2 메인넷 이전에 그저 성능을 테스트한 지표들이기 때문에, 실제 환경에서는 얼마나 드라마틱한 개선이 이루어졌는지는 봐야한다. 그럼에도 불구하고 이러한 노력들이 꾸준히 주목을 받아야하는 이유는, 세이 v2 의 실질적인 퍼포먼스에 따라서 다양한 레이어1 블록체인들이 세이 DB를 벤치마킹하여 자신들의 DB를 강화하거나 보강할 수 있고 이는 “블록체인 성능 개선”이라는, 블록체인 업계 전체의 과제를 해결하는데에 있어서 큰 기여를 하는 것이기 때문이다.
세이는 처음부터 지금까지 “빠른 블록체인”이라는 한결같은 목표를 가지고 다양한 연구를 진행해왔다. 필자는 리서처로써, 빠른 블록체인을 구현하기 위한 이들의 집착을 응원한다. 그리고 더 나아가 이들의 연구를 발전시켜서 더 좋은 형태의 DB가 나올 수 있기를 바란다(세이 팀에서 나올 수도 있다). 이러한 노력들이 모여서 우리는 더 나은 블록체인을 만들 수 있고, 그것이야말로 블록체인이 더 많은 유저들에게 다가가는 방법이기 때문이다.
이 글의 비주얼을 제공해주신 Kate에게 감사의 말씀을 전합니다.