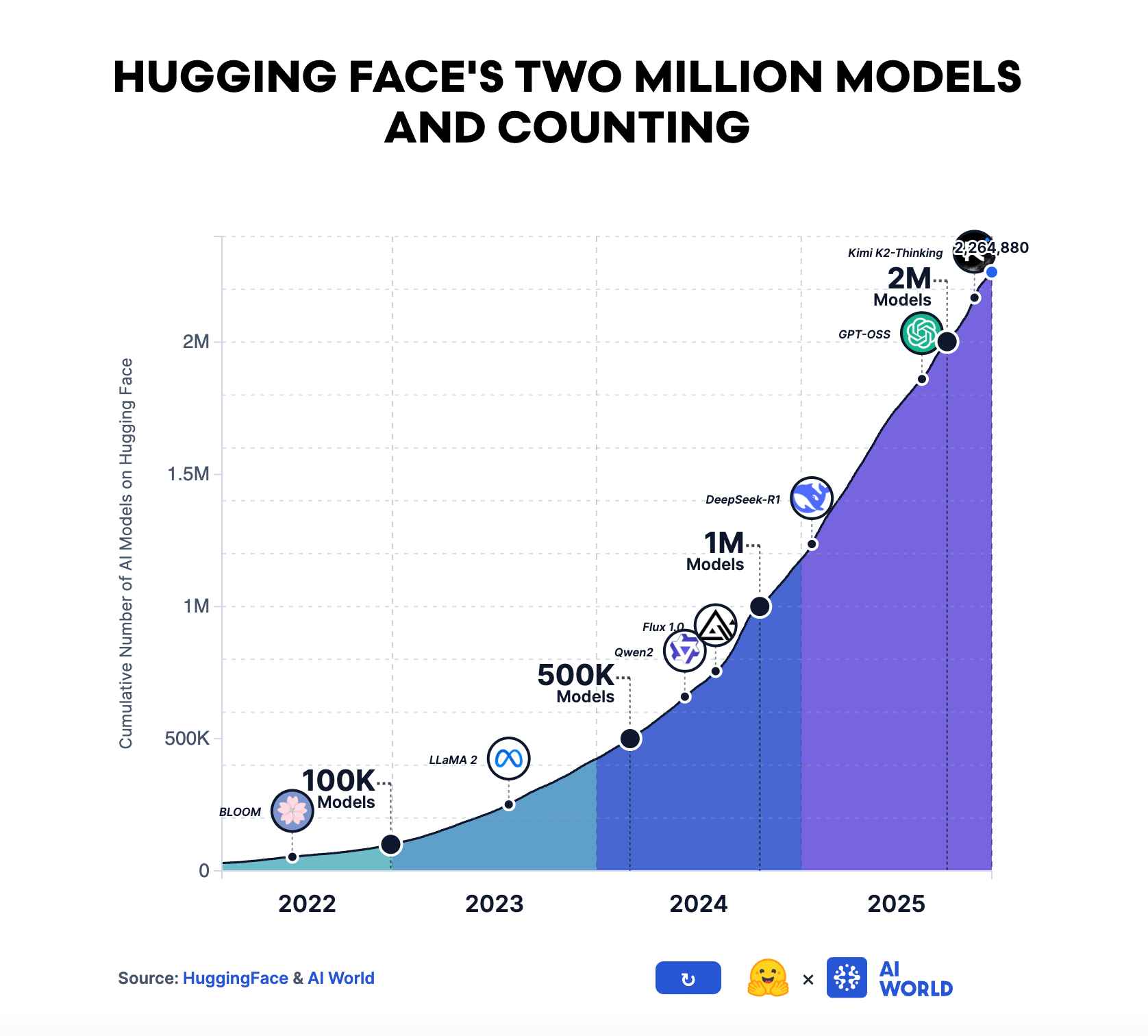
Over 2.7 million models are now listed on Hugging Face. By the numbers alone, AI looks plenty open already. But being able to download a model and being able to run it in production are two entirely different things. Self-hosting a 70B-class LLM requires at least $30,000 in GPU hardware, plus monthly operating costs for power, bandwidth, and engineering. These barriers push production inference toward a handful of platforms like OpenAI API, AWS Bedrock, and Google Vertex AI, which set per-token pricing, content filtering policies, and regional availability on their own terms. Models are open, but the infrastructure to run them is not. Until that changes, "open-source AI" remains an incomplete promise.
OpenGradient introduces a new blockchain architecture called HACA (Hybrid AI Compute Architecture) that separates the execution and verification of AI inference. Based on the assessment that conventional blockchain's re-execution-based consensus is unsuitable for AI inference, it employs specialized node types (full nodes, inference nodes, data nodes) that each perform distinct roles, with verification carried out through proofs alone. A verification spectrum combining TEE and zkML allows the level of trust to be calibrated per use case.
OpenGradient is expanding from inference infrastructure into a full-stack AI agent platform. It is assembling a vertically integrated platform where AI agents can reason (verified LLM inference), act onchain (SolidML), and pay for compute on a per-request basis (x402); all within a single trust framework. BitQuant, an open-source DeFi agent, serves as a working proof of concept for this stack. The result is an ecosystem that ties inference, verification, payments, memory, and applications into one cohesive layer.
The definition of "open" in AI must extend beyond publishing model weights to encompass the openness of execution infrastructure. Just as the Linux kernel being open did not prevent cloud infrastructure from becoming an oligopoly, the freedom of models alone does not complete the freedom of AI. Regardless of whether OpenGradient succeeds, the question of decentralizing the inference layer will be raised repeatedly in the next phase of AI.
Source: HuggingFace
The term "open source" has shifted in meaning several times throughout AI's history. From 2018 to 2020, open-source AI meant publishing research papers and training code. When OpenAI was founded as a nonprofit in 2015, its stated principle was to share scientific discoveries with the global AI community. By 2023, the definition had become something entirely different. Meta's Llama 2 and Llama 3, Mistral's early models, and Alibaba's Qwen series began releasing the actual neural network weights. As of March 2026, the open-source AI community platform Hugging Face hosts over 2.7 million registered models.
Yet "models being open" and "AI being open" are not the same thing. Even if a car's blueprints are made public, the product cannot be built without a factory to manufacture it. Equating the release of blueprints with the democratization of manufacturing capability is nothing more than a trap.
Reality proves this trap with precision. Production inference for open-source models is still handled overwhelmingly by a small number of platforms. OpenAI API, Google Cloud Vertex AI, AWS Bedrock, and Azure OpenAI Service command the majority of the inference market. According to a16z's "Who Owns the Generative AI Platform?" report, inference and per-customer fine-tuning costs account for 20 to 40 percent of AI app revenue. This means the bulk of that spending flows to a handful of cloud providers.
What would it take to self-host Llama 70B? At minimum, two A100 GPUs. Hardware costs alone exceed $30,000, and adding power, bandwidth, and engineering costs makes monthly operating expenses far from trivial. For individual developers and small teams, this is effectively an insurmountable barrier to entry. The result is a paradox: the model layer has been democratized, but the barriers to the execution layer have only grown stronger.
The structural contradiction raised above is not merely an abstract concern. Closed inference infrastructure imposes very concrete costs, which are worth examining one by one.
The first cost is the arbitrariness of pricing control. OpenAI's GPT-4 API was initially priced at $30 per million input tokens at launch, then reduced to $10 with GPT-4 Turbo, and later brought down to $2.50 with GPT-4o. The fact that prices have fallen is itself positive, but the biggest issue lies not in the price level but in where the pricing authority resides. Prices are all determined unilaterally by the service provider, and developers cannot predict tomorrow's pricing even as they build businesses on top of this API. The community has repeatedly reported situations where API costs that were affordable at the prototype stage exceed budgets when scaling to production.
The second cost is the non-determinism of censorship and content policy. OpenAI's content policies are updated without notice, and a prompt that worked yesterday can be rejected today. Anthropic's Claude also refuses to respond on certain topics, but the specific details of those criteria are not explicitly disclosed. From the perspective of developing AI agent-based applications, the possibility that a core feature of the service could be invalidated by a single line of policy change from a third party constitutes a structural risk.
The third cost is a single point of failure. Between 2023 and 2024, the OpenAI API experienced multiple episodes of downtime, and each time, API-dependent applications around the world had to suspend their services simultaneously. Centralized inference servers are vulnerable not only to technical failures but also to regulatory failures. The OpenAI API is blocked in numerous countries under U.S. OFAC sanctions law, and this is causing a geopolitical fragmentation of AI infrastructure.
The fourth cost is data privacy. The fact that all inference requests pass through specific servers means users' input data is fully exposed to the inference provider. This has become a structural barrier to AI adoption in sensitive domains such as healthcare, law, and finance.
These four costs are problems that inevitably arise from a structure in which inference infrastructure is concentrated among a few. The question naturally follows: can the availability advantages of distributed systems also be applied to inference infrastructure?
It is against this backdrop that OpenGradient enters the picture. OpenGradient is a protocol that executes AI model inference on a distributed network and verifies the results onchain. Defining itself as "The Network for Open Intelligence," it is an attempt to technically implement the opening of inference infrastructure.
The core premises are twofold. Anyone should be able to contribute their GPU to the network, and the correctness of results should be verifiable without trusting a third party.
Source: OpenGradient
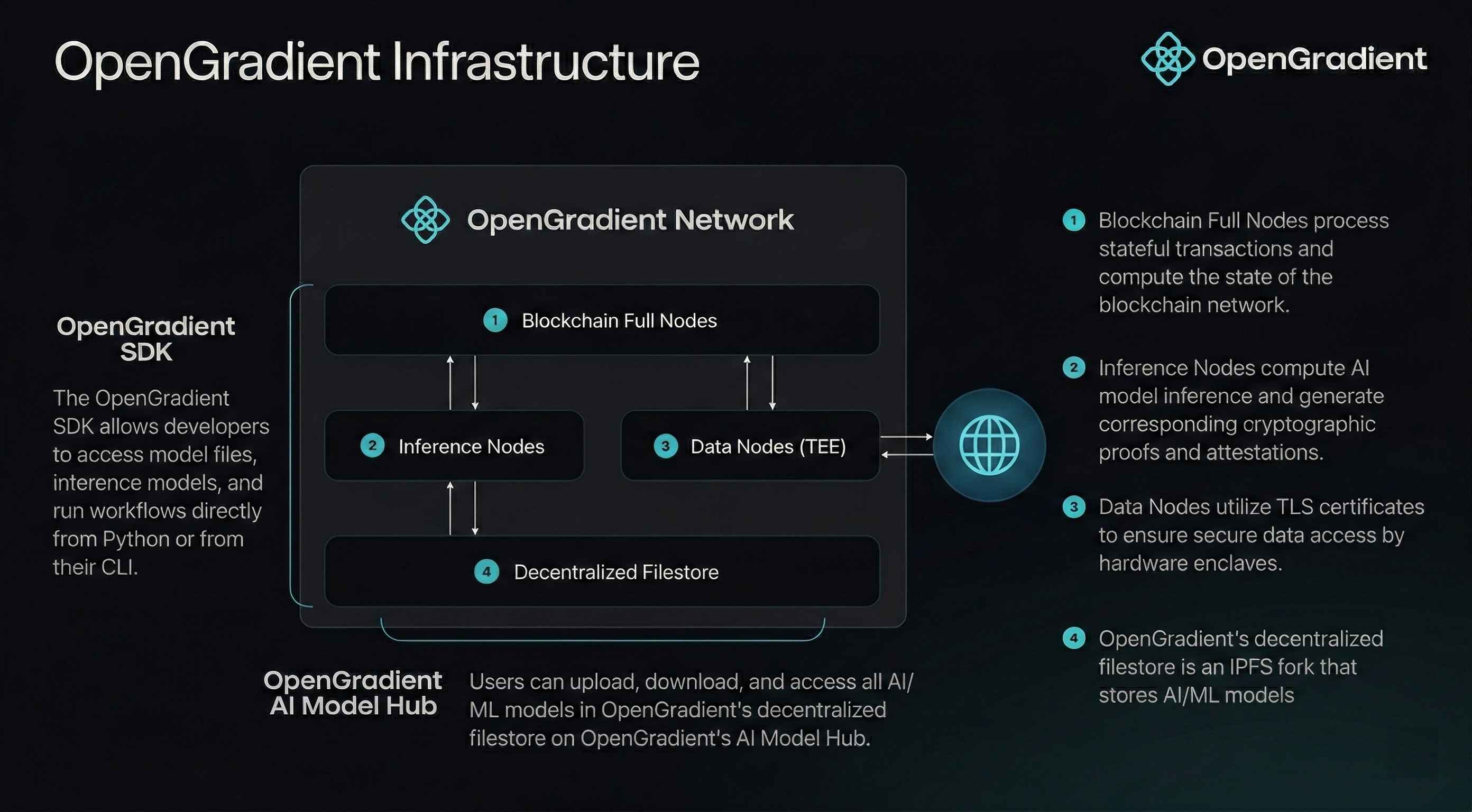
What makes this possible is HACA (Hybrid AI Compute Architecture). HACA is the design principle that runs through the entire OpenGradient network and defines the protocol's technical identity.
Existing blockchains use re-execution-based consensus. Every validator independently executes the same transaction and checks whether they arrive at the same state. This works well for operations that are low-cost, deterministic, and fast, such as token transfers. But AI inference violates all three of these premises. Inference requires GPUs, and if 100 validators each run a 70B-parameter LLM, the same result is redundantly computed 100 times. LLMs produce non-deterministic outputs, making cross-validator output comparison impossible. And a single inference can take several seconds, stretching block times to impractical lengths.
Some projects have attempted to handle AI inference through an oracle approach, fetching inference results externally and injecting them into the chain. But this merely relocates the trust problem without solving it. Who operates the oracle, and how do you confirm the correct model was applied to the correct input? Ultimately, a single entity must be trusted, which defeats the purpose of decentralization.
HACA approaches this problem from the opposite direction. Rather than fitting AI into the existing blockchain model, it designs the blockchain model itself around the actual requirements of AI workloads.
The core principle of HACA is that execution and verification are independent tasks performed on separate timelines. OpenGradient's design ensures the verification layer can assess validity through proofs alone, without needing to re-execute the original computation.
To implement this principle, HACA divides the network into specialized node types as follows.
Full Nodes: Blockchain validators that run CometBFT consensus, verify proofs, settle payments, and maintain the ledger. Crucially, full nodes do not execute models themselves. They verify only cryptographic evidence that a model was executed correctly. As a result, full nodes can operate on general-purpose hardware without GPUs, which increases the size and diversity of the validator set and strengthens decentralization.
Inference Nodes: Stateless GPU workers that actually run models and return results directly to users. There are two subtypes. LLM Proxy Nodes route requests to external LLM providers within a TEE enclave, while Local Inference Nodes run models directly on their own hardware. Individuals, enterprises, and data centers contribute their GPUs, execute inference tasks, and receive compensation. Node requirements are differentiated by model size: 7B-class small models can run on consumer-grade GPUs, while 70B-class large models are processed only on data-center-grade nodes.
Data Nodes: TEE-protected nodes that fetch and attest external data (APIs, databases, oracles). The enclave ensures that not even the node operator can view or tamper with the data. By isolating data access from inference and consensus, trust boundaries are maintained clearly.
Storage: OpenGradient uses Walrus as its storage layer, a distributed blob store for model files and large proofs. Only blob ID references are recorded onchain, keeping the ledger lightweight while Walrus maintains data availability.
This specialized structure is not arbitrary but arises inevitably from the physical constraints of AI workloads. AI inference is expensive and heterogeneous. The hardware requirements for a small classification model and a 70B-parameter LLM are fundamentally different. A uniform validator set would be over-provisioned for small models or incapable of running large ones. Verification, on the other hand, does not require re-execution. TEE attestations prove that an enclave ran approved code without tampering, and zkML proofs provide mathematical certainty that a specific model produced a specific output. Verification nodes can remain lightweight, and this is the essence of the hybrid design embedded in the name HACA.
HACA's operational flow is divided into two independent paths, a design aimed at simultaneously achieving user experience quality and trust guarantees.
Fast Path: When a user requests inference, the request is routed directly to an appropriate inference node. The blockchain is not on the critical path here. There are no block confirmations, validator votes, or consensus delays. Users receive responses at the same latency as calling a centralized API. The approach resembles how a CDN distributes web content geographically, except that instead of caching static content, it distributes dynamic inference execution.
Verification Path: After inference is complete, proofs are settled asynchronously. The inference node generates a proof (TEE attestation, zkML proof, or signed result) and submits it to full nodes. Full nodes verify the proof in the next consensus round, and once more than two-thirds of validators agree, the proof is permanently recorded on the ledger. For large proofs (such as zkML), only a blob ID used as a reference is stored onchain, with the full proof data kept on Walrus.
Through this structure, OpenGradient ensures that adding inference nodes increases throughput linearly without adding load to the verification layer. Full nodes verify proofs in milliseconds regardless of whether the underlying inference took 50 milliseconds or 5 seconds.
There is, however, an explicit tradeoff in this design. A temporary trust gap exists between the moment inference results are returned and the moment the proof is settled onchain. During that interval, onchain verification of the result has not yet been completed. For atomic DeFi operations that require immediate onchain verification, this gap can be problematic.
OpenGradient addressess this through PIPE (Parallelised Inference Pre-Execution Engine), a core execution engine designed for native onchain ML inference with atomic guarantees. Rather than a fallback mechanism, PIPE is a distinct execution path optimized for use cases where inference results must be settled within the same transaction that triggers them.
PIPE achieves this through a novel inference mempool. When a user submits a transaction, it is first placed in the inference mempool, which simulates the transaction and extracts all embedded inference requests. These requests are then dispatched to the inference network for parallel execution. Once all results are available, the transaction is retrieved from the mempool and executed with the pre-computed inference results, then included in the next block. Because inferences for hundreds or thousands of pending transactions can be processed in parallel, no single transaction can slow down the network. The actual block building remains extremely fast regardless of model complexity.
How do you confirm that a distributed node returned the correct inference result? HACA answers this question not with a single method but with a verification spectrum. The underlying judgment is that not all inferences require the same level of trust.

TEE (Trusted Execution Environment) is the default verification method currently applied to all LLM inference on OpenGradient. When a GPU node runs inference inside a TEE, the hardware generates an attestation proving at the hardware level that the enclave executed approved code without tampering. Full nodes verify this attestation by comparing it against known-good measurement values (PCR values) recorded in an onchain TEE registry. In this process, full nodes do not need to know what the prompt was, which model was used, or what the response contained. They perform purely cryptographic verification, which provides an important privacy guarantee. Not even the node operator can view or tamper with the data or code being executed.
That said, TEE's limitations are also clear. The trustworthiness of TEE attestations ultimately depends on the hardware implementation of the CPU manufacturer (Intel, ARM, etc.). If a fundamental TEE vulnerability is discovered, the security model could be weakened. Intel SGX, in fact, has been exposed to multiple side-channel attacks in the past. OpenGradient's official documentation acknowledges this limitation and states that the design mitigates it by supporting multiple verification methods and allowing critical operations to require zkML.
zkML (Zero-Knowledge Machine Learning) proofs sit at the opposite end of the verification spectrum. They generate inference results as zero-knowledge proofs, enabling a third party to mathematically confirm the correctness of results without re-executing the inference. Because they rely on pure mathematical proof with no hardware trust assumptions, anyone can perform verification independently. According to the official website, over 500,000 zkML proofs have been generated to date.
The limitations of zkML are equally clear. With current technology, the overhead of proof generation ranges from 1,000 to 10,000x, making it impractical for large models or high-throughput workloads. Projects such as EZKL and Modulus Labs are pushing this boundary, but real-time proof generation for 70B-class models has not yet been achieved. This is a current limitation of ZK technology itself, an area that will ease as the technology advances.
The parallel use of these two methods is a design intended to offset each one's weaknesses. For healthcare data inference where privacy is paramount, TEE can be prioritized. For financial inference where public verifiability of results is needed, zkML can take precedence. It is even possible to mix different verification methods for different model calls within a single transaction. For example, zkML can be applied to a risk scoring model, TEE to an explanation-generating LLM, and basic signature verification to a logging model, all simultaneously. This per-task flexibility means developers need not over-verify low-risk computations or under-verify high-risk ones.
Source: OpenGradient
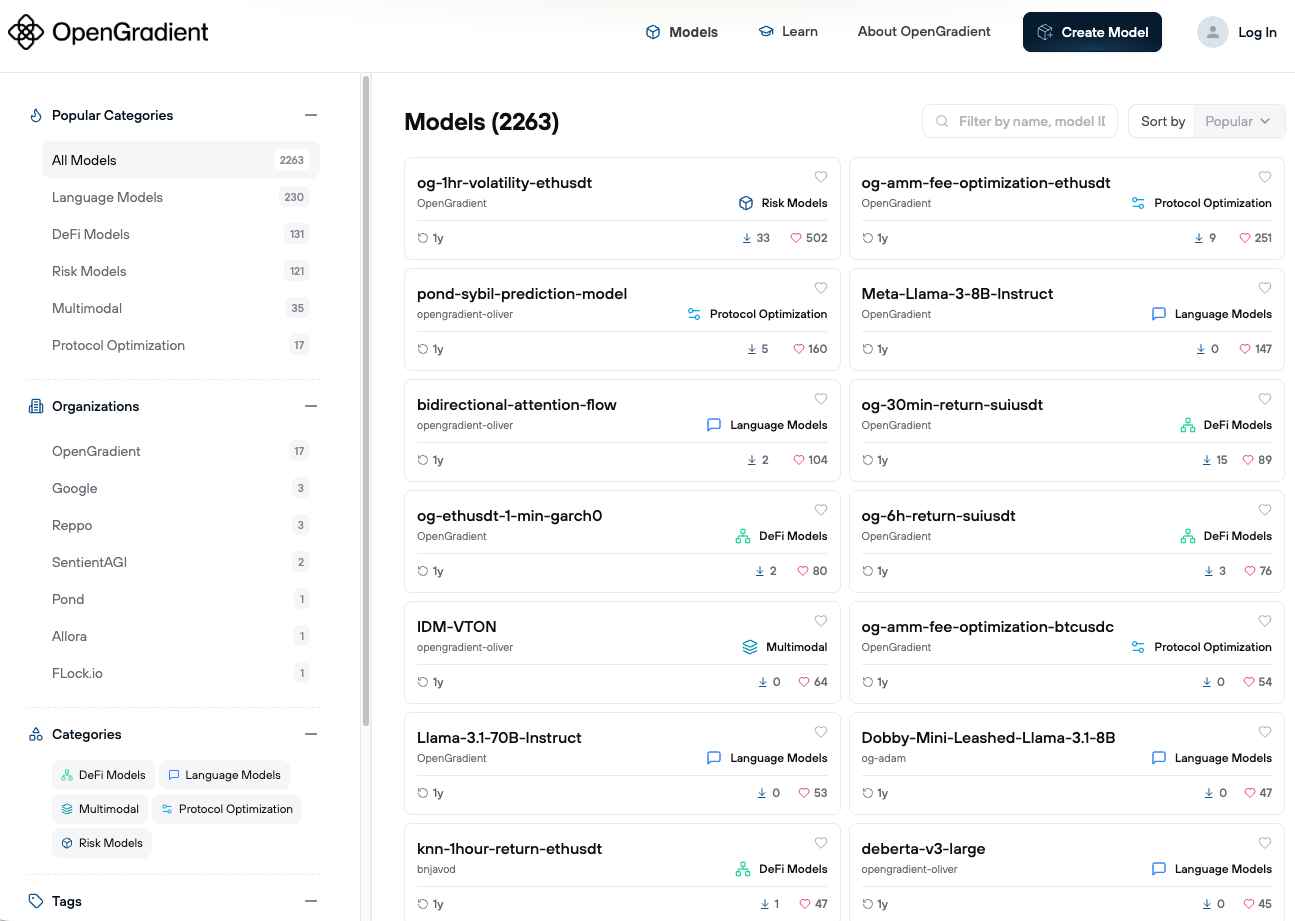
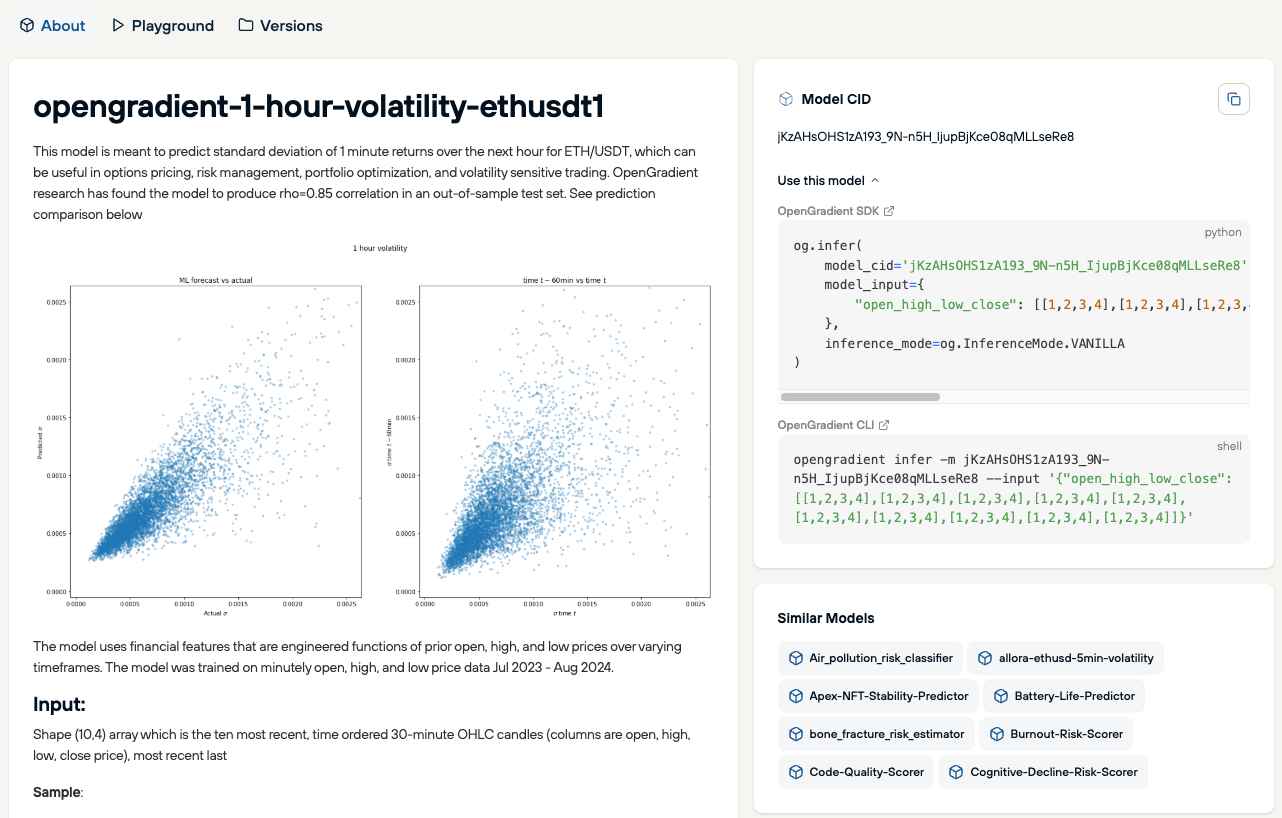
The first service layer built on top of HACA is a decentralized model hub. OpenGradient calls it "the world's largest decentralized AI model repository," with over 2,200 models currently registered. Model metadata is recorded onchain, and integrity is verified through weight hashes.
Source: OpenGradient
This may appear similar to Hugging Face, but there is a fundamental difference. While Hugging Face is a general-purpose repository, OpenGradient's model hub registers only models that can actually be executed for inference on the network. Anyone can register a model without permission, and the official documentation states that all model architectures are supported. No node can falsely claim to have run an unapproved model.
The interface that developers actually encounter also matters. OpenGradient provides a Python SDK supporting ML and LLM inference execution, model management, and automated workflow deployment. The goal is to achieve a level of abstraction where developers need not be aware of HACA's internal structure. The friction of transitioning from the existing OpenAI API will be a decisive factor for practical adoption.
Source: OpenGradient
Current AI systems suffer from statelessness, where context resets with every conversation, and existing long-term memory solutions remain confined to a single product. The root cause is that user identity information is fragmented across multiple platforms.
MemSync addresses this by providing a portable memory infrastructure that travels with the user. It works across ChatGPT, Claude, Perplexity, and other AI platforms through a Chrome extension, with a REST API available for direct integration.
Memory is separated into two types.
Semantic Memory: Represents stable, long-term facts and traits such as core identity, career background, language fluency, and fundamental preferences.
Episodic Memory: Captures temporal context such as ongoing projects, recent events, and current goals.
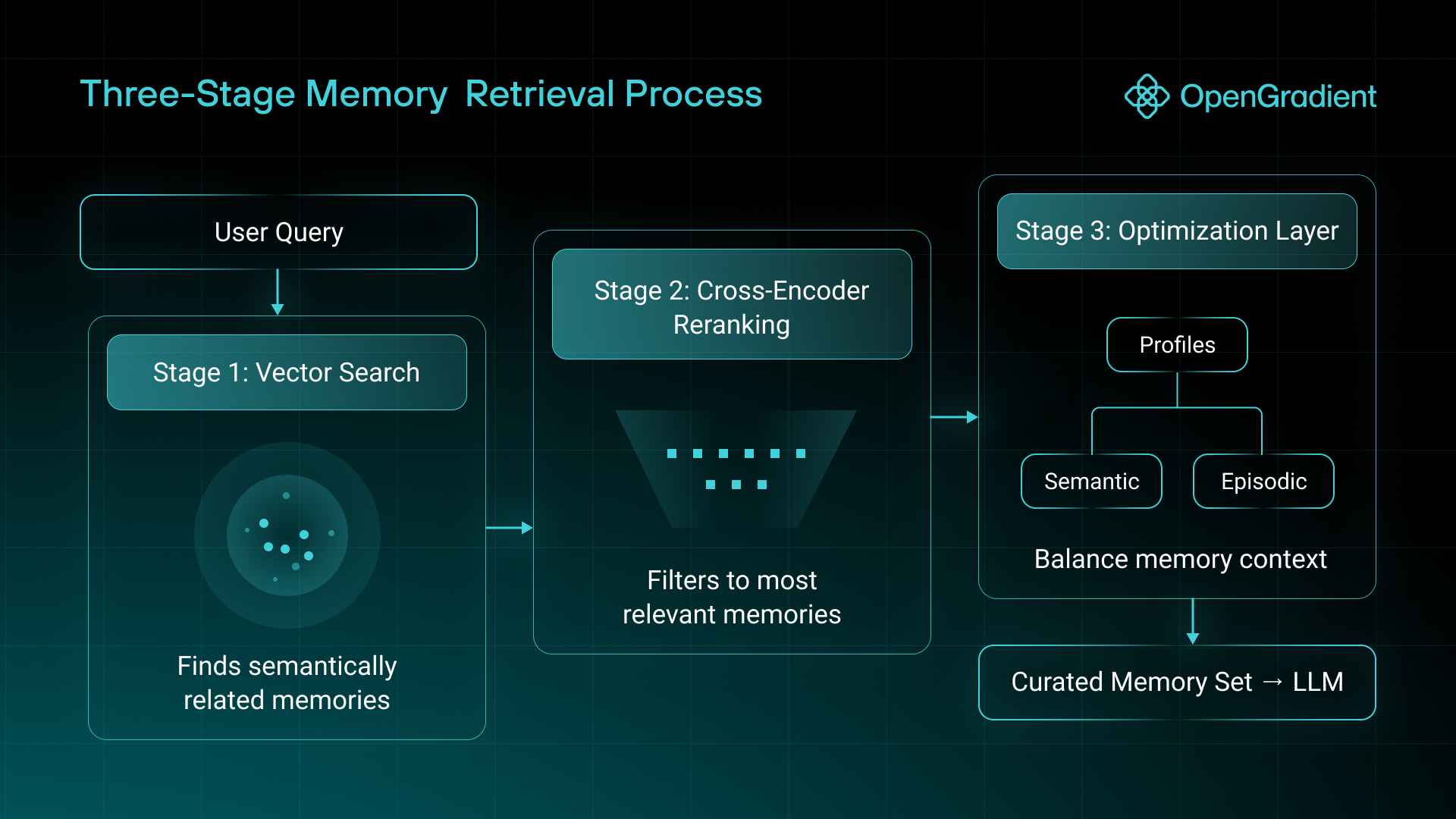
During retrieval, MemSync runs a three-stage process (vector search, cross-encoder reranking, and an optimization layer) independently against both memory pools, adjusting the ratio of semantic to episodic results based on query characteristics. It also tags memories into categories such as Identity, Career, and Interests, then synthesizes cross-category summaries to generate dynamic user profiles that persist across conversations.
Within the OpenGradient ecosystem, all memory processing operations, including extraction, embedding, and retrieval, run through TEE-verified inference. The memory layer therefore inherits the same trust guarantees as any other OpenGradient workload, offering a structural alternative to conventional memory systems that require users to entrust personal data to a centralized provider.
OpenGradient is not remaining a standalone inference infrastructure protocol but is vertically expanding its own ecosystem. The following is a look at the major products and frameworks that are either already launched or currently under development.

Source: OpenGradient
The most recent notable integration is with the x402 protocol. x402 is an open payment protocol utilizing the HTTP 402 "Payment Required" status code, a standard led by the Coinbase development team. It enables instant micropayments on a per-HTTP-request basis, without API keys or subscriptions.
What matters about OpenGradient's integration of x402 is not the adoption of the payment protocol itself, but where it was placed within the architecture.
In a typical cloud inference service, payment is handled in a separate layer, decoupled from computation. A user's request first passes through authentication/payment middleware, and only after verification does it reach the actual GPU. This intermediary layer carries two inherent problems: user request content can be exposed during payment processing, and any failure or latency in this layer directly degrades usability.
The first problem, the exposure of user requests, is resolved by OpenGradient's design as it embeds x402 directly inside every TEE instance. Since the payment processing and inference execution occur within the same trust boundary, the intermediary layer simply does not exist.
Each TEE instance generates its own enclave signing key, signs the output upon inference completion, and records only the hash onchain. Third parties can confirm that "an inference was executed" but cannot access the actual content. Only the user holding the result can recreate the hash and compare it against the onchain record, independently verifying that their inference was in fact executed and recorded. Furthermore, enclave-terminated TLS connections ensure that even the host machine cannot decrypt communications, structurally eliminating any point where data could be exposed between payment and computation.
OpenGradient also addresses the second problem: the usability risk introduced by payment latency blocking compute. OpenGradient adopts a pre-funded balance model where users deposit tokens in advance, allowing inference to begin immediately without waiting for onchain settlement to complete. In agentic workflows that make dozens of parallel inference calls, payment confirmation delays blocking computation would make the system unusable in practice.
Despite the underlying complexity, the interface developers actually face is straightforward. OpenGradient's Python SDK abstracts away verified node discovery from the onchain registry, request routing, and payment processing. Users simply fund their wallet and make standard LLM API calls. Currently, payments are processed on the Base testnet, while inference settlement and verification occur on the OpenGradient testnet. The ability to directly register and operate TEE nodes will become available after the relevant software is open-sourced.
BitQuant is OpenGradient’s open-source AI agent framework that performs DeFi analysis and trading through a natural language interface, released under the MIT license in May 2025. The open-source release followed a closed beta phase that attracted over 50,000 users.

BitQuant's architecture consists of two agent types. The Analytics Agent provides deep analytics on portfolios, tokens, protocols, and market trends, drawing from real-time and historical data sources such as CoinGecko and DeFiLlama. The Investment Agent helps users identify yield opportunities and guides them through lending and AMM pool selection on Solana, utilizing Solana RPC endpoints for onchain data. The framework is designed to be extensible, allowing developers to build custom agents for automated trading, NFT analytics, cross-chain portfolio management, or any other DeFi workflow.
What makes this framework interesting is that it provides a concrete case where OpenGradient's infrastructure is applied to real financial decision-making. Users can request portfolio risk analysis, liquidity pool optimization, and yield strategy automation in natural language, with all inference processes running verifiably on the OpenGradient network.
SolidML is a framework that allows smart contracts to natively invoke ML and LLM inference as part of an atomic onchain transaction. If verifiable LLM inference serves offchain applications and agents, SolidML brings the same capability directly into the EVM execution environment.
The design is straightforward. A Solidity developer calls a precompiled function, specifying the model's Blob ID from the Model Hub, the input data, and the desired verification mode (zkML or TEE). The inference executes atomically within the same transaction, and the result is returned as a native Solidity data type that can be used immediately in subsequent contract logic.
This opens up a class of onchain applications that were previously either impossible or dependent on fragile oracle workarounds. Examples include AMMs that use ML-driven dynamic fee models, lending protocols that adjust loan-to-value ratios based on real-time risk scoring models, and onchain agents that make decisions based on verified model outputs. Because execution and verification both complete within the same transaction, there is no trust gap between the model's output and the contract's action on it.
The main advantages of SolidML are as follows.
Atomic execution: Inference settles within the transaction that triggers it, ensuring state consistency.
Simple interface: A single function call with no callback handlers.
Composability: Multiple models can be chained together through arbitrary contract logic.
Native verification: zkML and TEE proofs are validated by the underlying protocol, so contracts can trust results without implementing separate verification logic.
SolidML is currently available on OpenGradient’s alpha testnet.
Let us return to the opening question. If models are open but the execution environment is closed, is AI truly open?
OpenGradient's answer is to decentralize and make the inference layer verifiable, presenting a path where the openness of models leads to the openness of execution. Over two million inferences and more than 500,000 proofs demonstrate that OpenGradient's vertically integrated stack is working in practice, beyond the lab.
The changes that could be expected if the opening of the inference layer is realized are clear. Developers' options would expand, reducing dependence on a single API provider and creating competitive pressure on pricing, censorship policies, and availability. A path to AI inference access without geopolitical restrictions would open up, providing an alternative for developers in countries where APIs are currently blocked. TEE-based inference could become a practical means of enforcing data sovereignty by minimizing the exposure of sensitive data to third parties. All of these implications, however, are contingent on the network reaching sufficient scale and economic sustainability. At present, technical feasibility has been demonstrated; economic proof remains ahead.
When Linux opened its kernel, people believed that software freedom had arrived. Yet a structure emerged in which AWS, GCP, and Azure oligopolized cloud infrastructure, revealing the fact that openness in code does not guarantee openness in infrastructure. The same pattern is repeating in AI. OpenGradient has constructed a technical response to this question. Regardless of whether it succeeds, the question of decentralizing the inference layer itself will be raised repeatedly in the next phase of AI, and the answer must be found not only in the domain of technical feasibility but also in that of economic sustainability.
Dive into 'Narratives' that will be important in the next year