As the world increasingly moves toward an era of hyper-personalization, two keywords that have set the IT industry abuzz over the past five years are undoubtedly blockchain and AI. Interestingly, while both technologies seem to aim for similar values, their approaches are fundamentally different. Perhaps that's why some perspectives have started to see the contrasting nature of AI and blockchain as an opportunity for mutual complementarity (e.g., the decentralization of AI). The integration of Federated Learning and blockchain is poised to become one of the most representative examples of this synergy.
In an increasingly complex society with more interactions, individuals prefer to express their unique identities and seek services that offer both convenience and distinctive experiences. As a result, many businesses have started focusing on providing personalized services, relying heavily on AI technology.
However, when you think about it, providing a perfectly personalized service is practically very challenging, as the context of each moment in our lives is extremely complex and ever-changing. We cannot, nor do we wish to, constantly record our status as data. Moreover, as the dependence on digital devices and various (AI) services in individuals' lifestyles has continued to increase, the data used for the personalization of the new services we enjoy may not be our raw data, but rather a mistaken personalized result based on only a very small portion of our personal data.
Indeed, today, many centralized AI services create a paradox where, in their pursuit of personalization, they end up undermining it. Under the pretext of offering personalized services, we find ourselves having to passively accept the answers that AI provides. The process by which these systems collect and analyze vast amounts of user data is akin to a black box—nearly impossible to peer into—and the so-called tailored options they offer often feel more like responses imposed by the AI.
To make matters worse, as public dependence on AI services increases, new players aiming to create more sophisticated products and applications to compete with existing services face the need for extensive research on models and computational infrastructure capable of handling large volumes of data. This suggests that progress in this field is difficult without a significant concentration of capital across businesses and academia, further deepening reliance on existing AI models or AI stack providers.
Perhaps we are relinquishing our independent control over what we want and think to the system, gradually blurring our individuality in the process. I believe it is time to question whether personalization is truly being achieved in the right way or even if it can be. If AI technology genuinely aims to pursue the value of personalization, the future of AI should not be managed by a single, massive third-party entity providing services in a one-way manner. Instead, it should be designed as a participatory system where users can selectively provide personalized data, and as open-source, allowing anyone to verify the model's logic.
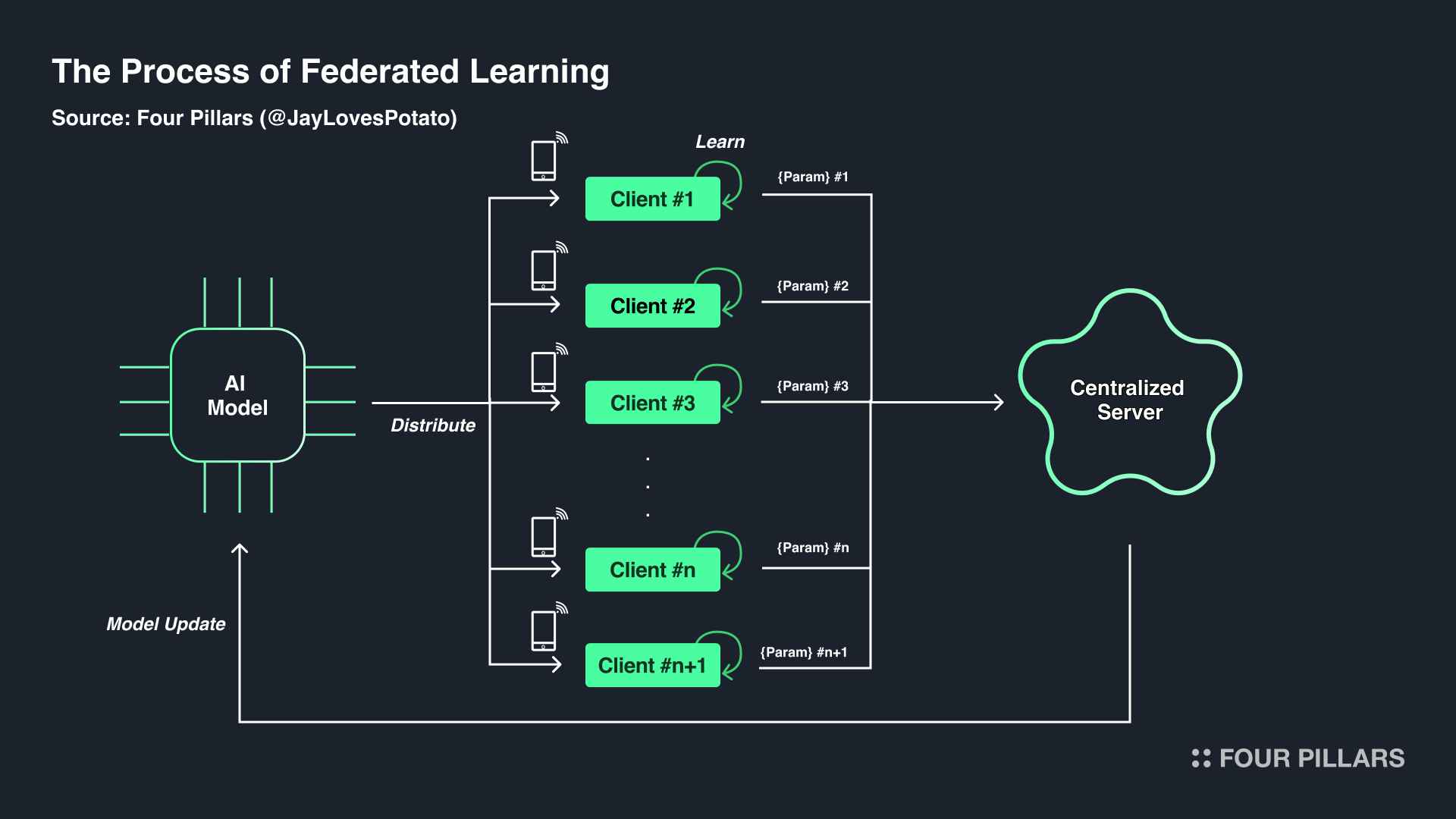
The industry has not been entirely unaware of these challenges - the emergence of federated learning serves as a prime example. Initially proposed in a paper by Google researchers like McMahan, H. B., the core concept of federated learning involves sending AI training models to individual local clients, each with their unique data. The models are trained locally, and then the central server aggregates the learned parameters sent back from the clients.
In other words, when AI modeling is implemented through federated learning, each local client trains the required model using data on their device but only shares the training results with the central server. This means their raw data never needs to be exposed to third parties. Additionally, since they receive the model structure from the central server, they can see how their data is being used and what results it produces, making the process transparent and trustworthy (i.e., a white-box approach).
Moreover, the central server calculates the average of each parameter trained by multiple clients and applies this to update the model. This approach reduces reliance on centralized data, which could potentially be biased in traditional AI modeling methods, allowing for the creation of a more objective and unbiased model. Additionally, since data storage and computation required for training are handled entirely on local clients, it can offer advantages in terms of storage and computational costs for overall model development, as well as in reducing network communication latency.
The applications of federated learning can be highly diverse - notably, it can be particularly useful in scenarios such as developing services that utilize sensitive data like personal financial information or patient medical records, implementing AI agents, or creating customized driving logic for autonomous vehicles that continuously learn from large volumes of data to provide real-time outcomes.
However, despite these advantages, it is still difficult to see federated learning being widely adopted across various industries. The key challenges contributing to this are as follows.
High Communication Costs
When a federated learning network consists of tens or hundreds of millions of devices, communication within the network can be several times slower than local computation. In such scenarios, it is crucial to ensure high communication efficiency. This can be achieved by reducing the total number of communication rounds or the number of communication clients themselves, or by implementing methods such as model compression that reduce the size of the communication data. Various modeling strategies need to be considered and applied to address these challenges.
Systemic/Statistical Heterogeneity and Challenges in Securing Participating Clients
Federated learning assumes that the data collected from each client is independent and identically distributed (i.e., IID). However, it cannot ignore the likelihood that the conditions of participating clients (e.g., storage, computation, communication capabilities) may be biased. Moreover, securing a sufficient number of clients without offering significant incentives can also be extremely challenging.
Model / Data Poisoning & Idle Clients
A poisoning attack involves incorporating maliciously tainted data into the training process, significantly degrading the performance of the final model. In the context of federated learning, even a small number of attackers can launch a successful attack, and identifying them is challenging due to the nature of only sharing model parameters. Additionally, when clients do not actively participate in the model update process itself, it increases the likelihood of a decline in the quality of the final model.
Evasion Attack
An evasion attack involves making minimal alterations to input data to mislead the model into learning incorrectly (e.g., adding a slight amount of noise to the original data that is indistinguishable to the human eye, thereby maximizing the model's loss function value). In the context of federated learning, this type of attack becomes particularly effective because the attacker can observe the parameters shared across the entire network, making it much easier to manipulate the already optimized parameters.
The most significant value of blockchain lies in its ability to incentivize diverse participation necessary for system operation. By defining the mechanisms through which various participants reach consensus, it becomes possible to prevent malicious behavior and create a transparent system.
In this context, I believe that the field of federated learning can make significant progress through the blockchain technology, which can help address some of above challenges that have hindered its development and adoption. A notable example of this, which will be briefly discussed below, is FLock.io—a project that combines federated learning with blockchain.
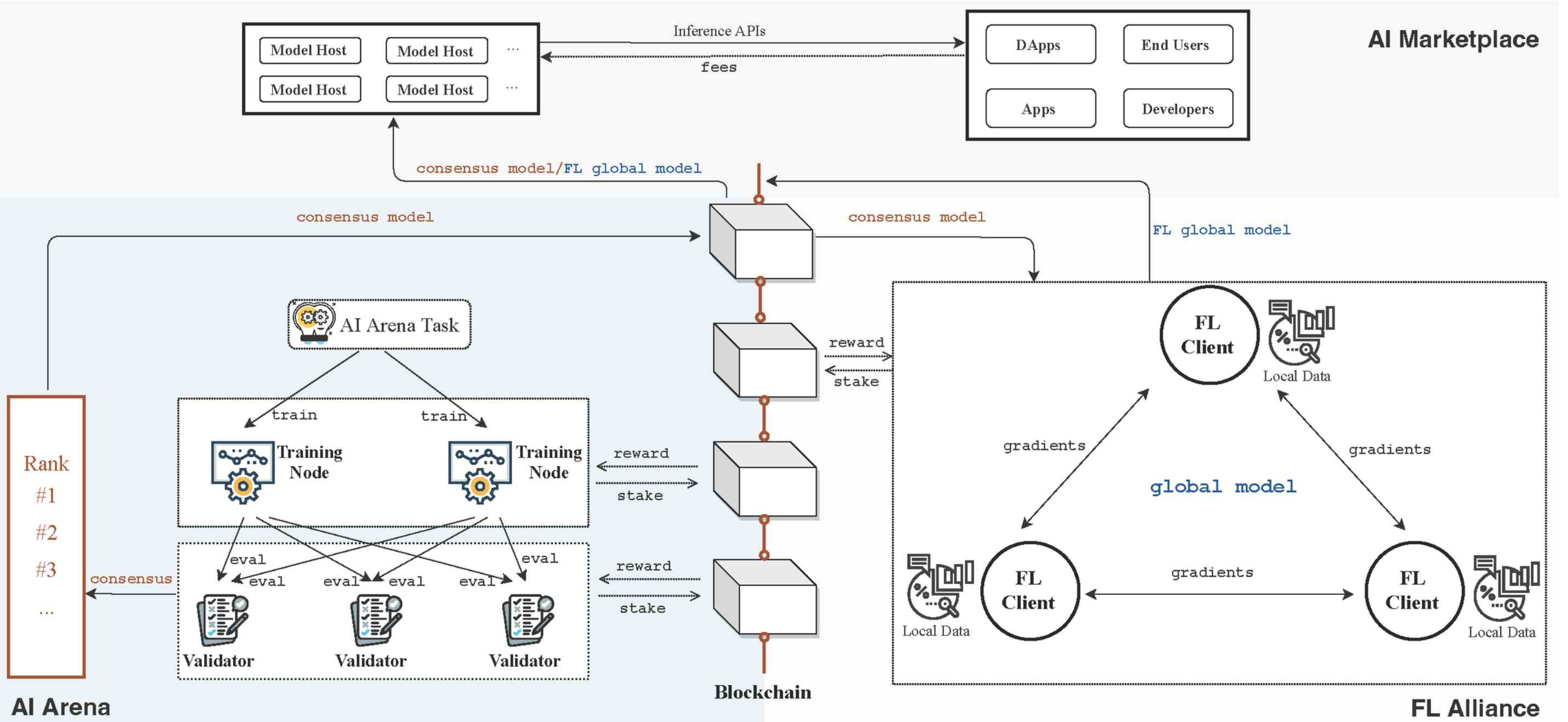
FLock.io operates through a structure that intertwines three key components: AI Arena, FL Alliance, and AI Marketplace. It uniquely addresses some of the aforementioned challenges by leveraging a DPoS consensus algorithm.
A brief overview of how the FLock.io network functions is as follows -
(1~3) ; Initial Model Training Phase
(4~5) ; Model Fine-Tuning Phase
Task Creators generate models they want to train and distribute tasks on the AI Arena.
Training Nodes carry out the initial training process for the created tasks and submit the trained models to Validators - to participate in these tasks and earn rewards, Training Nodes must stake a certain amount of $FML tokens. If they engage in malicious behavior, the staked tokens will be slashed.
Validators evaluate the submitted models and rank them through consensus - Validators also need to stake tokens to participate in this process. Their rewards are determined in proportion to the sum of their staked tokens and those delegated by Delegators, assuming they perform accurate and honest validation.
Models that reach consensus are assigned to the FL Alliance, where each client is randomly designated as a Proposer or Voter in each round. Selected Proposers fine-tune the assigned model using their local data, creating an improved version of the FL global model. Voters aggregate the proposed FL global models from Proposers, evaluate them using their local test datasets, and vote to support or reject the proposed updates.
The final global model for each round is determined based on the aggregated voting results, and rewards are distributed to each participant in the FL Alliance accordingly.
The finalized AI Arena consensus models or FL global models are then deployed to the AI Marketplace for use in various applications.
- by clearly establishing incentives and slashing criteria throughout the training phase (i.e., AI Arena) and the fine-tuning phase (i.e., FL Alliance) like this, many of the attack vectors mentioned in section 1.3 can be prevented.
For example, by requiring staking to participate in each phase and implementing a (PoS-based) incentive mechanism that increases penalties for malicious actions or distributes rewards proportionally based on contributions, the quality of training and validation can be controlled. This allows for protection against various model/data poisoning attacks and Sybil attacks.
Moreover, while the complexity of models required by each Task Creator may vary, ensuring adequate rewards for participation can attract a wide range of clients - even if the contribution is small, proportional rewards are provided. Additionally, beyond verification tasks that typically demand a higher workload, various other roles exist, allowing the network to create numerous incentives for participation.
Certainly, there are clear advantages to centralized AI models, and the fact that so many people around the world are using these models proves their value. However, as mentioned in the introduction, there is currently a lack of grounds to fully trust these centralized AI products, and they also carry potential concerns, particularly regarding privacy issues.
Moreover, our society is likely to continue becoming increasingly complex, moving toward embracing a wider range of values. In such a scenario, I believe that AI models tailored to the data generated in these diverse contexts should also emerge in various forms.
In this regard, the introduction of blockchain with incentive mechanisms, combined with federated learning methodologies, can serve as a powerful motivator to democratize the way traditional AI modeling is conducted. Of course, designing tokenomics to ensure that these incentives continue to provide attractive rewards for contributors, thereby maintaining network stability, is a crucial agenda in its own right. However, the significance of FLock.io's efforts lies in their potential to fundamentally address some of the inherent structural challenges associated with adoption on federated learning methodologies.
Related Articles, News, Tweets etc. :
Related People, Projects :
Flock.io
Dive into 'Narratives' that will be important in the next year