As the AI paradigm shifts toward data quality, the growing severity of model collapse and security threats caused by data contamination and black-box processing has highlighted the urgent need for a "Sovereign Intelligence Data Layer."
To address the inefficiencies of the legacy data labeling market, a team of Scale AI veterans secured $17.5 million in funding and introduced a Solana-based on-chain workflow. This innovation transparently records all work history on-chain and has achieved a breakthrough by reducing pipeline setup time by over 95%.
Perle Labs has successfully overcome the limitations of anonymous crowdsourcing through its expert-centric model, achieving significant results with 1.7 million tasks and 330 million points secured during the beta period. Building on this solid foundation, Perle Labs is set to dominate high-complexity data domains that synthetic data cannot replace, firmly establishing its own unique ecosystem.
In the early days of the AI industry, the prevailing belief was simple: “the more data, the better.” However, the landscape changed with the rise of large language models (LLMs) and sophisticated computer vision models. Scaling data volume alone eventually hit a plateau where performance improvements started to stall.
Source: YouTube (@DeepLearningAI)
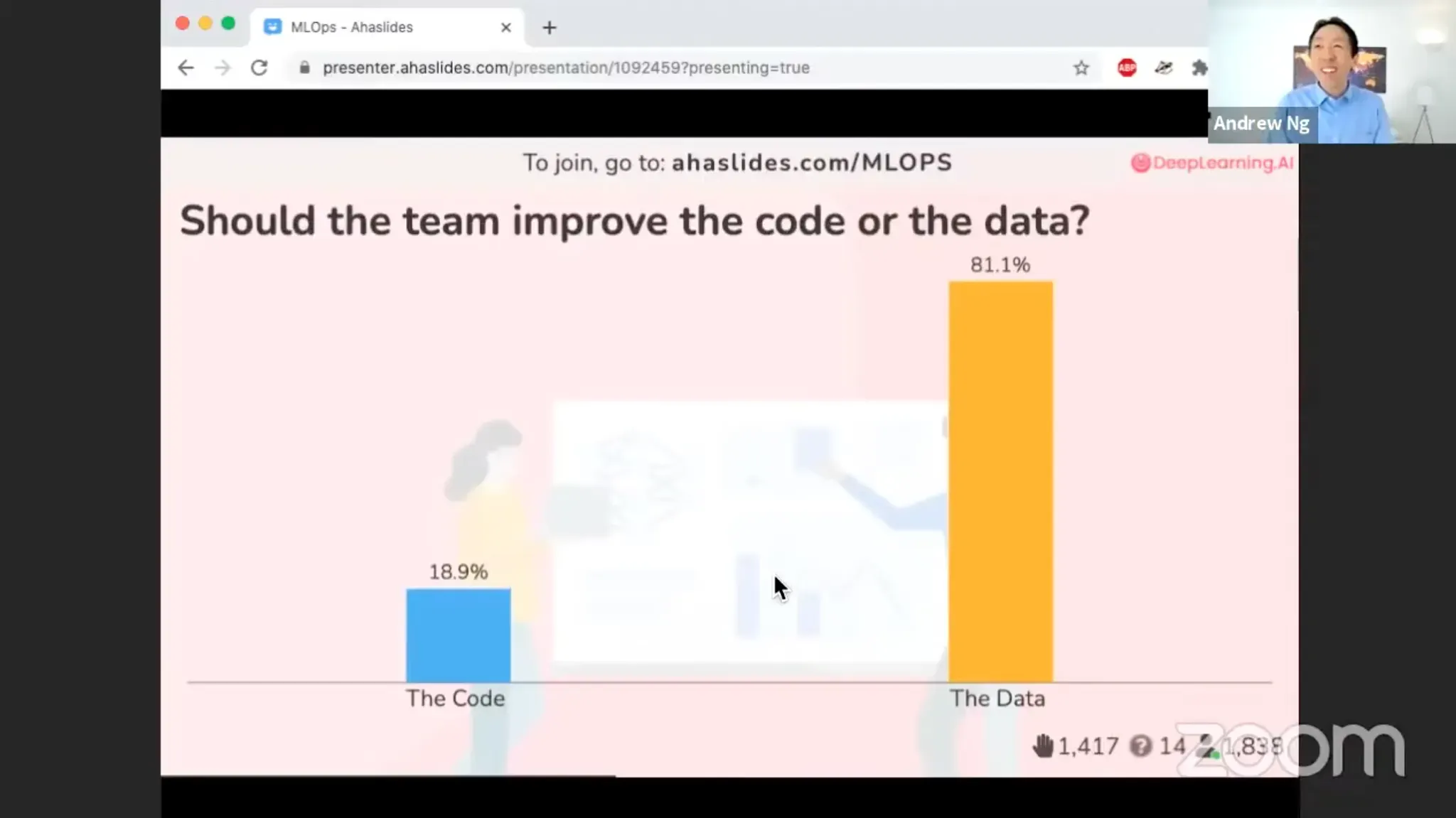
The importance of “data quality” has been raised consistently in the AI industry. In 2021, Andrew Ng pointed out in “A Chat with Andrew on MLOps: From Model-centric to Data-centric AI” that despite how much time teams spend on data collection, cleaning, and labeling, the industry still fails to treat these efforts with the seriousness they deserve. Companies may pour money into hiring AI researchers to improve models, but his argument was that the real key to performance lies in data quality. This line of thinking helped explain why data platform companies like Scale AI grew rapidly and gained attention.
These arguments remain valid in the era of generative AI, and have arguably become even more important. As small models have proven their capabilities at high speed, “what data you train on, and how you train on it” has become a larger determinant of performance. The hallucination problem we commonly see in LLMs also reinforces the importance of data quality. Perle Lab’s study reports that benchmark accuracy improved by more than 24 percent when a model was fine-tuned on expert-validated, high quality data instead of simply using large-scale data. The findings further support why high quality datasets matter.
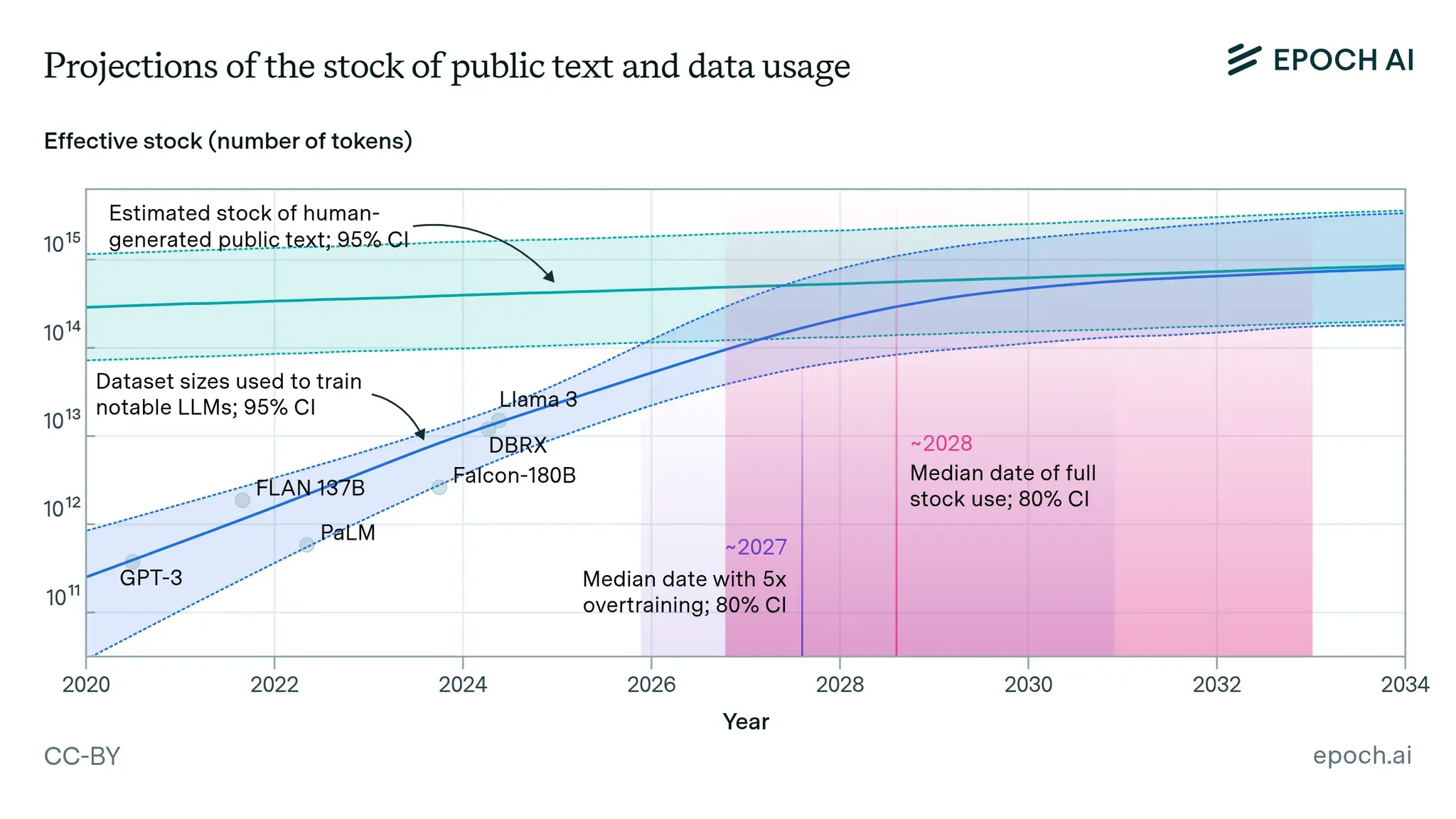
That said, high quality data still depends heavily on data produced by humans. A key concern is “model collapse,” where training AI on AI-generated data can cause the model’s capabilities to degrade over time. Meanwhile, the supply of high quality human-generated data is becoming more constrained due to exponential growth in data consumption needs, data scarcity, and early capture by big tech companies.
Source: Epoch AI
First, a supply shortage relative to demand is already underway. Some forecasts suggest that high quality, human-generated data could be depleted around 2026. As data sources become increasingly concentrated around major platforms, supply constraints may tighten further.
Second, because a significant portion of labeling work is run through crowdsourcing, it often becomes a black box. When data creation and review depend on anonymous workers with unclear identities, control over quality becomes harder. One study found that 33-46 percent of workers used LLMs extensively during labeling tasks. There is also the risk of noise being introduced when workers without domain expertise perform labeling.
To address these issues, the pipeline must become less of a black box, and data generation must be structured so humans can truly lead it. Perle Labs, founded by a team with Scale AI roots, built an on-chain data pipeline to move in that direction.
To secure high-quality data reliably, it is essential to avoid opaque black box pipelines and establish a structure where humans can proactively verify data generation. In other words, foundational systems are needed to transparently track the ownership and provenance of AI training data and verify who created it.
Building a “transparent data layer” will become even more critical going forward. AI is moving beyond simple task assistance into high-stakes decision-making in areas such as medical diagnosis, autonomous driving, and military operations. In these high-risk domains, the acceptable margin of error is effectively close to zero. This means the integrity of both model training and the underlying data becomes paramount.
Data integrity is now treated as a core national security issue. For example, DARPA’s GARD program has conducted multi-year research to defend AI against adversarial threats such as data poisoning and deception attacks. In addition, in May 2025, the NSA and CISA jointly warned that vulnerabilities in the data supply chain and maliciously modified data can critically threaten the integrity of AI systems. The fact that the U.S. Department of Defense’s Joint Artificial Intelligence Center (JAIC) signed a contract worth $249 million with Scale AI, a leading data labeling company, also suggests that contaminated data and black box systems are being recognized as serious security threats.
To address these issues, Perle Labs built a blockchain-based “Sovereign Intelligence Data Layer.” Through this, it aims to manage every step from data creation to utilization transparently and to provide trustworthy, high-quality data. Traditional data platforms rely on centralized cloud systems that operate like black boxes, while Perle Labs uses blockchain as an attribute layer to transparently manage and record the entire lifecycle, from data creation to usage. Instead of being locked into a single company’s private servers, data exists on-chain in a way that anyone can verify, helping ensure data sovereignty. Ultimately, the goal is to provide trustworthy, high-quality data on top of this foundation.
Perle Labs treats data quality as a non-negotiable priority. The company was founded by veterans who helped drive Scale AI’s success, led by Ahmed Rashad, who oversaw product and growth at Amazon and Scale AI. Rashad has direct experience designing and operating thousands of data pipelines, and he launched Perle Labs to fundamentally solve the opacity and inefficiency he saw firsthand in real-world data systems.

Source : X(@PerleLabs)
This vision attracted backing in a round led by crypto infrastructure firm Framework Ventures and AI/Web3-focused CoinFund, with participation from Protagonist, HashKey, Peer VC, and others, raising a total of $17.5 million. Similar to Scale AI’s success, which was reportedly valued at around $14.3 billion by Meta, the funding reflects a market view that Perle Labs has comparable growth potential through transparent blockchain infrastructure.
Through their own research, they warned about the paradox of intelligence that “AI evaluator” models can create, and the risk of cascading bias (model collapse). Based on the belief that quality control relying on a single AI model will inevitably hit limits, Perle Labs makes human expert involvement a core assumption. However, humans also introduce variability. Expertise differs by worker, and it is difficult to completely filter out “cheating,” such as secretly using AI. To control this uncertainty with technology, Perle Labs introduced a blockchain-based workflow.
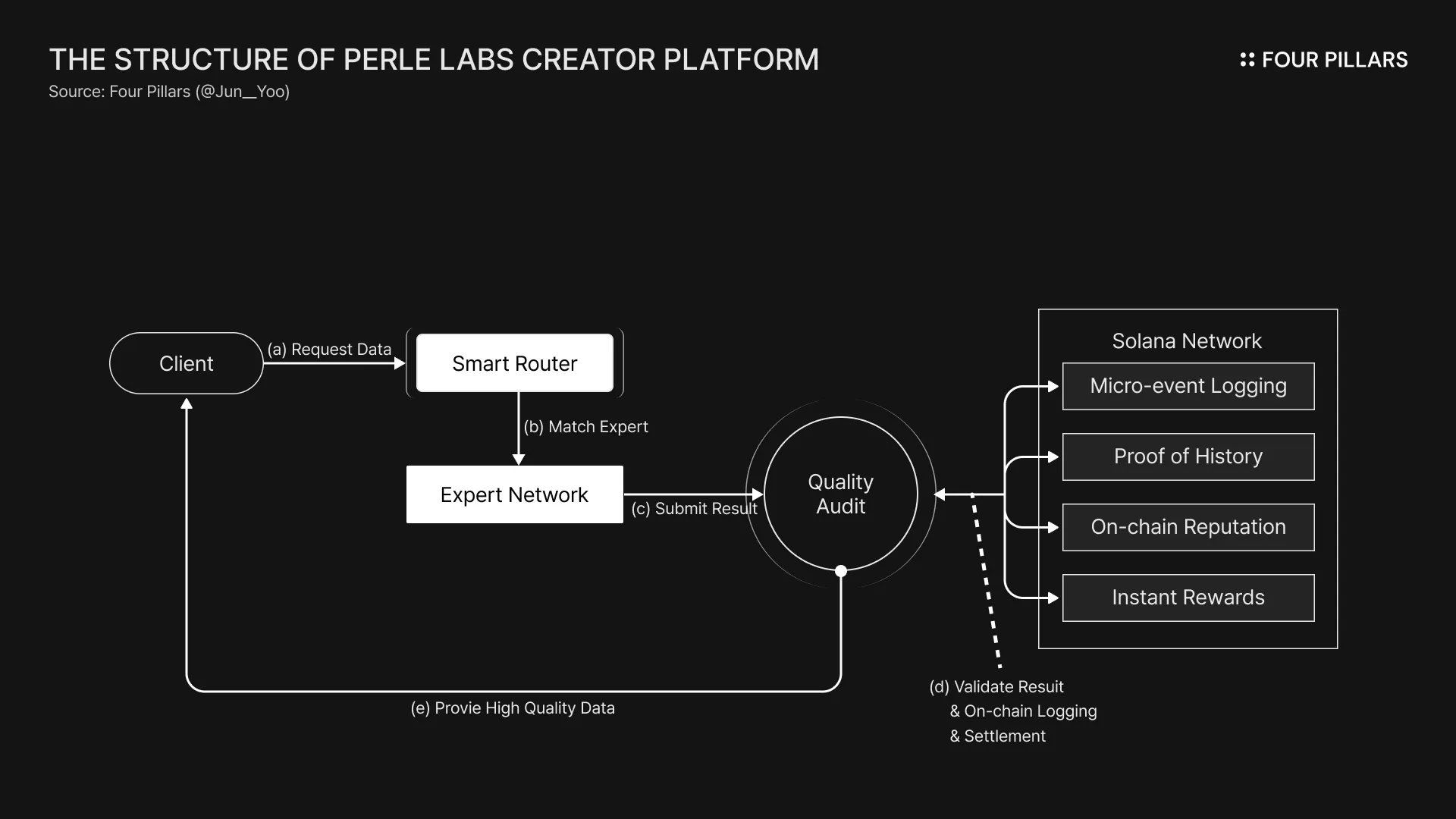
The diagram above shows how the client, the Perle platform, providers, and infrastructure connect organically to form an integrated platform that ensures data integrity. The core of this ecosystem is that every step of the workflow is recorded transparently on-chain, and those records power both a reputation system and a Smart Router that optimizes task distribution.
Based on the Perle Labs Creator Platform, the process operates as follows:
(a) Task Request: The client submits a task request to the Smart Router.
(b) Optimal Matching: The Smart Router connects the most suitable worker from the Expert Network based on the on-chain reputation system.
(c) Submit Result: The expert who performed the task submits the result to the Reviewer.
(d) Quality Audit: The Reviewer conducts an internal quality verification on the submitted result.
(e) Validate Result & On-chain Logging & Settlement: Integrated with the Solana Network, the result is validated, logs (including reputation) are recorded, and immediate reward settlement is executed simultaneously.
(f) Provide High Quality Data: The final validated high-quality data is delivered to the client.
Through this workflow, Perle Labs claims it has built a structure that can complete complex data pipeline setup in minutes, even when such setup used to take weeks. Next, we will look at why each component was designed the way it was, and how it works in practice.
The core purpose of introducing blockchain is to prove data integrity and enable micromanagement at scale. Traditional data labeling services can feel like a black box. Perle Labs records every stage of the pipeline on-chain, including data creation, labeling, review, and edits. This creates an audit trail that can transparently track who did what, when, and under what criteria.
The key challenge is how quickly and cheaply the system can process an enormous number of micro-events, potentially in the millions. This is where Solana comes in. Solana’s high throughput and low fees provide an environment well suited to updating verifiable event logs with low latency.
Source: Breakpoint 2025, YouTube (@Solana)
Solana’s high-speed infrastructure is also essential for implementing instant settlement and payouts immediately upon task completion. Perle Labs explains that its on-chain process reduces setup time by more than 95 percent and makes audits more rigorous, ultimately improving data quality significantly.
Once transparent records exist, the next question is: “Who should do the work?” Even the best pipeline will fail if validators lack capability. Perle Labs addresses this with an on-chain reputation system and a Smart Router. Instead of anonymous workers, the company manages more than 25,000 verified experts across 73 countries through on-chain reputation, with scores computed from three factors:
Accuracy: gold-standard tests and peer review outcomes
Consistency: long-term stability of quality
Contribution record: the difficulty and volume of completed tasks
This score is not just a public metric. It is a key input into the operating logic. The Smart Router reflects reputation scores in real time and automatically assigns the most suitable workers for each project. At the same time, rewards are designed to scale with task difficulty and accuracy, discouraging low quality work that is merely fast. In short, Solana-based micromanagement creates a foundation of trust, and the Smart Router runs that trust foundation efficiently.
For example, if a “chest X-ray interpretation” task is submitted, an administrator does not manually assign it. Instead, the router identifies a qualified medical contributor who has shown high accuracy on past medical data tasks and automatically routes the work to them. It also uses past performance to predict future performance and place talent more effectively. In short, micromanagement creates the trust foundation, and the Smart Router makes that foundation operate efficiently.
Perle Labs’ founder, who built data operations at Scale AI, emphasizes a clear thesis: models keep improving, but data remains the bottleneck. Blockchain-based attempts to resolve physical bottlenecks or inefficient resource allocation have already been explored across many areas, including Real World Assets (RWA), compute resources, telecommunications, and energy. These fall under the broader theme of Decentralized Physical Infrastructure Networks (DePIN).
In data labeling, there were also earlier attempts to combine blockchain with the data supply problem before Perle Labs. Perle Labs’ differentiation lies in combining an expert-centered design with an on-chain reputation system. While many projects tend to bias toward scaling volume, Perle Labs aims for a structure where accuracy and consistency accumulate into reputation, unlocking higher value tasks and stronger rewards.
This matters most in high difficulty, high risk domains like healthcare or law. In these cases, Perle Labs strengthens quality by assigning tasks through expert networks. For example, in a case study with Sully AI, Perle Labs brought in physicians who understand both medicine and AI to contribute to the dataset. The team argues that when domain-aware experts participate directly in the pipeline, they can handle edge cases and subtle professional nuances that are difficult for general labelers to capture.
This high-quality data strategy also expands beyond text into embodied intelligence, where AI interacts with the physical world. Perle Labs’ Whispermind platform collects multi-sensor data, including vision (RGB-D) as well as force and motion, to train robots to behave more like humans. This goes beyond simple image labeling by converting tactile signals into data, including grip strength and coefficients of friction, supporting highly demanding applications such as warehouse automation and precision surgical robotics.
Perle Labs’ strategy leans closer to choosing high quality over economies of scale. As a result, the biggest risk emerges if expert supply cannot be secured consistently. Experts are limited in number. Repetitive labeling work can reduce job satisfaction. In high risk areas like healthcare and law, it can be even harder to detect misconduct or declining diligence. Ultimately, the incentive design must compensate experts for their opportunity cost, and it must also stay balanced against the unit economics of producing data.
Another variable is the growing trend toward AI-led generation and review, such as synthetic data and Reinforcement Learning from AI Feedback (RLAIF). If these approaches rapidly improve in cost competitiveness, an expert-driven model may face pricing pressure.
In this environment, the strategic direction Perle Labs may need to pursue is capturing the category of “tasks only experts can do.” Beyond basic labeling, it must continue to secure work that is difficult to replace, such as ultra-hard decision-making and reasoning, safety and ethics judgment, and regulation-friendly evaluation. But this will not happen overnight. The team must find balance between incentives experts can accept and pricing the market can sustain. It also needs to accumulate operating experience, using on-chain records to verify whether quality can be maintained over long periods.

Source: X (@PerleLabs)
During the beta period in Q4 2025, Perle Labs secured meaningful traction, collecting 1.7 million tasks and 330 million points. These points are not just a number. They represent performance-based compensation calculated by algorithmically analyzing contributor accuracy, consistency, and task difficulty. The points may later be convertible into tokens, and they also function as a reputation metric that governs access to higher-tier work.
Accordingly, the Season 1 launch is framed as a final validation phase before full-scale expansion. The key goals are to confirm that the expert supply chain and reputation system work as designed, and to secure the operational stability required to handle high-difficulty data.
As AI models advance and human reliance on AI increases, demand for trustworthy, high-quality data is likely to grow structurally. A team with deep experience in large-scale data pipelines, now attempting to solve this problem through an on-chain workflow, may be an important signal at a moment when data supply structures are beginning to shift.
Dive into 'Narratives' that will be important in the next year