If we lay out the data ecosystem by the components in the pipeline, there are three things: the data source, which is the raw data; the coordinator, which provides the infrastructure and tools for retrieval; and the retrievers, who access the data.
As our previous article terms it, KYVE is the blockchain that solves blockchain problems related to data. The KYVE blockchain itself acts as a data coordinator, in this pipeline. It has a data source comprised of blockchains and tools for developers to help access them.
In this data ecosystem analysis article, let's examine the current landscape of these components and where they are headed.
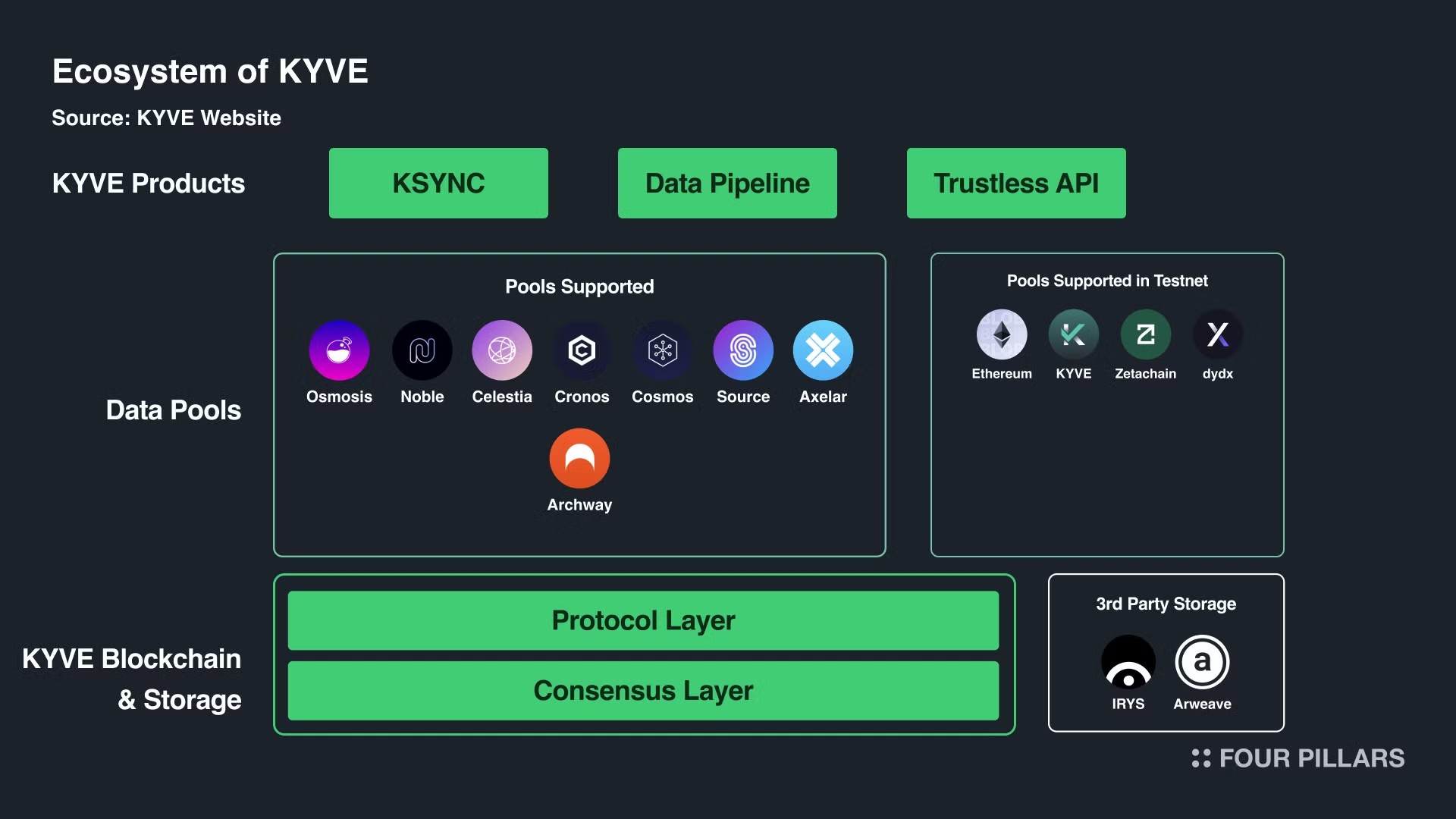
The data source in the KYVE data ecosystem primarily consists of “blockchain data”, including those within the Cosmos network. KYVE acts as a bridge between these data sources and the data storage solutions, enabling data validation and archiving through the products of KYVE.
KYVE's approach to handling data sources involves the use of data pools and protocol validators. These validators are responsible for collecting data from the source, bundling it, and uploading it to decentralized storage solutions.
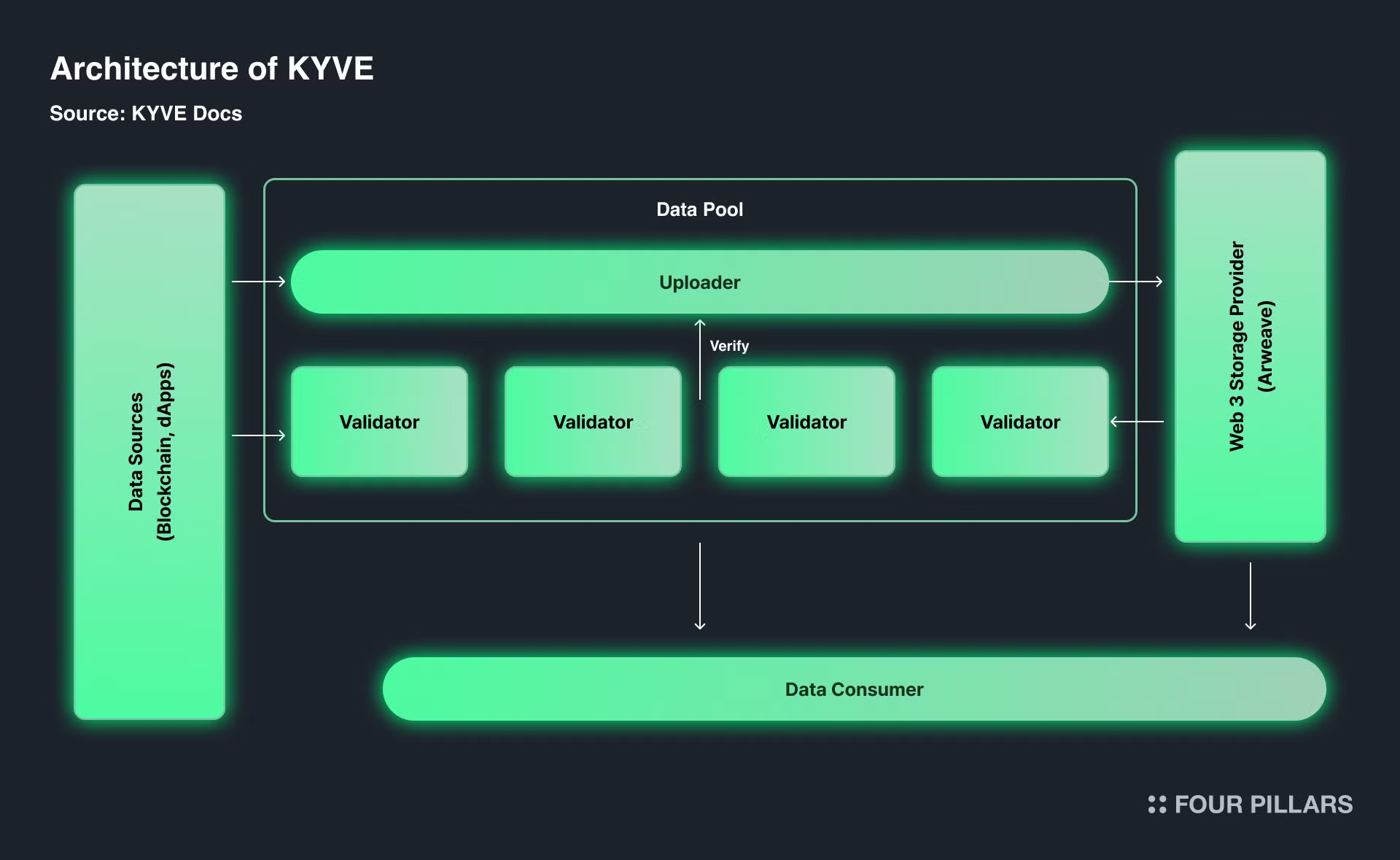
The KYVE L1 is essential for coordinating data storage by providing decentralized archiving and caching for other blockchains. KYVE's system turns data into "bundles" that are backed up on decentralized storage platforms. It uses 3rd party solutions like Irys and Arweave to store data permanently, ensuring it can be accessed whenever needed. This ensures data permanence and improves accessibility across different blockchains.
1.2.1 KYVE Blockchain - The Core Coordinating Infra
KYVE's infra is built as a L1 with the Cosmos SDK and has been built for its data storage coordination. KYVE aims to validate and store data streams on decentralized storage providers without needing trust. It uses its Proof of Stake blockchain with a network of data pools where the data is ultimately stored.
The data stored by KYVE is managed by Data Pools, which are entities focused on specific data sources. Anyone can create them through governance and store any data stream. They operate on-chain, making them completely trustless. These pools validate and archive data, allowing participants (protocol validator runners) to join and manage the validation process on-chain.
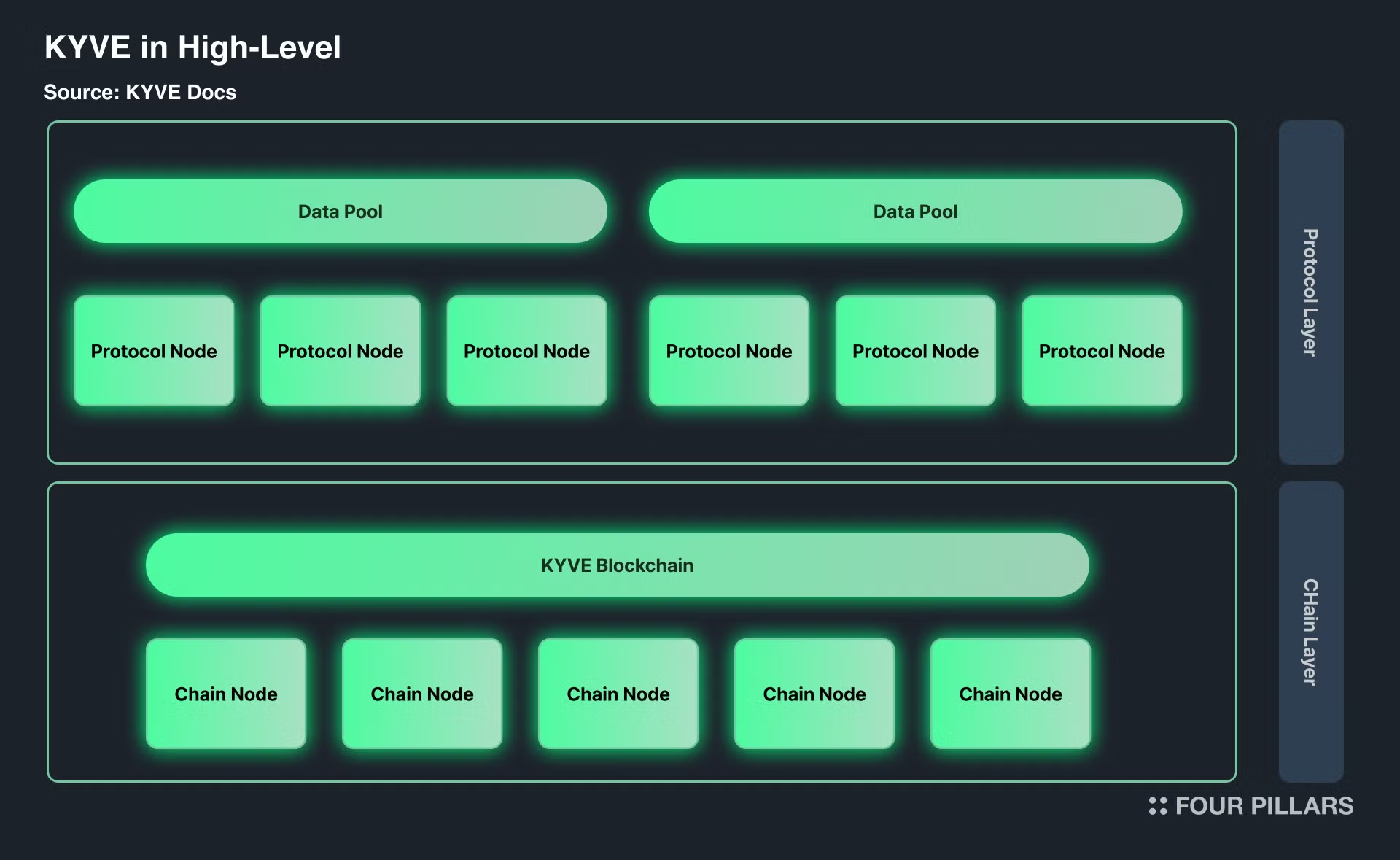
Source: High-level Overview | KYVE
1.2.2 Three Products - Tools to Access KYVE Data Pools
There are three products that simplify data retrieval from these pools:
KSYNC: With this tool, users can sync blocks and state-sync snapshots from the KYVE data lake directly into Cosmos blockchain nodes. KSYNC offers three key features for syncing Cosmos chains: Block-sync allows nodes to synchronize from the genesis block to the current live height, which is essential for archival node runners as historical blocks become scarce. State-sync enables synchronization from genesis to live height at specific intervals, overcoming previous limitations that required centralized providers. Height-sync combines both block and state-sync to quickly access any block height from genesis to live, a process that previously demanded significant effort and resources.
Trustless API: Users can connect their applications to verified and trustless historical node data within seconds using Trustless API, providing seamless access without any paywalls. This is a public goods built by the KYVE Foundation.
Data Pipeline: Users can sync and load validated KYVE data from blockchains into the users’ preferred database, such as BigQuery and Postgres, ensuring real-time updates and high efficiency with our lightweight CLI tool.

1.2.3 3rd Party Storage - Permanent storage for Blockchain Data
KYVE blockchain uses third-party storage solutions like Arweave to make data more accessible and permanent. This decentralized storage ensures data is always available, which is crucial for keeping complete historical records for analytics and app development.
Keeping large amounts of data directly on the blockchain can be expensive and inefficient. KYVE addresses this by storing data on platforms like Arweave, reducing costs for validators and developers. This method also helps manage the large data output of fast blockchains, improving scalability.
KYVE simplifies data by creating bundles and storing them on Arweave, ensuring easy access and continuous verification of data accuracy. This process helps new validators join the network by reducing the amount of data they need to handle. Additionally, KYVE ensures data remains reliable and accessible across decentralized storage platforms.
The KYVE blockchain data ecosystem primarily supports data retrievers, including node operators, dapp developers, and data analysts. These users access and utilize the data stored and validated by the KYVE network.
Node operators are particularly significant as they need to access the seamless synchronization and retrieval of historical blockchain data. The primary product used by node operators is KSYNC, which allows node operators to rapidly sync nodes to any historical block, state, or height of a chain, ensuring that data retrieval is efficient and reliable.
Developers and data analysts also benefit from KYVE's data retrieval capabilities. KYVE offers a trustless API, enabling developers to connect their applications to KYVE's validated historical data quickly and securely. This API facilitates the integration of KYVE's data into various analytics platforms, allowing data analysts to perform comprehensive analyses without the need for complex data sourcing processes.
KYVE doesn't have significant direct competition with a similar architecture but faces competition from two main parties.
Centralized providers such as Alchemy and DSRV's allthatnode offer infrastructure services that include historical data storage and access. These centralized services often provide comprehensive support, which can be attractive to developers and enterprises seeking to retrieve data, however, these providers have centralization risk.
Individual validators also serve users by providing historical node data through their websites. This is done by several validators as a public good.
As of the writing of this article (August 21, 2024), KYVE’s mainnet has been live for just over 15 months. In this period, KYVE has archived approximately 6TB of data and processed 57 million transactions. This growth demonstrates a substantial demand for services like KYVE's.
Despite its achievements, KYVE currently has integrated only Cosmos-based blockchains. Let’s look into some of KYVE's metrics.
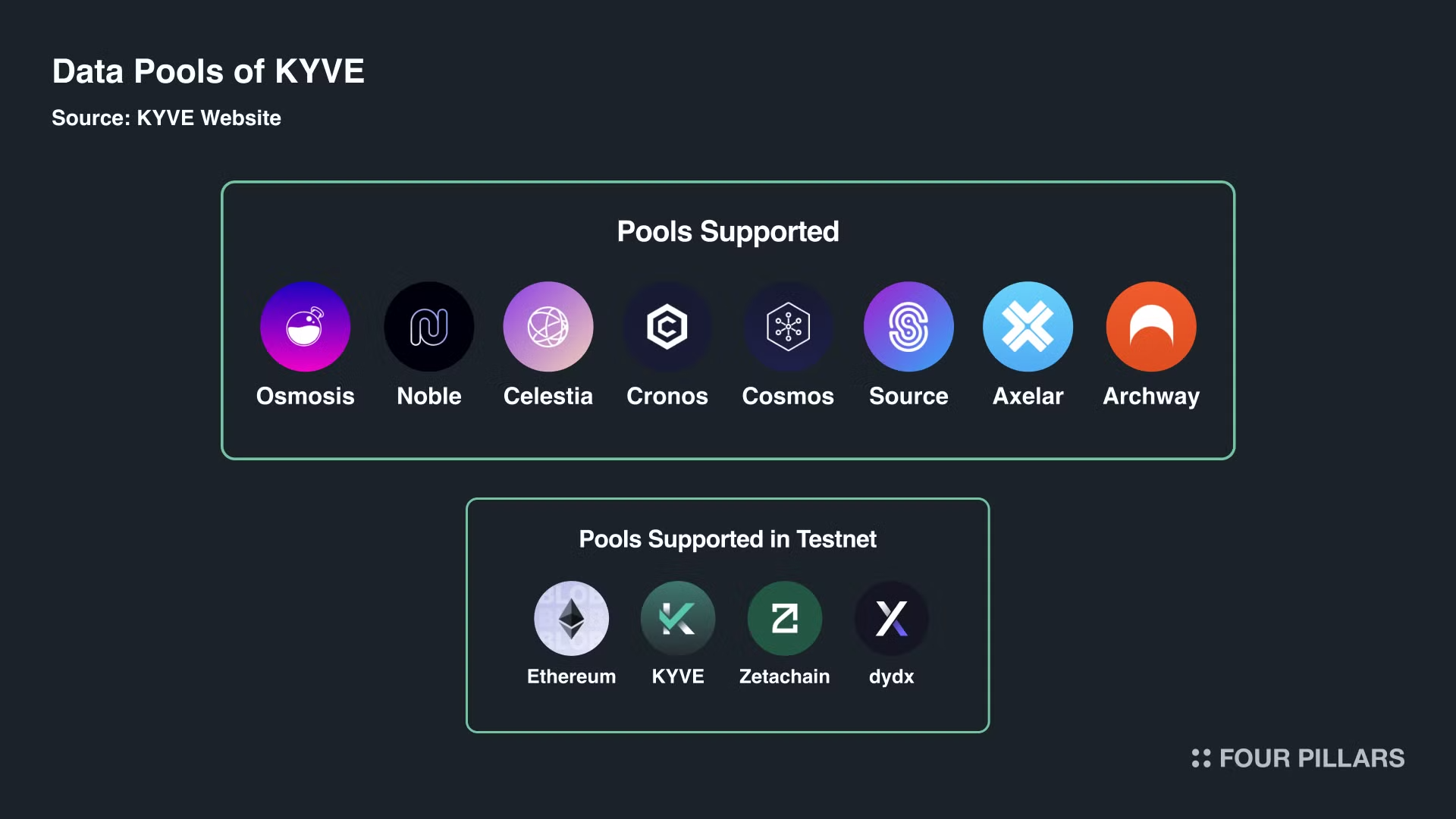
2.2.1 Number of Data Pools Supported
Eight pools are now live, and testnet support is coming for Ethereum, dYdX, ZetaChain, KYVE, and others. Testnet support means all tools are functional, though data isn't yet stored on decentralized platforms.
Considering the current number of L1 and L2 blockchains, KYVE's market penetration is not high. There are around 57 Cosmos blockchains, other alternative L1s, and hundreds of L2s set to launch later this year. The team has potential to support blockchains with high demand for decentralized data from full nodes.
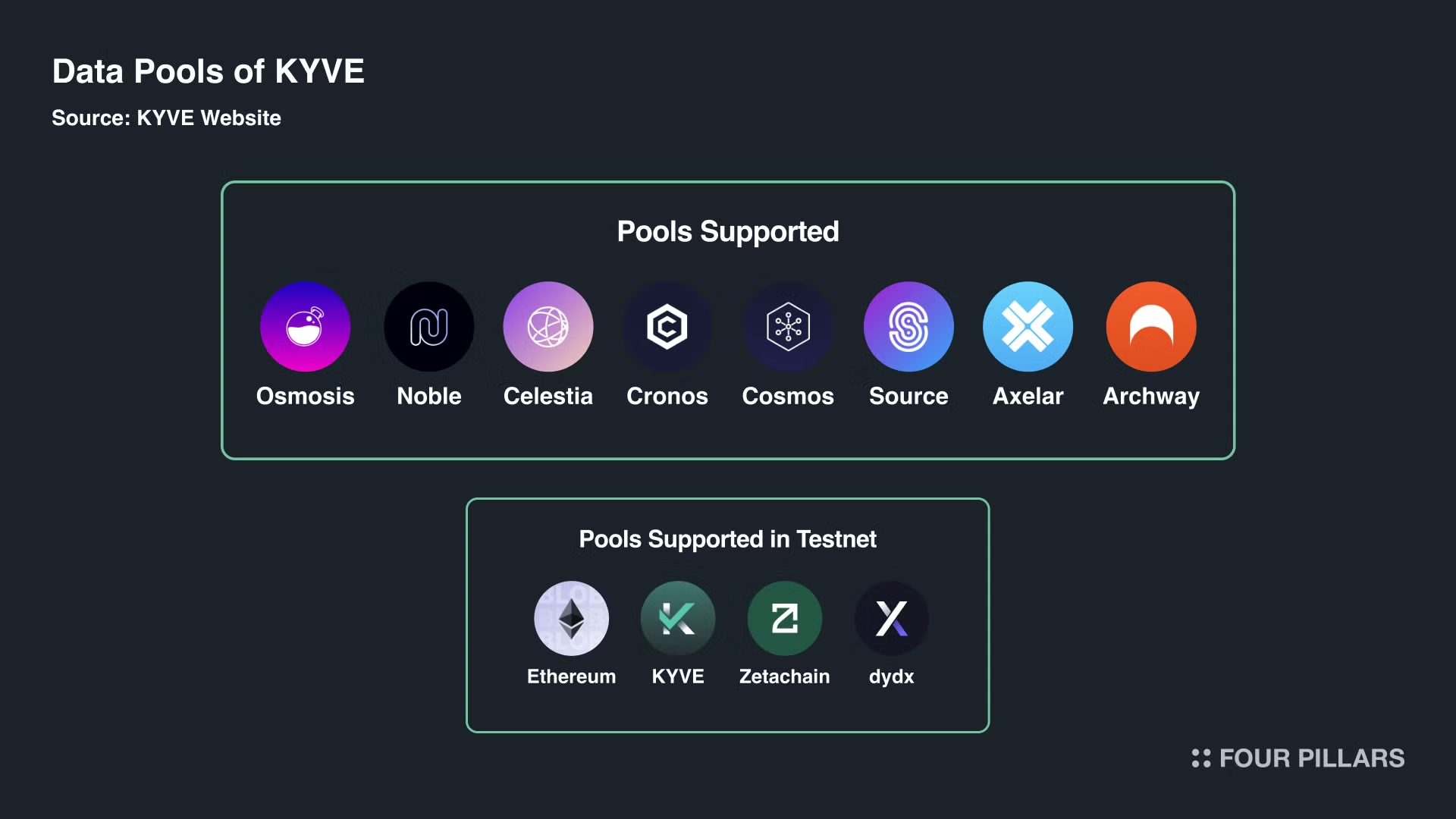
Source: The KYVE Data Ecosystem
2.2.2 Current Usage - Number of Bundles Created
In the KYVE blockchain, the term "bundles created" refers to the process of aggregating and storing data in bundles in data pools. The process of creating bundles involves several steps, including data collection, validation, and storage on permanent data storage solutions like Arweave. This metric denotes the current usage of KYVE.
The below graph illustrates a steady increase over time, which shows growing activity or adoption on the KYVE network. The consistent increase in bundle creation indicates a rising demand for KYVE's services, possibly driven by new projects or partnerships leveraging its technology for decentralized data management.
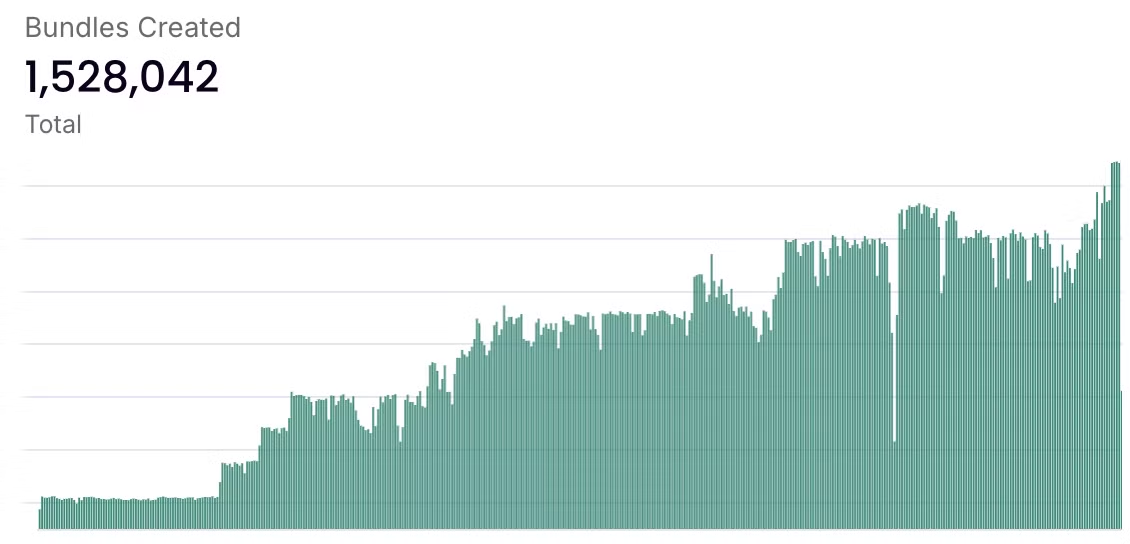
Source: KYVE - Activity
“Since its launch, KYVE has doubled down on specializing in supporting the Interchain. However, with our data solutions being so customizable, we’re ready to expand and support other ecosystems to provide better data tooling to all devs in Web3, starting with EVM.”
Related Articles, News, Tweets etc. :
Dive into 'Narratives' that will be important in the next year