AI is like the modern-day fire of Prometheus. It will bring tremendous benefits and wealth to humanity, but we must manage it carefully to minimize the negative side effects during its development.
One of the representative side effects caused by AI technology is the issue of data privacy. Since the training and inference of AI models inevitably involve sensitive information such as personal data, Nillion addresses this problem by utilizing encrypted data computation technology and blockchain, enabling users to safely protect and use their data.
The Nillion team is one of the few teams in the crypto industry with outstanding backgrounds in both business and research. Leveraging its aggressive business strategy and strong research capabilities, Nillion aims to build the blind computing layer of the internet.

When Prometheus stole fire from the gods and brought it to humanity, mankind came to possess both the light and the darkness of civilization. That flame gifted us with civilization, but at the same time, incurred the wrath of the gods, leading Prometheus to suffer eternal punishment.
If someone asked me what the most important technology for humanity's future is, I would answer without hesitation: AI. Of course, essential industries and technologies related to food, shelter, health, and energy are crucial, but AI stands out as the core technology because it can accelerate progress in all areas at an unprecedented pace.
This is already being proven by the current scale and rapid development of the AI industry. Since the launch of ChatGPT in 2022, the spark of the AI industry shows no sign of dying out. While estimates vary by research institute, the AI market is projected to have grown to hundreds of billions of dollars by 2024, just two years after ChatGPT’s debut. It is expected to reach several trillion dollars by 2030. Notably, OpenAI recently announced a $40B funding round, once again proving how vast and fast-growing the AI industry has become.
Big tech companies such as Google, Meta, Microsoft, and Amazon are pouring historically unprecedented amounts of investment into various areas related to AI such as algorithm development, server expansion, electrical infrastructure, and more. Beyond the corporate level, AI is becoming a national strategic priority. The development of AGI may very well determine the next global superpower. The current AI race between the U.S. and China is reminiscent of the arms race during the Cold War.
However, with every technological advancement comes both light and shadow. No matter what kind of technology it is, side effects tend to follow in its wake. The developers of CFCs likely never imagined they would destroy the ozone layer, and nuclear physicists probably didn’t foresee the death toll of atomic bombs.
AI is no different. While it promises tremendous productivity and wealth for humanity, this assumes we can control it effectively. One of the most frequently cited side effects in the AI development process is data privacy.
To train AI models, massive data collection is required—much of which includes personal or sensitive information. If developers fail to take privacy seriously, it not only raises ethical concerns but also risks legal penalties for violating regulatory compliance. That’s why major tech companies explicitly disclose how they manage and use customer data when developing AI models.
However, what’s particularly noteworthy is that companies developing large language models (LLMs)—like OpenAI, Google, and Anthropic—collect user-provided input, uploaded files, and feedback to improve model performance. Although users can opt out of data sharing or request deletion, the default behavior is for user interaction data with LLMs to be utilized by the companies—something many people remain unaware of.
In fact, in March 2023, Italy’s data protection authority temporarily suspended ChatGPT, citing potential violations of privacy regulations and began an investigation. More recently, multiple countries have restricted or banned the use of DeepSeek (developed in China) as a privacy protection measure.
While the aforementioned companies are relatively good at following privacy policies, issues remain. First, companies might misuse customer data. Second, even if they manage data properly, there’s always a risk of single-point failures such as data leaks.
A prominent example of the first case is the Cambridge Analytica scandal. In 2018, the British consulting firm Cambridge Analytica collected the personal data of millions of Facebook users without consent and used it for political campaigns. This incident showed how AI-powered data analysis could profile political tendencies and influence elections, creating widespread controversy.
An example of the second case is the ChatGPT data breach. In March 2023, due to a system bug, some users' chat titles and billing-related personal information were exposed to other users. This was one of the triggers for the aforementioned investigation by Italy’s data protection authority.
As such, AI data privacy is not an issue that can be overlooked for the sake of industrial advancement—it is a critical element tied not only to individual security but also to national security.
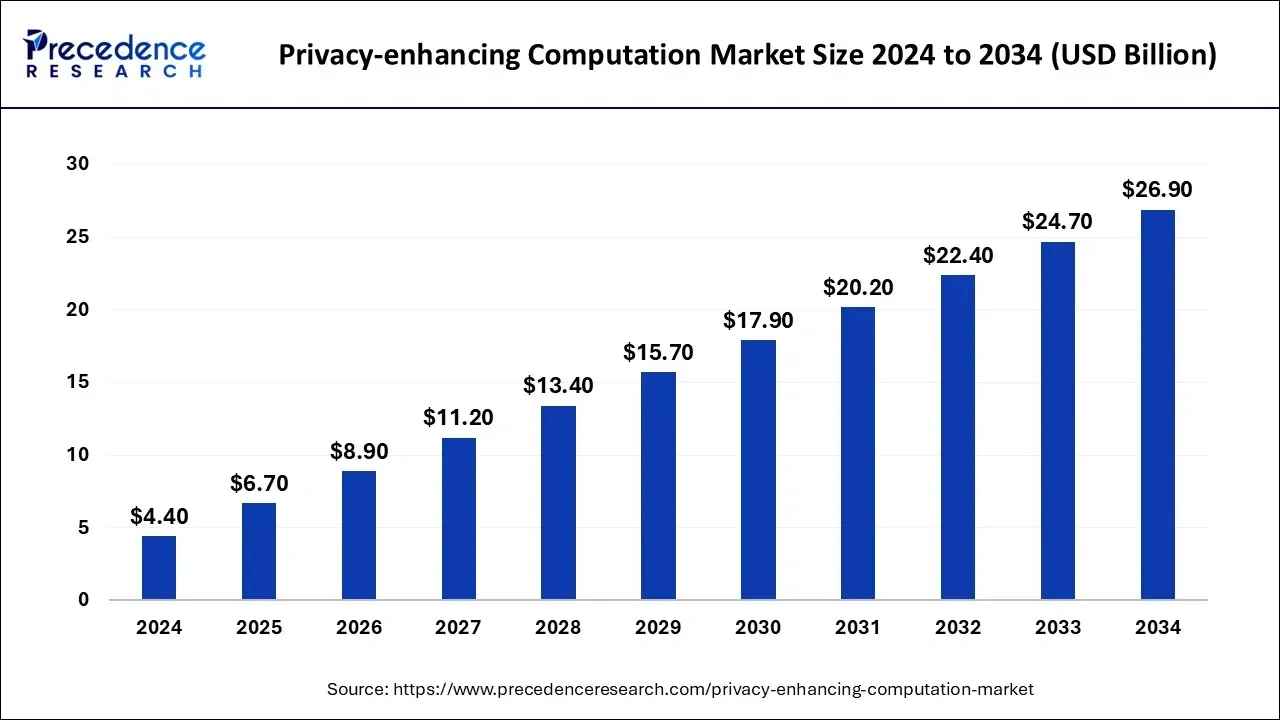
Source: Precedence Research
As the AI industry continues to receive massive attention and investment, the demand for AI data privacy is also rising rapidly. According to Precedence Research, the market for privacy-enhancing computation technologies—such as homomorphic encryption, MPC (Multi-Party Computation), and federated learning—is expected to grow from approximately $4.4 billion in 2024 to around $26.9 billion by 2034, with an average annual growth rate of 19.9%.
Looking back at the history of science and technology, we often see that in the early stages of technological development, capital is invested primarily to maximize utility. However, once the technology matures, industries aiming to mitigate the side effects (e.g., global warming) begin to grow rapidly. In this context, the privacy protection solution market is poised to become even more important going forward. Experts predict that privacy-preserving technologies will soon become essential for earning trust in AI services, driving continued high growth in this sector.
Before looking into specific technical solutions for data privacy, let’s first examine the policies and initiatives that governments are implementing in this area. These examples underscore the growing importance of data privacy in the AI industry.
EU AI Act: Taking effect in part in August 2024, this is the world’s first comprehensive AI legislation. It aims to promote safe and trustworthy AI while respecting fundamental rights and ethics. The Act classifies AI systems based on risk levels and imposes strict requirements—such as data governance, transparency, and security—for high-risk AI applications like healthcare and education.
OECD AI Principles: In 2019, the OECD adopted its AI principles by consensus among all member countries, and updated them in 2024 to reflect the latest technological developments. As the first intergovernmental guidelines on AI, these principles promote innovative development while emphasizing the need to respect human rights and democratic values. Notably, the principles explicitly mention privacy and data protection under human-centered values and fairness, stressing that AI systems must not infringe on individual privacy.
However, such laws and policies alone cannot fundamentally solve the problem of data privacy. So the question remains: Have there been technological attempts to address this issue?
1.5.1 Federated Learning
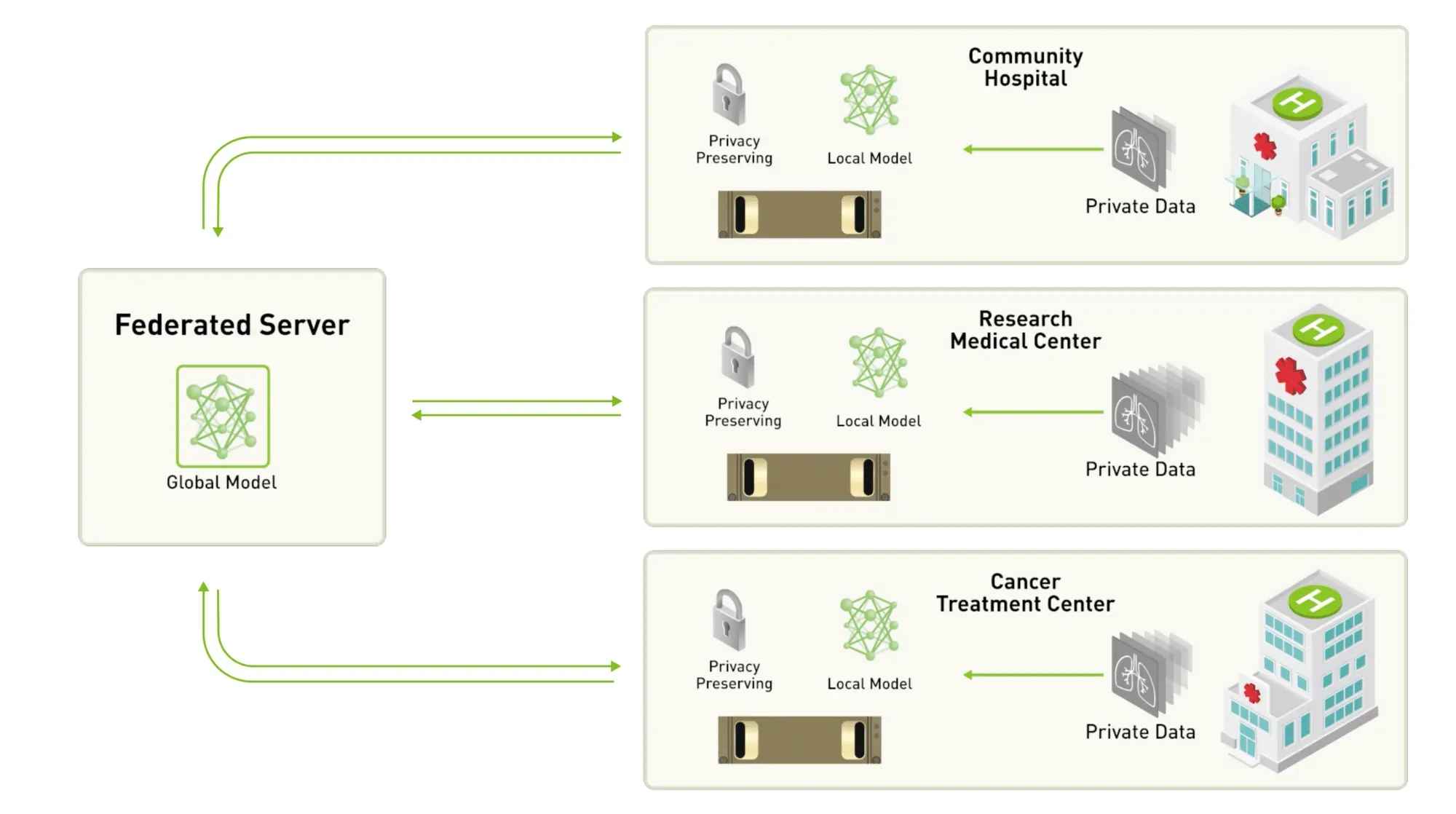
Source: Nvidia
Federated learning is a distributed learning algorithm that trains AI models while keeping data on users’ local devices. Since the data remains local, it is protected from being misused by centralized entities or leaked from central servers, thereby ensuring data privacy.
How it works:
The central server sends an initial model to clients (e.g., smartphones, hospital systems).
Each client updates the model locally using its own data.
Only the updated model parameters are sent back to the central server.
The server aggregates updates from multiple clients to refresh the global model.
This process repeats several times.
Real-world examples include Google’s Gboard and Nvidia’s Clara. Gboard provides personalized word suggestions and auto-completion based on typing habits. Because keyboard input data is highly sensitive and personal, training happens on the user's device, and only the updated parameters are sent back. Nvidia’s Clara enables hospitals, research institutions, and companies to collaboratively build and use AI models with sensitive healthcare data—without any actual data being shared between institutions, enabling multi-party collaboration without compromising privacy.
Despite its benefits, federated learning has some downsides. There are communication costs involved in transmitting model parameters between the server and clients, local computation can be burdensome for mobile devices, and since data is decentralized, it can lead to reduced model quality. Privacy may also be a concern in federated learning because model updates can inadvertently leak information about local data
1.5.2 Differential Privacy
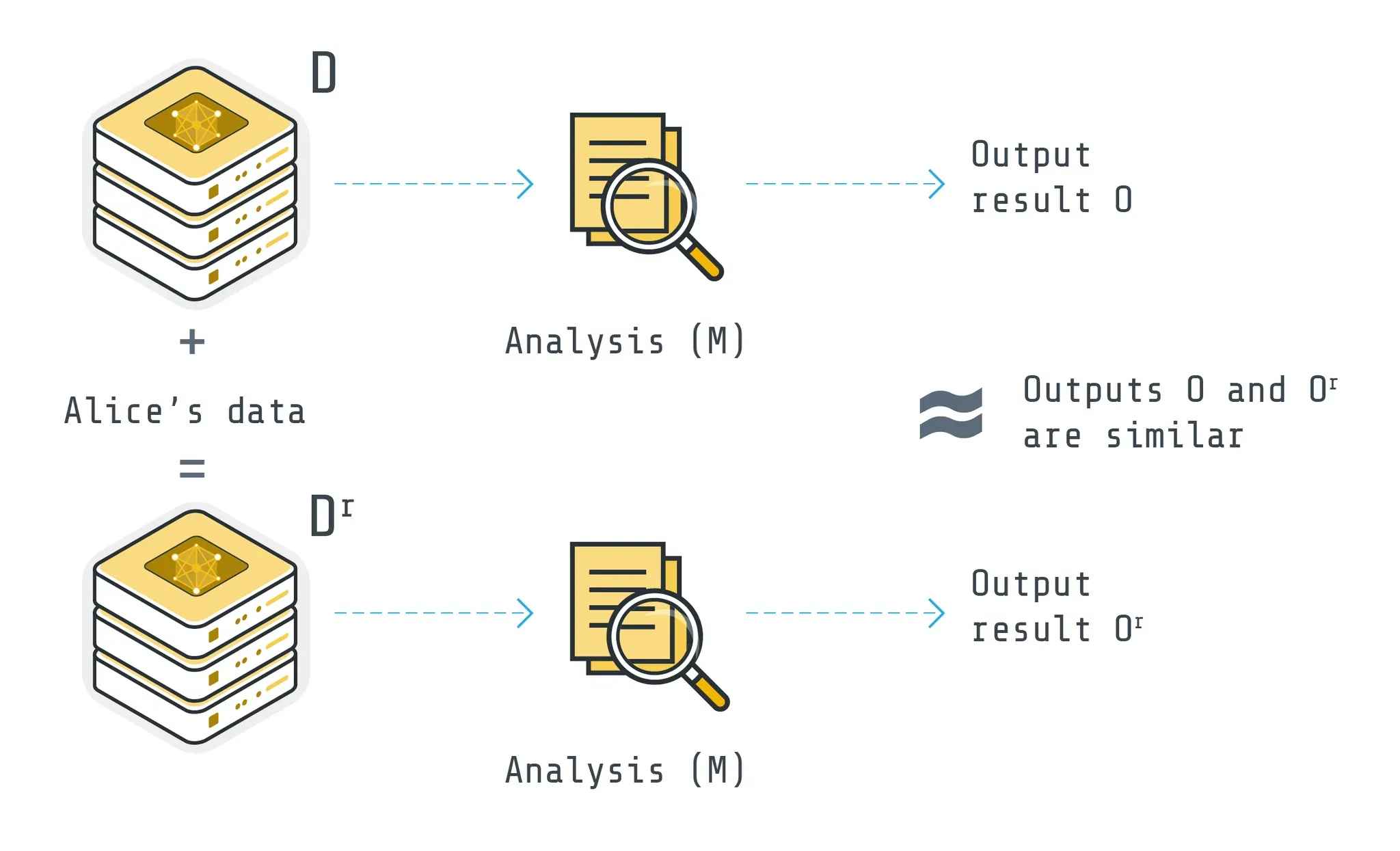
Source: flower.ai
Differential privacy is a mathematical technique that adds noise to data so that the inclusion or exclusion of any single individual’s data has minimal impact on the results. By intentionally introducing small random variations to model outputs or query responses, it prevents the identification of specific individuals' data contributions—thus preserving privacy while maintaining much of the data’s utility.
For example, imagine implementing differential privacy in a map service. If a user is actually located at a Starbucks, differential privacy would modify their location slightly—sending a nearby café or alternative spot to the server. While the precise location of each individual becomes obscure, aggregate insights such as foot traffic volume in the area remain valid. Differential privacy began to be adopted in commercial services in the late 2010s. Apple used it for collecting iOS usage statistics, and the U.S. Census Bureau used it to protect privacy in the release of census data.
Recently, there have been growing efforts to apply differential privacy to LLMs. Since 2024, various academic papers (e.g., “Fine-Tuning Large Language Models with User-Level Differential Privacy” and “Mind the Privacy Unit! User-Level Differential Privacy for Language Model Fine-Tuning”) have been published. Google has also adopted differential privacy in its LLM inference process to generate synthetic data while protecting sensitive information.
However, differential privacy has some drawbacks. Because it introduces noise to the data, it can reduce accuracy and generalization capability. It also requires additional computation to add the noise, and most importantly, tuning the appropriate level of noise is technically challenging—making real-world implementation difficult.
Earlier, we looked at technologies like federated learning and differential privacy for protecting data privacy. However, one of the most important solutions has yet to be discussed—computational methods based on cryptography. These allow AI models to train and make inferences using encrypted data. Key examples include ZK, MPC, TEE, and FHE.
ZK (Zero-Knowledge Proofs): A cryptographic method that enables one party to prove the validity of a statement without revealing any actual information about it.
MPC (Multi-Party Computation): A cryptographic protocol that allows multiple parties to jointly compute a result without sharing their individual data.
TEE (Trusted Execution Environment): A hardware-based technology that securely executes code and data within a protected area of the processor.
FHE (Fully Homomorphic Encryption): A method that enables computations to be performed directly on encrypted data, where the decrypted result is identical to that of computations on the original plaintext.
These technologies are gaining attention as core solutions for AI data privacy because they allow computations to be performed without exposing users’ sensitive or critical information during model training and inference.

Source: Nillion
Earlier, we explored how cryptography can be used within the AI industry to securely manage and compute data. However, cryptography alone is not a perfect solution for AI data privacy. Even if an LLM service provider claims to use cryptographic techniques to manage and process user data, if all of this is happening on centralized servers, users have no way to verify it. In other words, users must fully trust the company that their data is being securely handled—regardless of whether cryptography is used.
There is a simple way to solve this issue: introduce web3 technology. As a decentralized and verifiable database, when blockchain is combined with encrypted data computation technologies, it can become a trusted platform for AI data processing.
Through decentralized infrastructure, users can transparently monitor and verify whether their data is being securely managed and processed. Servers that perform computations using cryptographic techniques based on user requests can also receive fair incentives according to their contributions. This is the direction Nillion aims to pursue.
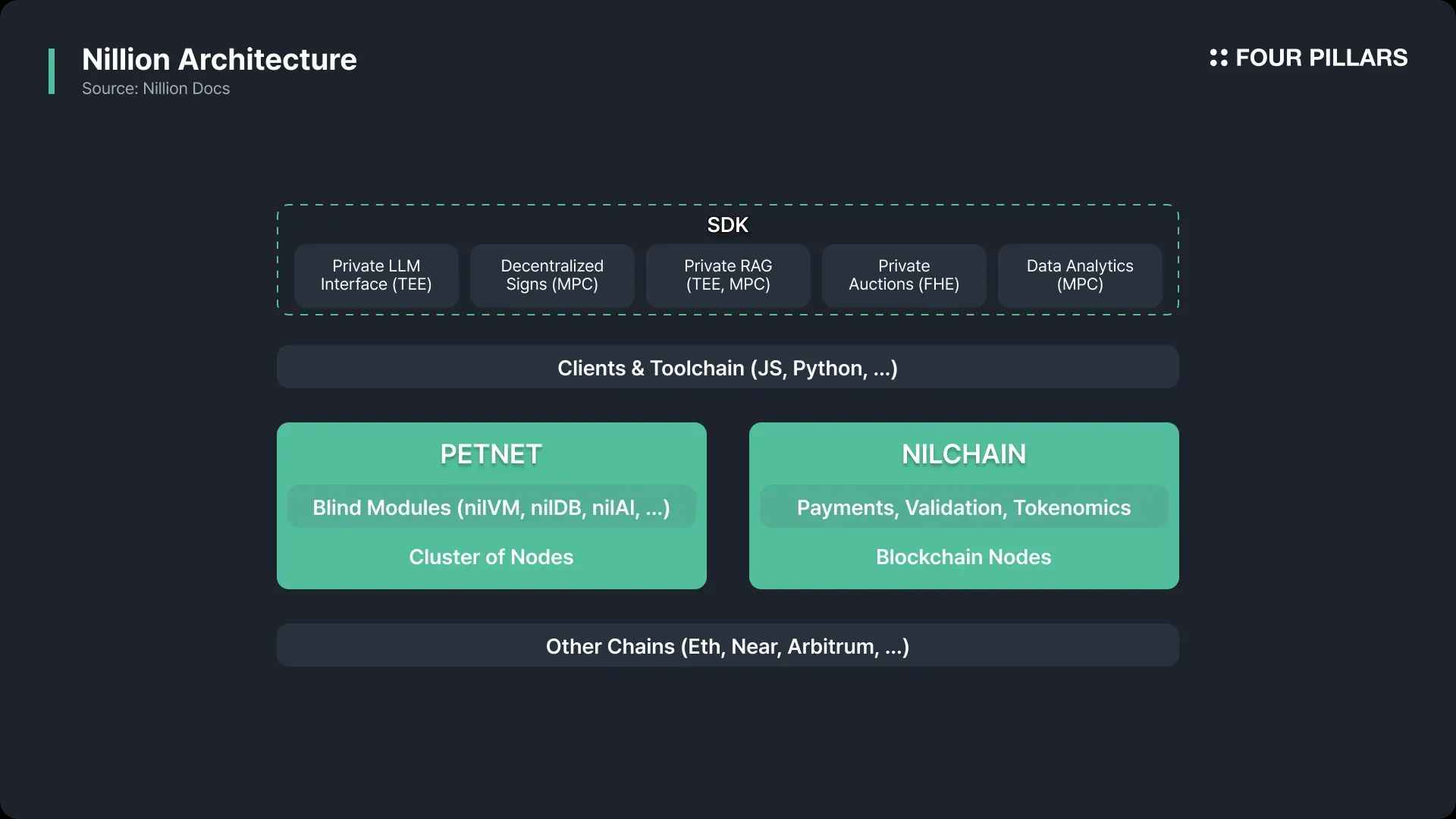
Nillion’s architecture is composed of two main components: Petnet and NilChain.
Petnet is a network of decentralized nodes that receive user requests, encrypt data, and perform & verify computations (but it is not a blockchain).
NilChain is a blockchain built on the Cosmos SDK. It performs functions such as recording transactions, handling payments among participants, and governance.
It’s similar to how IPFS provides decentralized file storage, while Filecoin manages governance, incentives, and verification on top. In the same way, Nillion’s Petnet handles the actual encrypted computation and storage tasks, while NilChain serves as the blockchain layer that offers transparency, immutability, decentralization, and security.
For more details about Nillion, you can refer to Steve’s article:“The Most Important Infra of AI Agent Personalization: Nillion”.
In this piece, we’ll go deeper into the background of the Nillion team and their core technologies.
2.3.1 Key Team Members
Andrew Masanto (CSO): A serial entrepreneur who co-founded two unicorn startups—Hedera Hashgraph and Reserve Protocol.
Alex Page (CEO): A former Goldman Sachs financial expert with co-founding experience in Sports Food Nutrition and the healthy snack brand Weekday Warriors.
Miguel de Vega (Chief Scientific Officer): A tech expert in blockchain, cryptography, and machine learning, with over 30 patents in data optimization and security. He is the mathematician behind Nillion’s core technology.
Conrad Whelan (Founding CTO): One of the founding engineers of Uber, currently leading Nillion’s engineering team.
Andrew Yeoh (CMO): Former analyst at UBS and Rothschild Investment Bank. He co-founded a fitness food startup with Alex Page and was an early contributor to Hedera Hashgraph. At Nillion, he drives marketing strategy and ecosystem expansion.
Mark McDermott (COO): Former CEO of digital media startup GoShow and former head of partnerships at Nike's European innovation team.
2.3.2 Core Technologies
The Nillion team is one of the few in the crypto space with exceptional achievements in both business and academia. Leveraging its strong business background, the team has continuously published academic papers in cryptography and AI.
From 2023’s “Technical Report on Decentralized Multifactor Authentication” to more recent work like “Wave Hello to Privacy: Efficient Mixed-Mode MPC using Wavelet Transforms”, Nillion has consistently contributed research across AI, cryptography, and privacy.
Technical Report on Decentralized Multifactor Authentication (Link)
To protect sensitive data like medical records or financial transactions, decentralized authentication systems—where data is stored across multiple nodes—are essential. Traditional centralized authentication poses single-point-of-failure risks. While MFA (multi-factor authentication) strengthens security using passwords, mobile devices, or biometrics, Web3 ecosystems relying solely on private key ownership require additional factors.
This paper presents a decentralized MFA protocol based on MPC. By minimizing communication between servers and supporting a wide range of authentication methods (passwords, biometrics, email, phone, blockchain wallets), it reduces user wait time and increases security without exposing user data.
Technical Report on Threshold ECDSA in the Preprocessing Setup (Link)
While threshold ECDSA is widely used, it’s still vulnerable to single-point failures and collusion by malicious signers. Nillion proposes a new protocol using:
A hybrid client-server approach where the client sends the message, and signers use preprocessed encrypted data to generate the signature.
MPC techniques allowing signers to compute with only their key shares and verifying with the client’s encrypted secret key—making collusion ineffective.
More Efficient Comparison Protocols for MPC (Link)
Comparison protocols allow two parties to compare secret values without revealing them. Traditional protocols are communication-heavy and degrade with increased bit input. Nillion improves this using shifted bit decomposition and prefix multiplication for higher performance.
Technical Report on Secure Truncation with Applications to LLM Quantization (Link)
Truncation reduces number precision during computation to save memory in AI models. Traditional methods require excessive bits for security, which paradoxically slows down computation. Nillion proposes a new MPC-based technique that ensures security while reducing computational complexity.
Ripple: Accelerating Programmable Bootstraps for FHE with Wavelet Approximations (Link)
FHE is limited to addition and multiplication, making non-linear function computations difficult. Lookup tables help, but they become inefficient with increased input bit size. Nillion and the University of Delaware introduce Ripple—a framework that uses discrete wavelet transforms to compress lookup tables while maintaining high accuracy.
Curl: Private LLMs through Wavelet-Encoded Look-Up Tables (Link)
As mentioned earlier, LLMs face serious data privacy issues. Applying MPC helps but introduces errors and communication overhead during non-linear approximations. Collaborating with UC Irvine and Meta, Nillion presents Curl, which also uses discrete wavelet transforms to compress lookup tables and perform non-linear approximations efficiently.
Wave Hello to Privacy: Efficient Mixed-Mode MPC using Wavelet Transforms (Link)
Similar to the Curl paper, this research applies discrete wavelet transforms to MPC to achieve high-precision evaluation of commonly used non-linear functions in machine learning.
Just as Prometheus brought both the light and darkness of civilization to humanity by giving us fire, AI offers extraordinary innovation and wealth, but also casts a shadow of uncontrolled data privacy risks. With its exceptional team and cutting-edge research, Nillion aims to illuminate a path to a safer, more transparent AI era through the power of cryptography and blockchain.
Related Articles, News, Tweets etc. :
“The Most Important Infra of AI Agent Personalization: Nillion” by Four Pillars
Dive into 'Narratives' that will be important in the next year