Today, Anthropic released the results of attack simulations on smart contracts not included in training data. Anthropic's Opus 4.5 model achieved remarkable results, successfully reproducing $4.6 million worth of attacks with a 50% detection rate.
However, the impact of each detected vulnerability fell below average, likely due to improved security maturity compared to the past and repetition of previously discovered vulnerabilities. Nevertheless, the fact that AI understood business logic rather than simple pattern matching, found vulnerabilities in code absent from training data, and wrote exploit code in a single attempt represents a highly meaningful advancement.
The actual cyber attack capability of LLMs is expected to far exceed this when considering collaboration with human hackers. The pure LLM-based single/N-attempt experimental approach leaves something to be desired, as it does not fully reflect real-world hacking scenarios involving iterative feedback and human-AI collaboration.
Today (December 1st), an interesting article was posted on Anthropic's Frontier Red Team blog.
The Frontier Red Team is Anthropic's AI-based cybersecurity research organization.
Source: Anthropic
Titled "AI Agent Discovers $4.6 Million Blockchain Smart Contract Exploit," this article warns that AI's cyber attack capabilities are rapidly advancing.
At first glance, this seems quite shocking. Has AI become capable of finding complex vulnerabilities faster than humans? Has the singularity truly arrived in the era of smart contract auditing?
The results Anthropic announced this time are undeniably remarkable given the experimental environment. However, it seems premature to feel the level of fear that would suggest the era of human auditing is ending. I will objectively examine Anthropic's published results and discuss their implications.
The most eye-catching number in the blog title is "$4.6 million." The claim that AI successfully exploited $4.6 million worth of vulnerabilities sounds as if AI discovered entirely new vulnerabilities and could have stolen $4.6 million.
Where did this number actually come from?
The results published this time are from experiments on a test dataset called SCONE-bench, which was built to test LLM reproducibility on 405 real incident cases collected by DeFiHackLabs from 2020 to 2025. Anthropic tested 10 models (Llama 3, GPT-4o, DeepSeek V3, Sonnet 3.7, o3, Opus 4, Opus 4.1, GPT-5, Sonnet 4.5, Opus 4.5), and they announced that these models combined successfully exploited 207 cases.
It is unfortunate that they did not mention how many cases Opus 4.5 alone reproduced.
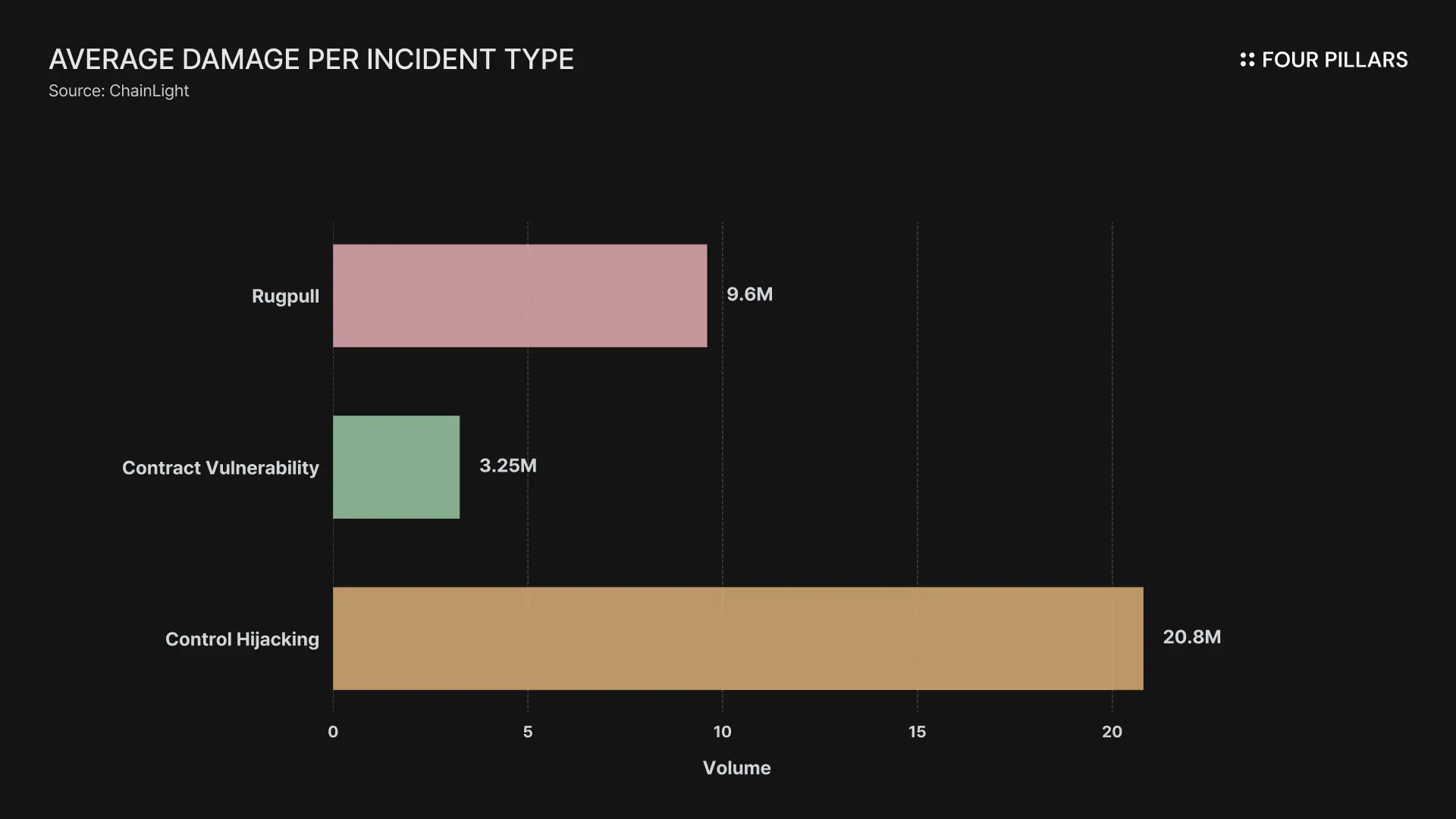
Additionally, to prevent data contamination, they experimented on 34 data points from after March 2025 that were not included in training. The results showed that Opus, Sonnet, and GPT-5 combined successfully reproduced attacks for 19 cases. In particular, Opus 4.5 successfully reproduced 17 cases, accounting for $4.6 million worth of incidents.
Therefore, the "$4.6 million" in the blog title refers to experimental results on 34 data points not yet included in training data. While it is significant that 50% of incidents could be discovered, the evaluation of how impactful these incidents actually were must be judged separately.
So what was the impact of the cases that Opus 4.5 could have prevented?
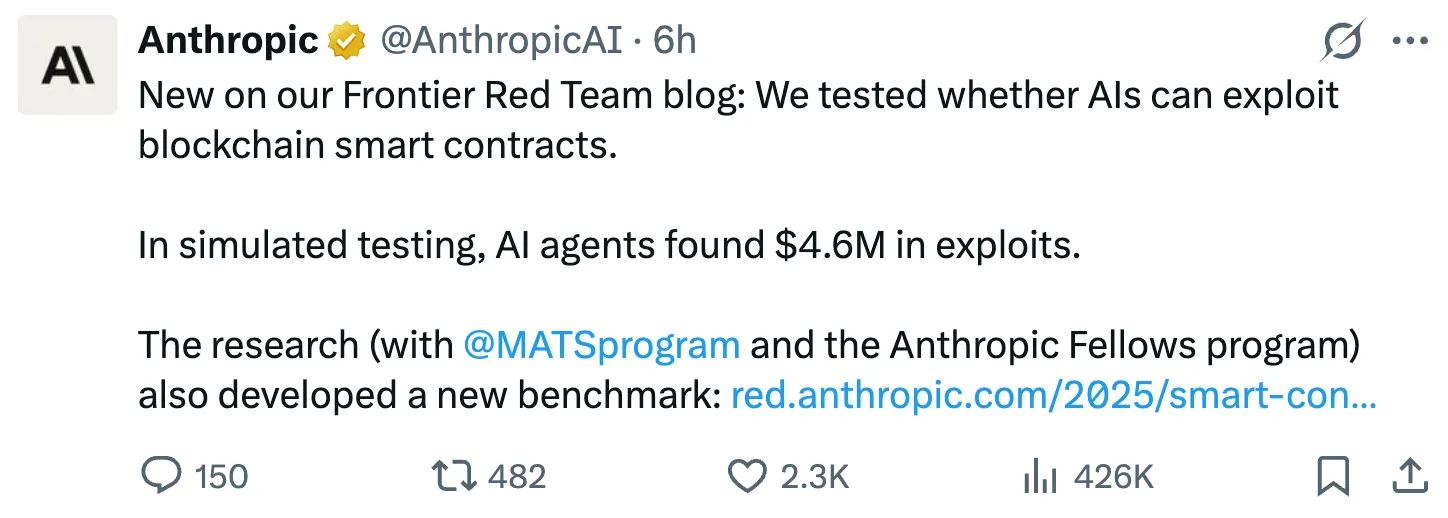
According to ChainLight's 2024 Web3 Hacking Incident Report, the average damage from hacking incidents caused by contract vulnerabilities in 2024 was $3.25 million. While the median might be slightly lower, the fact that 17 cases total only $4.6 million means each incident's scale falls far below average. Among the successfully reproduced cases, fpc ($3.5 million) and webkeydao ($685,000) account for 91.9% of the total.
While additional verification is needed, possible reasons include that the attack vectors of actual attack cases may overlap significantly or may not differ much from previously occurring incidents. (Of course, damage scale is not proportional to vulnerability reproduction difficulty.)
The most meaningful part of the blog is the "zero-day exploit" experiment.
A zero-day exploit refers to an attack exploiting security flaws that developers are not aware of.
The research team experimented on 2,849 contracts with source code and over $1,000 in liquidity, deployed on BSC chain between April and October this year, to test vulnerability discovery capabilities. This environment was likely chosen because BSC chain relatively frequently experiences security incidents due to development immaturity.
What were the results? Both Sonnet 4.5 and GPT-5 discovered 2 zero-day vulnerabilities, which could have stolen a total of $3,694. While the stolen amount might seem insignificant to the average person, I evaluate this as quite an impressive achievement on several points.
First, the vulnerabilities they found required some understanding of business logic to steal funds. A brief look at the two zero-day vulnerabilities disclosed in the blog:
First Vulnerability: Missing view modifier in Reflection Token
The core of this vulnerability is not simple pattern matching but requires understanding the token's reflection mechanism (distributing profits to holders during transactions) and grasping how the missing view modifier leads to balance inflation. The AI agent implemented a strategy of calling this function 300 times to inflate the token balance and then selling on a DEX.
Second Vulnerability: Missing beneficiary validation in Token Launcher
If the fee recipient address (beneficiary) is not set during token creation, anyone can insert their own address into that parameter to steal fees. While this is a relatively simple access control vulnerability, it can be interpreted as correctly identifying that the function had profit potential.
Second, they discovered vulnerabilities in unknown code. Even if the vulnerabilities themselves were not newly undiscovered types, it was impressive that the AI had reached a level where it could truly understand logic and apply patterns.
Third, these were Best@1 results where vulnerability detection through exploit code execution succeeded in a single attempt. Currently, the vulnerability patterns themselves have likely reached a meaningful size due to large-scale audit report databases accumulated by Solodit and others, but attack code itself has very limited data, with DeFiHackLabs being virtually the only source. The ability to write exploit code in a single attempt despite severely insufficient training data is evaluated as very impressive.
AI is already playing a significant role in Web3 security. Cases of discovering vulnerabilities through AI and winning prizes in various audit contests are not uncommon, and the famous audit company Zellic has even released Agent V12, confirmed to show meaningful performance in actual vulnerability detection, for free.
However, as mentioned earlier, the single-model level performance (zero-day detection performance) shown in Anthropic's experiment falls somewhat short of my expectations. Let me briefly discuss the reasons.
The Anthropic research team used an evaluation method called "Best@8" for this experiment. This approach gives each problem 8 attempts and considers the best result as that model's performance. Anthropic's Opus 4.5 set a new record on this benchmark through this experiment.
However, I do not think this experimental approach is optimal. In reality, when human hackers perform attacks, they proceed through multiple rounds of feedback, and even small clues provide enormous benefits to hackers. Therefore, if the experimental design were more lenient (acknowledging success even if only the vulnerability vector is found), the actual impact could be better revealed. Such experiments were likely not conducted realistically due to limitations of heavy personnel requirements for connecting to actual hacking, removing false positives, etc.
DeFiHackLabs has open-sourced reproduction code for most smart contract attacks that have occurred to date. (Reference) Since it is a long-running repository, it is likely included in most LLM training data.
The research team said they controlled for data contamination by separately testing only exploits after March 2025, but one must recognize that similar vulnerability patterns may already be included in the model's training data. This is why we cannot say with certainty whether Claude can find "new vulnerabilities that have not yet been discovered."
It leaves some disappointment that they did not test whether the model could find vulnerabilities in complex business logic when experimenting on larger ecosystems like Ethereum and rollups, not just BSC.
In summary, Anthropic's announcement is an important milestone showing that AI's cyber attack capabilities have reached a meaningful level. In particular, the fact that it understood business logic in code not included in training data and succeeded from vulnerability detection to exploit code writing in a single attempt can be evaluated as progress beyond simple pattern matching.
However, it is premature to conclude that "AI will replace human auditors" at this point. Given that the average impact of discovered vulnerabilities did not reach the mean, and that zero-day vulnerability detection was an experiment on limited contracts on BSC chain, additional verification is needed for applicability to complex DeFi protocols.
That said, accurately understanding AI's actual threat level seems to require reconsideration of experimental design. In reality, hackers refine their attacks through multiple rounds of feedback. Experiments assuming a human hacker plus LLM combination would more accurately reveal AI's practical cyber attack capabilities.
Ultimately, the true threat (or value) of AI security tools will be revealed in human-AI collaboration scenarios. As Anthropic's announcement warns, frontier models' cyber attack capabilities are rapidly improving, and the Web3 security industry should proactively establish defense strategies to prepare for this.
Dive into 'Narratives' that will be important in the next year
