*Optimism Governance commissioned this report to provide an overview of current cross-chain interoperability solutions, their relevance to the Optimism Superchain, and recommendations for future development. This is an edited version of the full "Cross-Chain Interoperability Report." Read the full report here.
Objective and Scope of this report is to examine cross-chain interoperability solutions for the Optimism Superchain, focusing on cross-rollup possibilities and using EVM chains as a reference.
Bridge Taxonomy section classifies bridges into seven types, including embedded, light client, and validator bridges. Each type offers distinct advantages and challenges regarding safety, liveness, latency, incentives, costs, and complexity.
Based on the Key Bridge Properties, each bridges are evaluated based on safety, liveness, latency, and implementation complexity. These factors determine the bridge's ability to prevent message loss, operate continuously, deliver messages quickly, and manage design intricacy.
This report also analyzes finality in blockchain systems for secure cross-chain messaging. It also explores mechanisms to mitigate finality risks and examines atomicity models to ensure complete execution of cross-chain operations.
In Future Recommendations section, we emphasize the importance of developing robust cross-chain interoperability solutions for the Optimism Superchain, highlighting the need for continued exploration and refinement of bridge models and mechanisms to ensure secure, efficient, and scalable cross-rollup communication.
When we talk about cross-chain interoperability, we are talking about the ability to transmit information between blockchains, and therefore also let actions in one blockchain trigger actions on another blockchain. We will often use the term "message" to refer to a generic piece of information.
For the most part, cross-chain interoperability is concerned with bridging messages and assets. We depart from some connotations of "bridging" by not confining ourselves to the app layer, as we also consider chain-level architecture possibilities — for instance, rollup sequencing.
While we talk about "cross-chain interoperability", the real goal of this report is to uncover possibilities for cross-rollup interoperability. In the process, we will however say a good deal that applies to any kind of chain. Similarly, we will use the classical architecture of EVM chains as a basis for conversation and nomenclature, though a lot of the discussion generalizes.
We note that this report is not meant to be a comparison of existing solutions, though some are mentionned. Instead, we try to abstract away from specific implementations and focus on the general solutions and their properties.
In considering the interoperability of two rollup systems, it is important to consider their relationship. For instance, is the interoperability possible permissionlessly, or does it require collaboration (or even software changes) from one or both sides?
The Optimism Superchain is "A horizontally scalable network of chains that share security, a communication layer, and an open source development stack." OP Labs has unveiled some of its plans for cross-rollup interoperability, but many avenues remain open in the future.
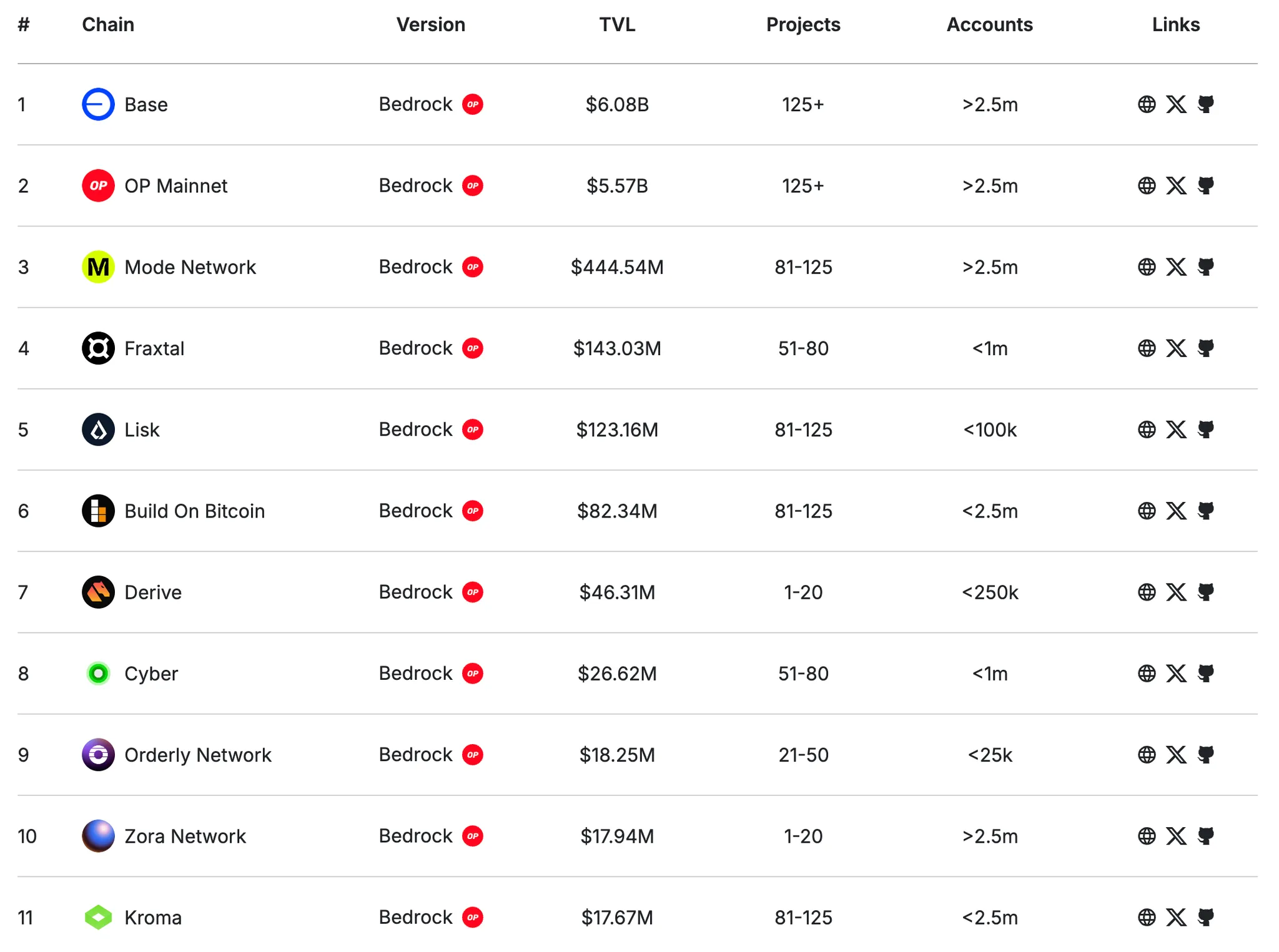
Source: Superchain Ecosystem | Chains
In our report, we will consider three models:
The small model, where the inclusion of a chain in the Superchain is a permissioned process, that requires a number of guarantees from the candidate chain. This seems to be the current "social" model, embodied by The Law of Chains.
The large model, where any chain can join the Superchain, with minimal oversight and overhead.
The graph model, where each chain independently decides which chain it can accept messages from. For a new chain, accepting messages from other chains is permissionless, while in the other direction the other chains need to opt into accepting messages from the new chain. This is the current "technical" model, reflected in the Optimism interop specifications.
It is important to note that no model is superior, they simply have different trade-offs. The small model can enable solutions where some components of the system like sequencers are more "trusted" because there are decentralization or financial guarantees in place. The large model has the advantage of allowing anyone to run their rollup however they want, but it excludes solution where the misbehaviour of a rollup would negatively impact other rollups in the Superchain. The graph model is a hybrid that lets every chain defines its own trust set.
These solutions are also not exclusive. In fact, in the context of the Superchain, the graph model can be seen as unifying the small and large models: a core set of chains would be fully interoperable (trust each other) while a broader set of sattelite chains would trust other core or satellite chains, but not be trusted by the core set. It's also possible that new techniques will make the large model more practical.
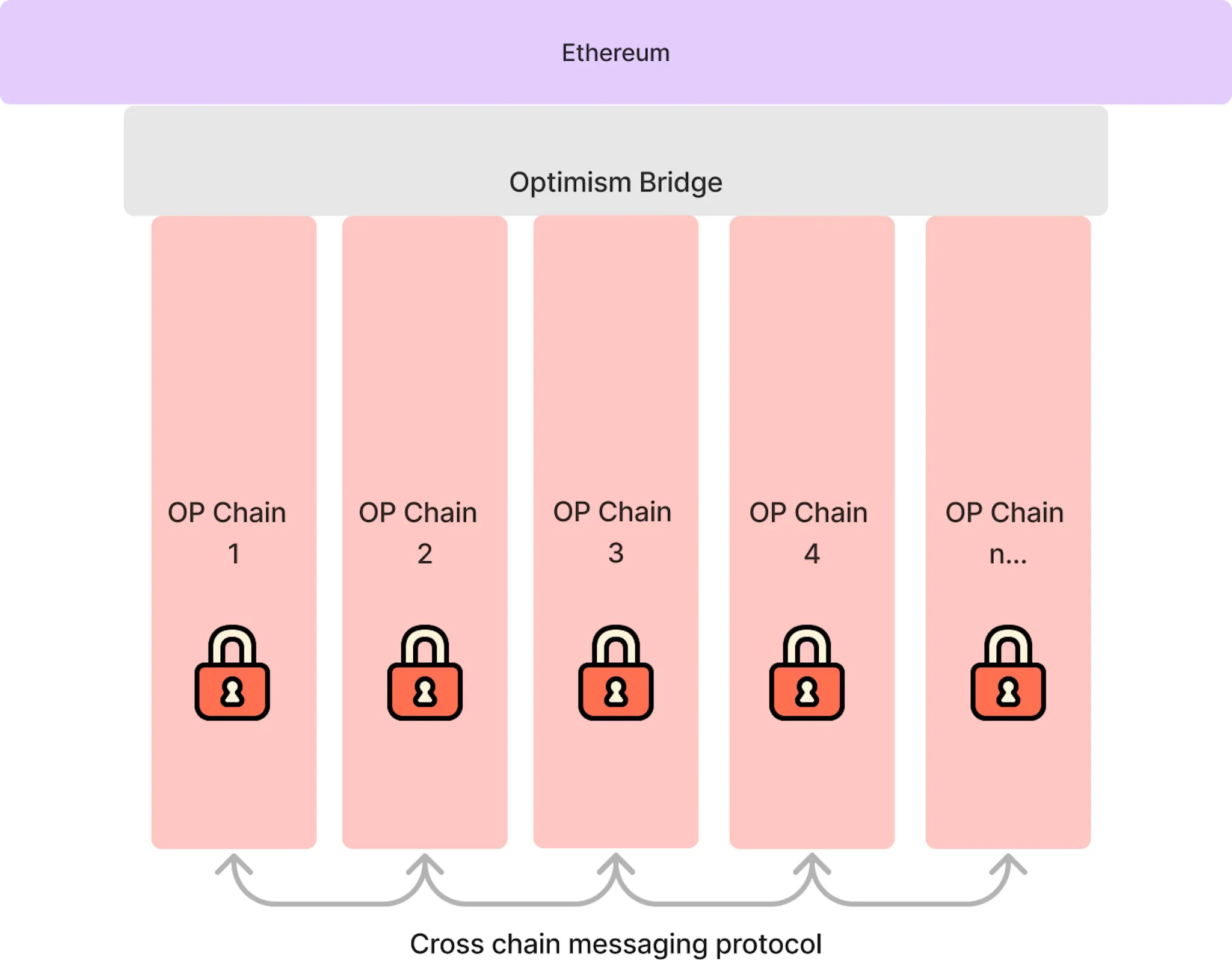
Source: Superchain Explainer | Optimism Docs
To enable bridging arbitrary messages from a source to a destination chain, the only real hard requirement of consequence is a mechanism to authenticate the messages sent from the source chain on the destination chain. This problem generalizes to the problem of authenticating blockhashes or state roots from the source chain.
We discuss these mechanisms in the Bridge Taxonomy section, where we classify bridges into 7 types - including embedded bridges, light client bridges, validator bridges, etc.
In the Bridge Properties section, we will then define a few key properties of bridges (safety, liveness, latency, incentive & costs, and implementation complexity), and assess all bridges in the taxonomy in the light of these properties.
Additionally, two important things can be added to the authentication mechanism.
First, a mechanism to remove finality risk from the bridge. Bridging cannot be safe as long as the source chain did not finalize. The current minimum time to finality for a rollup using Ethereum as the data availability (DA) layer is 15 minutes: 14 minutes for Ethereum to finalize in the best case, and a 1-minute average time for the rollup to post transactions to Ethereum. This issue can be tackled by making sure that if a source chain block sending a message rolls back, then the destination chain block receiving the message must also roll back. We discuss this at length in the Finality section.
Second, a mechanism to ensure atomic inclusion of transactions across chains, or atomic execution of a transaction and the messages it sends. Atomic inclusion can easily be achieved with shared sequencing, but offer few hard guarantees of interest (it is very interesting for MEV extraction, however). Atomic execution is a much more powerful property, but also much harder to achieve in practice. This is the topic of the Atomicity & Synchronicity section.
The Messaging Formats & Interfaces section will discuss how cross-chain transactions are represented on the source and destination chain, and highlight a few design trade-offs for these interfaces.
Finally, the Conclusions & Recommendations section will summarize the findings of the report and givew some opinions and recommendations for the future.
This taxonomy comprehensively covers all existing and proposed bridge designs. While variations exist, they rarely alter the fundamental properties of the bridges.
Hybrid bridges are possible, such as adding slashing to other bridge types or incorporating a validator set into a zero-knowledge bridge to protect against proving system exploits. However, these additions usually don't significantly change the bridge's core characteristics.
We categorize bridges into seven types:
Embedded bridges
Light client bridges
Validator bridges
Slashing bridges
Optimistic bridges
Reverse bridges
Rollup bridges: Proof-of-execution bridges and Fault proofs bridges
We'll briefly define each type here and explore their properties in detail later.
Embedded bridges are systems where the destination chain embeds a full node of the source chain — all validators are thus expected to also follow and validate the source chain (or trust someone else to do so). This is the model used by the rollup bridges in the L1 to L2 direction.
Light client bridges are systems where the destination chain runs or verifies a light client of the source chain. A light client verifies the consensus of the source chain but doesn't verify transaction execution (1). From one perspective (2), this is equally secure, as a chain's consensus typically has the authority to upgrade the chain, effectively "allowing" any execution outcome. This category also encompasses bridges using zero-knowledge proofs of consensus.
(1) Note that the Ethereum light client protocol (introduced in the Altair hard fork) doesn't fit this definition. It relies on an attestation committee with significantly weaker security assumptions than Ethereum consensus. Read here for more details.
(2) The key distinction between a light client and a full client is that a full client verifies execution. This enables it to participate in "social consensus" by choosing to follow the set of rules (the state transition function) it deems legitimate.
Validator bridges are systems where a set of validators are commissioned to validate the source chain, and must attest to the authenticity of the information (whether it is a state root, transactions, or anything else) being bridged, and the destination chains verifies these attestations. This is very similar to light client bridges — validator bridges verify the consensus of validators — with the difference that the validators do not need to participate in the actual consensus of the source chain, and their attestations do thus not carry the same guarantees.
Slashing bridges are systems where a permissioned set of relayers can relay messages from the source chain to the destination chain. If a relayer posts a message on the destination chain that did not originate from the source chain, anybody can post a copy of this (signed!) message to the source chain, causing the relayer to be slashed.
This system is only economically secure, and must be used in a way where the system can function with forged messages, as well as ensure that the loss incurred by a forged message is lower than the relayer's bond. In practice, this probably entails rate-limiting relayers in terms of economic value.
There is also a question of how to ensure relayers actually deliver messages. At a minimum, we could allow users to challenge relayers, forcing them to post a signed relaying message on the source chain, such that the user (or a benevolent third-party) is at least able to relay the message manually if needed.
We're not aware of any pure slashing bridge deployment, but it is a sound design within its constraints, and a slashing mechanism is often added to other types of bridges.
Optimistic bridges work like the slashing bridges, but additionally add a period during which messages can be challenged on the destination chain before they are considered valid. A set of permissioned actors (this could be the relayer set itself) are responsible for challenging, and challenges immediately invalidate the relayed message. Invalid challenges can themselves be challenged on the source chain, in the same manner as invalid messages. This system is secure as long as there is an honest actor that can challenge a forged message within the challenge period. Slashing of relayers and challengers is required to avoid griefing attacks.
Reverse bridges are bridges that rely on the existence of another bridge (which we'll call "forward bridge") in the reverse direction (destination to source). A user posts a message on the source chain, and a relayer relays it to the destination chain. Then, using the forward bridge, the relayer proves that he did relay the message and unlocks payment from the user.
Reverse bridges are different from the other bridges in that they make no claim about the authenticity of relayed messages. As such, these messages are limited to those that could have been sent regardless of their initiation from the source chain. These messages can contain end-user (EOA) signatures for validation, but there is no way to establish that a smart contract on the source chain emitted a message. Use cases include cross-chain asset transfers, triggering permissionless actions on another chain, and operating a smart wallet controlled by an EOA from another chain.
The reverse bridge inherits security assumptions from its forward bridge, though the risks for the user and the relayer are altered.
Rollup bridges are bridges that enable bridging in the L2 to L1 direction in rollup systems (in the L1 to L2 direction, rollups use embedded bridges), as well as between rollups that share the same architecture and bridging mechanism.
The specificity of rollups is that they do not reach consensus on the state of the blockchain via a majority vote of validators. Instead, they prove on the L1 chain that the state (represented by a state root) is valid, given a commitment to a state transition function and the included transactions. If the source of truth (i.e. the data availability layer) for the L2 chain transaction data is not the L1 chain, this additionally require bridging these commitments over, with the additional trust assumptions that this entails.
Once the validity of a L2 chain block's state root has been established, messages sent within that block can be relayed on the L1 chain (by proving the message against the state root). So the L2-to-L1 bridge comes almost for free with the state consensus mechanism.
Rollup bridges can also be used to bridge between rollups, the mechanism here being specific to the flavour of rollup bridge. Rollup bridges come in two flavours, specific to either validity/ZK rollups (proof-of-execution bridges) or optimistic rollups (fault proof bridges).
2.7.1 Proof-of-Execution Bridges
Proof-of-execution bridges are systems where the L1 chain verifies a zero-knowledge (ZK) proof of the correct execution of a transition on the L2 chain. This is also known as a validity proof, since the cryptographic proving mechanism is used predominantly for its succintness property (it's a lot cheaper to verify a proof than to execute the computation) than its privacy property.
Cross-rollup bridging using proof-of-execution is fairly straightfoward: the destination rollup chain can simply verify the validity proof. For this, it needs access to the L1 and possibly the DA blockhashes, which it is already tracking, being a rollup itself. These hashes commit to all the inputs (mostly transactions) that go into making a block, and are thus the only public inputs to the validity proof besides the proven source chain hash or state root. The inputs (transactions) themselves can be private inputs to the proof, which are proven by the proof against the public input hashes.
2.7.2 Fault proof bridges
Fault proof bridges are systems where the L1 chain waits for a challenge period before accepting a proposed L2 chain block's state root as valid. If a challenge is made, a challenge game takes place on the L1 chain to determine the challenge's validity.
Explaining challenge games is outside the scope of this document, but if interested, refer to this introductory thread and this video for the general idea, as well as this article and this video for the finer details.
Cross-rollup bridging using fault proof bridges requires sequencers to deliver messages from other rollups. A shared fault proof system ensures that blocks that deliver a message that wasn't sent on the source rollup is considered invalid.
We've identified 5 key bridge properties:
Safety defines the conditions under which a bridge might malfunction. This includes delivering non-existent messages or failing to deliver sent messages. It also encompasses potential economic losses resulting from bridge failures.
Liveness refers to the conditions that might cause a bridge to stop functioning. This could involve ceasing to accept new messages or temporarily halting message delivery.
Latency measures the time taken for a message to reach the destination chain after being included in a block on the source chain.
Incentives & costs examine the expenses and profits for various actors in the bridging system. This property explores how these financial factors influence behavior, particularly in relation to safety, liveness, and latency.
Implementation complexity assesses the intricacy of the bridge system's design. This includes factors such as codebase size, number of independent components and actors, use of advanced technologies (especially cryptography), and reliance on niche expertise. Notably, most bridge hacks stem from implementation issues rather than fundamental design flaws.
Let's explore how these properties manifest in various bridge types within our taxonomy.
We define bridge safety in terms of preventing two types of violations:
Lost messages: Messages sent on the source chain but never delivered to the destination chain.
Forged messages: Messages delivered on the destination chain that were never sent from the source chain.
Most bridges aim to prevent these violations, with the exception of slashing bridges, which allow but penalize forged messages. However, certain conditions can make these safety violations possible in any bridge system.
Bridge safety exists on a spectrum and depends on additional assumptions beyond the correct execution of the source and destination chains. Different types of bridges have varying levels of safety and trust requirements:
Trust-Minimized Bridges: These bridges, including embedded bridges, proof-of-execution bridges, and light client bridges, add no security assumptions beyond the correctness of their implementation.
Fault Proof Bridges: Used in optimistic rollups, these bridges assume the existence of at least one honest challenger to dispute incorrect state roots within a challenge window (typically 7 days).
Embedded Bridges: While the safest, these bridges are least scalable as they require one blockchain to embed another. They are primarily suitable for rollups.
Rollup and Light Client Bridges: These bridges require update mechanisms, introducing trust assumptions in the update process. Update delays can mitigate risks but may slow responses to vulnerabilities.
Slashing Bridges: These bridges allow forged messages but aim to make the financial penalty for forging greater than any potential gains. They require careful calibration of slashing amounts and consideration of source chain liveness.
Optimistic Bridges: These rely on honest challengers within a shorter challenge period (e.g., 30 minutes), making them more vulnerable to attacks on the destination chain's liveness or censorship resistance.
Validator Bridges: Their safety depends on the decentralization of the validator set, similar to blockchain decentralization analysis.
Reverse bridges, which rely on underlying forward bridges, present unique safety considerations, particularly in asset transfers and potential relayer losses due to price exposure.
Some bridges may prioritize faster message delivery over the source chain's finality period, introducing additional risks discussed in the Latency section.
For more comprehensive information on bridge safety, refer to the Crosschain Risk Framework for operational security insights and the L2Bridge Risk Framework for perspectives on liquidity networks.
Liveness is defined in terms of "liveness violations", which are situations during which either:
Delayed messages: Sent messages are not delivered for an extended period of time. This is a subjective appreciation, but we will generally consider this an especially undesirable issue when the delivery could be made (e.g. the destination chain is live and uncongested) but isn't.
Bridge down: New messages cannot be sent.
The liveness of a bridge may depend on the following factor:
liveness of the source and destination chain
censorship-resistance of the source and destination chain
built-in mechanism (e.g. an emergency pause function)
the existence, incentives and liveness of relayers
the liveness of validators (for validator bridges)
Liveness and censorship-resistance in blockchain bridges are closely related concepts. Liveness failures, which include censorship, can occur in either the source or destination chain, affecting the bridge's functionality. These failures can lead to delayed messages or even a complete bridge shutdown, regardless of the bridge's design.
Optimistic bridges face a unique challenge where extended source chain liveness failures could allow malicious relayers to challenge messages without consequences. To mitigate this, implementing a sufficiently long relayer bond withdrawal delay is crucial. Additionally, while pause mechanisms in bridges can help combat hacks, they should be designed to avoid potential abuse and allow users to cancel pending messages.
Relayers play a vital role in bridge liveness. Bridges can be categorized as permissionless (where users can become relayers), permissioned (with a set group of relayers), or a hybrid requiring a bond from relayers. Embedded bridges are unique as they don't require separate relayers. Permissionless relayers can be implemented in various bridge types, including light client, reverse, validator, and some rollup bridges.
To enhance bridge liveness, it's essential to decentralize relayer and validator sets through geographical and jurisdictional diversity, elimination of shared controls, and client diversity. Allowing users to cancel message requests can also improve certain bridge designs. Lastly, proper incentives are crucial to ensure relayers actively participate in message relay, a topic further explored in the Incentives & Costs section.
Latency in blockchain communication refers to the time it takes for a message to reach its destination chain after being included in a source chain block. While theoretically, latency could be zero in cases of atomic composability or when a single entity controls both chains, this is not common in practice.
Typically, the minimum latency equals the destination chain's block time, as relayers need to observe the source chain block and initiate a transaction on the destination chain. However, factors like network congestion and technical issues can increase this time unpredictably. Certain bridge types, such as optimistic and fault-proof bridges, have built-in latency due to their challenge periods.
Proof-of-execution bridges face unique latency challenges due to the time required for proving. Current technology allows for proving an Ethereum block in tens of minutes, with faster times possible using prover-friendly hash functions. Both zkEVMs and general zkVMs have seen rapid improvements in proving speed and cost efficiency, with further advancements expected in the near future.
An important consideration for bridge latency is the possibility of chain reorganizations (re-orgs). To maintain safety, bridges must wait for finality on the source chain before delivering messages, as premature delivery could lead to safety violations if the originating transaction is re-orged away. One solution is to ensure the destination chain rolls back if the source chain does, preventing the delivery of non-existent messages.
This issue is particularly significant for rollups, which can have finality times of up to 15 minutes. For instance, Optimism typically takes about a minute to post blocks to Ethereum, but this can extend to half an hour in some cases. The interplay between latency and finality presents one of the major challenges in cross-chain interoperability, especially for rollup-based systems.
The various types of bridges have different types of actors that may need to be present for the bridge to work, and thus be incentivized to do so. These are relayers, validators, challengers, and provers.
We will first tackle relayers, as they are the most common actor, and some of the discussion will generalize to other actors. We then tackle the issue of dynamic destination chain gas fees, which can cause the user to specify a fee that would not cover the relayer's costs. We then discuss the remaining actors.
2.4.1 Relayers
Relayers are crucial actors in most bridge types, except embedded bridges. Some designs allow users to relay their own messages, particularly in bridges that enable permissionless relaying, such as validator, light client, and rollup bridges.
In validator bridges, relaying requires obtaining a validator signature. Alternatively, validators may only relay state roots, requiring relayed messages to include a proof-of-inclusion against the state root. This principle extends to rollup bridges, where someone must relay the chain's state root. While this process is permissionless for some rollups (like OP-stack-based), others require a sequencer. After state root validation—either by submitting a zk proof or waiting for the challenge window—anyone can relay a message by proving it against the state root.
For proof-of-execution bridges, a prover must post a state root proof. This can be permissionless, though users aren't expected to shoulder this responsibility. Light client bridges require relaying of consensus-relevant information (usually an aggregated signature) to the destination chain. This can also be permissionless but typically isn't.
Despite the possibility of user relaying, it's often preferable to have dedicated relayers to ease the user burden. For slashing and optimistic bridges, relayers must be bonded, precluding permissionless user participation.
In permissioned relaying systems, measures should ensure timely message delivery to prevent safety violations. This might involve a challenge system where senders can request relayers to post signed messages on the source chain for manual relay, with penalties for non-compliance.
Reverse bridges present a unique case. While users could theoretically relay their own messages, these bridges often guarantee automatic relaying or involve relayers performing costly actions (e.g., token transfers on the destination chain in exchange for source chain tokens).
Relayers require compensation for their costs, primarily transaction fees on the destination chain, plus a profit margin. The following section will address issues arising from destination chain fee variability.
2.4.2 Handling Variable Destination Chain Fees
Relayers must be paid a fee. Due to changing transaction fees on destination chains, it's vital to set fees high enough to cover costs and motivate relayers. While collecting fees on the source chain seems easier, paying on the destination chain is more practical, as it allows payment to be unlocked upon message delivery. The bridge must maintain sufficient liquidity on the destination chain for relayer payments.
When fees are collected on the source chain but paid on the destination chain, off-chain fee estimation is necessary. If relayer payments are too low due to increased destination chain fees, there should be a way to increase fees on the source chain while preventing replay attacks.In practice, bridge operators may use several fee strategies:
Charging flat fees known to be profitable
Operating without explicit payments if destination chain fees are consistently low
Incentivizing relayers with protocol tokens
Using third-party relaying services (e.g., Chainlink, Gelato, Keep3r)
For permissionless relayer sets, centralized relayers or third-party services are generally safe. However, permissioned relayers should avoid depending on centralized entities to ensure continued operation and prevent safety issues.
Embedded bridges (L1-to-L2 rollup bridges) handle fees differently:
Optimism burns L1 gas and implements a separate fee market for L1-to-L2 messages
Arbitrum uses a "retryable ticket" system where users pay fees on L1 and can retry failed transactions
These approaches vary in fee collection, contract function compatibility, and transaction replay capabilities.
2.4.3 Validators, Provers and Challengers
Validators in validator bridges incur costs by running blockchain nodes to verify the source chain's state. They can be incentivized similarly to relayers, but with more stable costs since they don't face variable transaction fees. Provers in proof-of-execution bridges generate expensive proofs, which can be 10,000 times more costly than the original computation.
Due to this high cost, it's beneficial to have a selection method for provers, such as an on-chain round-robin among "preferred" provers. This approach doesn't exclude permissionless proving if preferred provers fail to deliver. Optimistic, slashing, and proof-of-execution bridges require challengers—watchdogs who contest incorrect messages, state roots, or other challenges. In slashing and fault proof bridges, challenging is permissionless as it doesn't affect system performance.
While challenge incentivization in rollups isn't widely discussed, it's anticipated that existing node operators like exchanges, RPC providers, and block explorers could fulfill this role. As mentioned before, we're not aware of any pure slashing bridge deployments.
In optimistic bridges, challengers prevent forged messages on the destination chain. This role must be permissioned, allowing challengers to be bonded on the source chain and penalized for invalid challenges. Valid challenges result in relayer penalties, from which challengers can be compensated.
Since relayer cheating is unlikely, challengers might never profit. A clever solution is to make relayers and challengers the same group, allowing them to verify each other's behavior at minimal extra cost. This approach aligns with relayers' interests, as the bridge's safety ensures their continued income.
We will say little about implementation complexity, because it is pretty subjective.
Let's reiterate some key areas to watch for when looking at implementation complexity:
size and quality of the codebase
number of independent software components and actors
use of advanced technology and algorithms (in particular cryptography)
maturity of the tech stack (e.g. compilers, libraries, etc.)
In general though, simplicity is key. Simpler systems are easier to reason about, and admit less tricky corner cases.
A related factor to pay attention to is the presence of quality documentation and specification for the system. It's generally not a good sign when those are not publicly available.
This section concisely outlines the characteristics of various bridge types. For a more comprehensive understanding, please refer to the previous questions.
Regarding latency, our analysis assumes that no party is willing to accept the finality (reorganization) risk. However, if a party is prepared to take this risk, the latency could be reduced based on their risk tolerance and the current fee structure.
We've omitted a summary of the incentives discussion because it's not a primary factor in bridge design, is difficult to summarize effectively, and overlaps with the liveness and safety sections, which already identify the actors requiring incentivization.
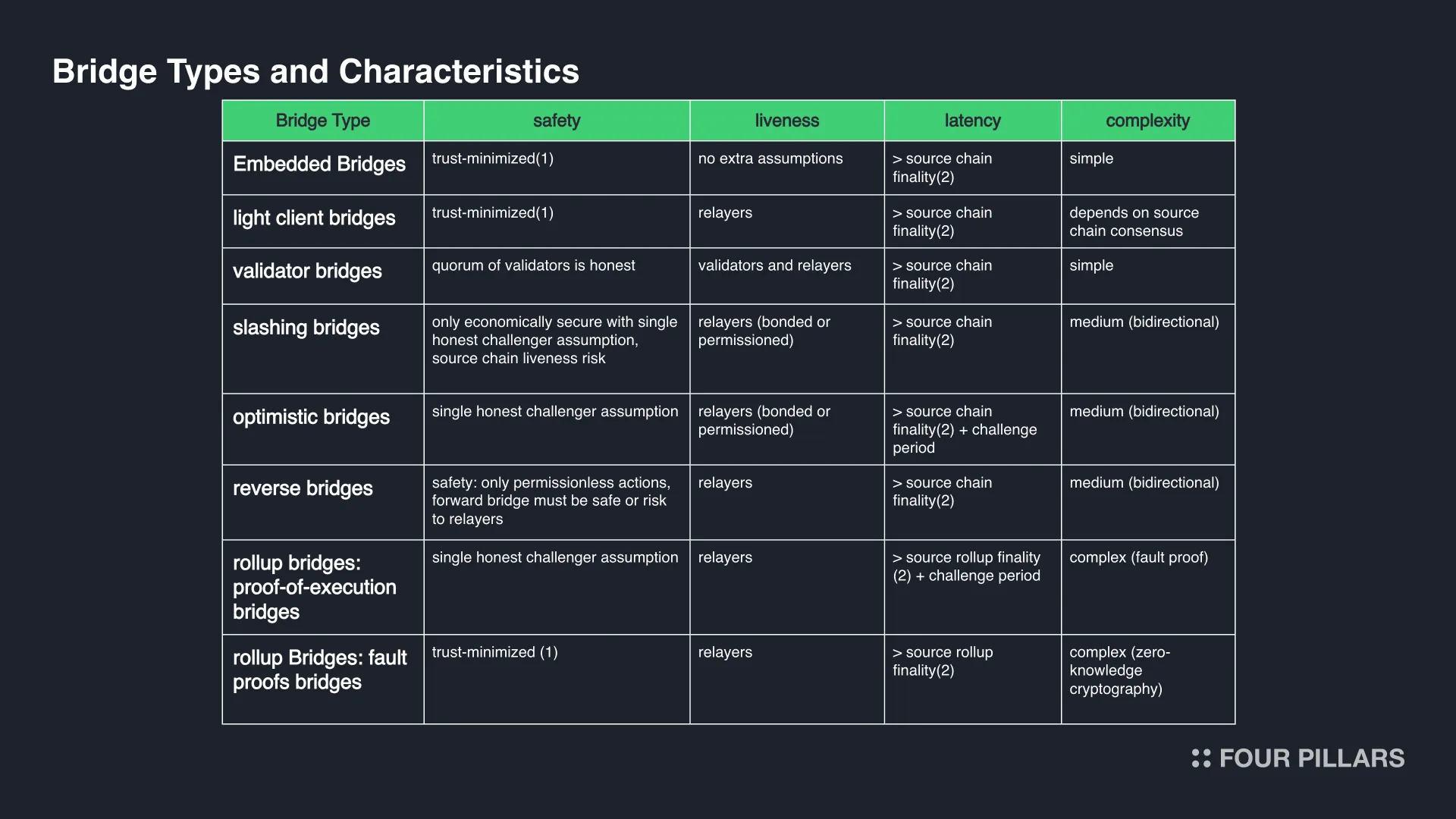
(1) Trust-minimized means there is no additional safety assumption than those of the source and destination chain, and implementation correctness.
(2) The rollup finality time is: DA submission delay + DA finality + DA bridge finality when DA != L1.
*This section has been condensed. For a more detailed analysis, view the full report.
Finality in blockchain systems refers to the point at which a block is irreversibly part of the chain. For cross-chain bridges, this concept is crucial as it affects the safety and speed of message delivery. Bridges must balance the risk of re-organizations (re-orgs) on the source chain against the desire for quick message delivery. Waiting for finality ensures safety but can introduce significant delays, especially for chains with longer finalization times like Ethereum (approximately 15 minutes).
Different blockchain systems handle finality in various ways. Some, like Cosmos chains using the Tendermint consensus, have instant finality. Others, such as proof-of-work chains, have probabilistic finality where the likelihood of a re-org decreases as more blocks are added. For rollups, the time to finality includes both the time to post blocks to the data availability (DA) layer and the DA layer's own finalization time. This can vary significantly between different rollup implementations and DA solutions.
To address the finality challenge, two main approaches have emerged:
The first is cross-chain contingent blocks, where the destination chain includes a reference to the source chain's block and rolls back if that block is re-orged. An extension of this idea for rollups sharing a DA layer allows for more generalized and efficient cross-chain communication by commiting to DA blocks instead of source chain blocks.
The second approach, shared validity sequencing, proposes carrying only a Merkle root of sent messages between chains, enabling bidirectional bridging at the same block height when combined with shared sequencing.
While these solutions offer improvements, they are not without limitations and potential attack vectors. They require the destination chain to be aware of the source chain, limiting their scope. Additionally, they don't guarantee the validity of source chain blocks, only ensuring that the destination chain rolls back if a message wasn't actually sent. Sophisticated attacks exploiting these mechanisms are possible, though unlikely. Users should be aware that any rollback can be disruptive, potentially conflicting with expectations of transaction finality.
In cross-chain communication, two primary approaches exist. Message-passing involves a transaction on the source chain initiating a message to be sent to the destination chain. This method is straightforward but can be limited in its atomicity guarantees. On the other hand, bundling creates an atomic package containing transactions for multiple chains. This approach offers stronger atomicity but requires more complex coordination mechanisms. Each method has its own set of trade-offs in terms of simplicity, security, and cross-chain interaction capabilities.
Atomicity in cross-chain messaging refers to the all-or-nothing principle of operations. It can be applied to either transaction inclusion or execution across multiple chains. Atomic transaction inclusion ensures that transactions are included in their respective chains simultaneously, while atomic transaction execution guarantees that transactions are successfully executed across different chains.
Synchronicity, borrowed from programming concepts, distinguishes between asynchronous operations (where results are not immediately available) and synchronous operations (where we wait for results). Based on these concepts, we can identify five atomicity models in cross-chain messaging:
Non-atomic (asynchronous) execution
Atomic inclusion
Non-atomic instant asynchronous execution
Atomic asynchronous execution
Atomic synchronous execution
Each model has its unique characteristics and trade-offs. For instance, atomic inclusion guarantees transaction inclusion but not execution success, while atomic execution ensures that if an action fails on one chain, it won't be executed on the source chain either. The choice of model depends on the specific requirements of the cross-chain application. Let’s look into the specific of some of the approaches.
5.2.1 Atomic Inclusion
Atomic inclusion refers to the process of including transactions "at the same time" across multiple chains. While this doesn't guarantee successful execution or eliminate finality risks, it provides significant benefits. It enables faster bridging between chains, reducing the time required for cross-chain operations. Additionally, it allows for more efficient cross-chain MEV extraction, potentially leading to better economic outcomes for validators and users alike. However, implementing atomic inclusion requires careful design to ensure synchronization across different blockchain networks with varying block times and consensus mechanisms.
5.2.2 Atomic Inclusion and Implementation Methods
Two primary methods for implementing atomic inclusion are Shared Sequencing and Builder-Proposer Separation (PBS). Shared Sequencing utilizes a common sequencer to order transactions for multiple chains. This approach scales well due to its lower resource requirements, as it centralizes the sequencing process. However, it may introduce some level of centralization risk. PBS, on the other hand, separates the roles of block proposers and block builders. Proposers delegate the task of building blocks to specialized builders, allowing for more efficient block construction. Atomic inclusion becomes possible when a proposer builds for multiple chains simultaneously. This method can potentially improve block efficiency and MEV extraction while maintaining a degree of decentralization.
5.2.3 Atomic Execution - Challenges and Potential Solutions
Achieving atomic execution across multiple chains poses a complex challenge with several proposed solutions. Running multiple nodes allows for customization but limits scalability due to increased resource requirements. State locking ensures consistency by temporarily locking relevant state across chains, but it requires multiple network roundtrips and can create bottlenecks for frequently accessed ("hot") state. Chimera Chains offer a pragmatic approach by partitioning state into base and chimera partitions, though this solution is limited to specific use cases.
The Crossbar System co-locates the execution of atomic bundles, requiring a bridging mechanism for state roots—an approach that works particularly well with rollups and force inclusion mechanisms, offering a balance between atomicity and scalability. Each method presents unique trade-offs in performance, security, and complexity. The choice ultimately depends on the specific requirements of the cross-chain system being developed.
5.2.4 Atomic Execution - Domain Specific Solutions for Cross-Chain Transactions
While general solutions for atomic cross-chain transactions have trade-offs, domain-specific approaches can achieve atomicity more efficiently. A promising use case is token bridging and swapping, which can be implemented using synchronous state locking on the destination chain only.
This approach uses escrow contracts on the source chain and allows "solvers" (liquidity providers) to fulfill orders. The one-sided locking reduces contention issues, and atomicity protects solvers from double-filling orders.
While this solution still faces challenges like potential griefing attacks, it offers a practical framework for atomic cross-chain token operations. Projects like OneBalance are exploring similar concepts, though with different security assumptions.
Our discussion so far has mostly stayed high-level, but let's now dive into the nitty-gritty of message passing between chains.
By necessity, arbitrary message passing requires smart contracts on both the source and destination chain, sometimes designated as respectively an "outbox" and "inbox". A few standard have been proposed for this purpose, listed here in chronological order:
Besides proposed standard, most bridges, rollups, and other interoperability projects have their own messaging interface. There are too many to list but let's mention a few that have the vocation to be pluralistic (i.e. not tied to any specific provider). This list is not intended to be exhaustive.
Let's also mention Optimism's bridging spec and interop spec as examples of messaging standards between L1 and L2, and accross L2 (respectively)
Finally, some standard or proposed solutions focus specifically on bridging tokens, for instance:
Despite the proliferation of standards and solutions, none has come close to becoming a de facto standard nor even gain significant traction, with perhaps the exception of xERC20 (though its success is still moderate). We will speak more about it later.
Message passing interfaces typically employ an outbox on the source chain and an inbox on the destination chain. Messages in the outbox require three key components: a sender (automatically filled), a destination address, and data ("calldata"). The storage of this data can vary, from direct posting in the outbox to storing only a hash, with the actual data emitted in an event, stored in source chain calldata, or communicated off-chain. Each method has its trade-offs, balancing storage efficiency with data accessibility and coordination requirements.
In addition to these components, messages must specify the destination chain, either explicitly or through separate outboxes for each destination. A nonce is often included to prevent replay attacks, though this protection can be implemented at a higher level, as demonstrated by the Optimism bridge's two-layer interface approach. Some systems even allow for broadcast messages by omitting the destination chain at the lower level, with a standardized secondary layer for specifying destinations.
Once a message is in the outbox, it must be relayed to the destination chain's inbox. While many standards dictate how messages should be relayed and authenticated, some, like EIP-5164, EIP-6170, Hyperlane, and xERC20, leave these aspects to the implementation or external contracts. This approach, while less standardized, offers greater flexibility and has proven beneficial for adoption, particularly in scenarios involving multiple chains or changing bridge providers.
Among standards that address message verification, there's a distinction between those proving messages against a state root (or a specific "message root") from the source chain and those expecting direct message relay. Some systems, like EIP-7533, allow for batch delivery of messages, even from multiple source chains. This diversity in approaches reflects the complex balance between standardization, flexibility, and security in cross-chain communication designs.
Let's talk a bit more about the specificities to token bridging. Beyond everything we've talked about so far, tokens face an additional challenge in the form of "path-dependency": whenever a token is bridged from a source to a destination chain, the token is typically locked or burned on the source chain and unlocked or minted on the destination chain, in what is typically called a "wrapper token" contract.
This works well when the source chain happens to be the chain where the canonical token representation lives. However, trying to bridge between two other chains causes can lead to the proliferation of mutually non-fungible token wrappers, some of which are "wrappers of wrappers".
This can be fixed by adopting a single token contract on every chain, burning the token on the source chain and minting on the destination, however this approach (which isn't supported by most bridge providers) is not without tradeoffs: the token contract on every chain is now susceptible to the security risks of all the bridges that are allowed to mint into it.
xERC20 tackles this risk by enabling token governance to set rate limits on the token flow from any given bridge. Of course, the classical solution to the "wrapper of wrapper" problem is to route every token through its canonical chain, though the UX of this "solution" is pretty horrendous. Another non-solution is introducing liquidity pools between all the wrappers. This can be made to sort-of work in the presence of liquidity providers that take upon themselves the task of rebalancing token liquidity accross chains.
The mint-and-burn into a single contract approach also doesn't support permissionless bridge deployment. This is almost a fundamental trade-off, but it can be alleviated in a very homegeneous chain and bridging environment like our small Superchain model: if it is known that all chains have similar execution environment and that the bridges between any of these chains have guaranteed identical security properties, it could be allowed to permissionlessly or automatically deploy mirror token contracts on all of these chains. Note that this is not generally possible in the graph Superchain model.
This report has covered a lot of ground: we have established a bridge taxonomy focused on message authentication mechanisms, and have analyzed their properties (safety, liveness, latency, incentives & costs, and implementation complexity).
We have discussed how chain finality is the main obstacle to a bridging experience that is both fast and safe, and highlighted one key property: to bridge faster than chain finality, a destination chain must re-org whenever a source chain re-orgs. We have then discussed mechanisms to make this happen (shared validty sequencing, cross-chain contingent blocks).
We have looked at how to tightly couple execution on the source and destination chains, with the main prize being atomic synchronous execution (aka universal synchronous composability). We reviewed the state-of-the-art solutions to the problem (state locking, crossbar system, SVS + PBS) and explored the possibility of less general domain-specific solutions (like atomic token swaps).
Finally, we discussed the various messaging formats and their trade-offs. Now, we offer some opinions, recommendations and wishes for the future.
There is no question that for cross-rollup bridging, proof-of-execution bridging (aka ZK bridging or validity bridging) is the safest solution — it is the only trustless solution that works for rollups, and has better latency characteristics than other near-trustless solution like fault proof bridging.
However, their adoption has so far been hampered by the fact that generating proofs was still relatively costly and slow compared to less secure bridges.
As we discussed in the Latency section (with a breakdown of proving times and costs), the technology has been improving rapidly, and it is not unreasonable to expect it to match the speed of DA layers within the next few years.
As proving time comes down to seconds instead of minutes, we can expect zero-knowledge bridges to start blooming. At this point, focusing on other mechanisms feels like a mistake for ambitious interop projects. Much to our chagrin, our bridge taxonomy is fated to become a historical chronicle.
That being said, zero-knowledge proofs don't solve everything in interoperability.
Chains using the Poseidon hash for Merkleization already have proving times lower than most rollups' finality times. However, bridging faster than the source chain's finality remains unsafe. While waiting for Ethereum to achieve single-slot finality—which could take years—an alternative is to create a network of rollups that reorganize together.
Two approaches to this are Cross-Chain Contingent Blocks (CCCB) and Shared Validity Sequencing (SVS). These are similar, with CCCB committing to state roots and SVS working on message roots. The Optimism interop protocol takes this further, requiring only the inclusion of transactions themselves.
All these solutions are viable, though CCCB lacks atomicity. Optimism's solution, currently being implemented, stands out for its thoughtful design. It introduces a graph model of cross-chain dependencies and a mechanism for shared reorganizations via a shared fault proof. The next step is extending this mechanism to support zk/validity proofs.
Another option is adopting fast-finality DA layers like Celestia, which eliminate reorganizations. However, this isn't a cure-all: while DA layers don't add safety risks to chains using them, they paradoxically introduce risks when a chain receives messages from another chain using a different DA layer. If the source chain's DA layer is compromised without a shared reorganization mechanism, the destination chain risks a bridge safety violation.
Fast proofs of execution can help here too. If proof generation time matches DA block time, fast trustless bridging becomes feasible. Proof-of-execution, however, presents the highest implementation complexity. While some argue that fault proofs are equally complex, the specialized knowledge required to audit a zero-knowledge protocol poses a particularly challenging barrier.
Given these challenges, combining a zero-knowledge bridge with a validator bridge is advisable. This approach requires both a valid proof and a quorum of signatures. Both bridge types are fast, and the validator bridge ensures that a safety violation would require compromising most validators and exploiting a fault proof bug—an unlikely scenario.
The necessity of atomicity is debatable. Most use cases are financial, involving complex transactions without risking capital (like our swap-bridge-buy-NFT example). While "liquidity fragmentation" is often cited as a reason for atomicity, fast non-atomic message passing could potentially solve this issue, albeit less elegantly. When capital can move safely between chains at block production speed, atomicity becomes a nice-to-have feature.
That said, atomicity is intriguing. It fulfills one of Ethereum's original promises: creating a world computer with a uniform computing layer. It's a goal worth pursuing. But how?
We've examined three solutions—state locking, crossbar system, and SVS + PBS—each with its own trade-offs.
State locking faces lock contention issues: multiple chains accessing the same state require extensive synchronous network communication, increasing latency. Longer lock leases reduce liveness for state-manipulating operations. This approach is also vulnerable to griefing attacks, where malicious actors request locks for failing transactions.
The crossbar system aids scaling by not requiring every node to run on each actor. However, it reduces overall rollup throughput as all must wait for the crossbar rollup to complete its work.
SVS + PBS (Shared Validity Sequencing + Proposer Builder Separation) (1) depends on economically-motivated block builders for atomic execution. While potentially effective, this approach turns block builders into powerful interoperability gatekeepers and may introduce centralization risks, affecting censorship resistance.
Currently, there's no perfect solution for general atomic execution. Domain-specific solutions are more likely to be adopted soon, potentially addressing issues in general architectures. For instance, some form of state locking could work well for cross-chain token swaps.
If I had to recommend a fully general atomic execution approach, I'd suggest:
The crossbar system for small Superchain models, avoiding centralized actors at the cost of slightly reduced throughput compared to SVS + PBS.
SVS + PBS for graph or large Superchain models, noting that block builders become gatekeepers to chain participation. The crossbar system doesn't support these models.
(State locking appears fundamentally flawed as a general approach due to lock contention and griefing vulnerabilities, unless proven otherwise.)
(1) Optimism's interop protocol can be substituted for SVS here, as it enables shared re-orgs and allows concurrent cross-chain transaction execution at the same height/time.
Despite the extensive discussion on this topic, the conclusion of this report is straightforward:
Zero-knowledge proofs enable trustless bridging and are set to become the preferred bridging method in the medium term as proving time and costs decrease.
Time-to-finality remains a challenge for fast bridging. Adopting a common data availability (DA) layer with quick finality addresses this issue. As Ethereum serves as the de facto DA for most rollups, achieving single-slot finality should be prioritized. In the absence of a fast-finality DA layer, a shared re-org mechanism is necessary. Both shared validity sequencing and the Optimism interop protocol offer effective solutions to this problem.
While all known solutions for atomic transaction execution involve significant trade-offs, domain-specific solutions—particularly for token swaps—appear feasible with minimal drawbacks. We've demonstrated that this could be implemented on top of a general state locking mechanism, and domain-specific architectures may also be viable.
If you keen to read comparisons of bridging providers in particular, here are a few articles and reports that have taken this approach:
Dive into 'Narratives' that will be important in the next year