
"Parallel Execution" has been one of the key buzzwords in the blockchain industry over the past year. However, for parallel execution to be properly implemented, innovations in various fields are required, with the most critical being the improvement of blockchain databases.
One of the pioneers of EVM parallel processing, Sei, has been aware of this necessity and has been continuously considering database optimization since last year. The result of these efforts is the Sei DB.
Sei DB transforms the traditional single database structure into a modular structure divided into two layers. It eliminates unnecessary metadata and optimizes state access, thereby removing inefficiencies at the database level and enhancing the overall performance of the blockchain. Sei's approach serves as an excellent example not only for blockchains pursuing transaction parallelism but also for builders aiming to improve overall blockchain efficiency.
There were quite a few keywords that heated up the blockchain market cycles in 2023 and 2024. Meme coins, Farcaster, and restaking were among them. However, the keyword that I found the most technically intriguing was "Transaction Parallel Execution." While the market is familiar with EVM parallel processing, I believe that fundamentally improving blockchain performance by parallelizing transactions is more crucial than the EVM itself.
When it comes to "Transaction Parallel Execution," you might think of various chains, but the first one that comes to my mind is the Sei Blockchain. They weren’t the first to introduce the concept of transaction parallel processing, but they played a significant role in popularizing this keyword in the market. As of the time of writing, Sei Network has become the first Layer 1 blockchain capable of EVM parallel processing. This is because they have already passed a governance proposal to support EVM parallel processing.
The passage of the governance proposal for Sei V2 is significant because it shows that transaction parallel processing, previously deemed difficult to implement, has reached a practical stage. Why was transaction parallel processing so challenging to apply? My investigation revealed several reasons. Firstly, there’s a high potential for conflicts between transactions that affect the same state (such as transactions that alter the same account balance). The complexity also increases when determining the order of transactions. Most importantly, even if transactions are parallelized at the execution layer, without optimization at the database level, it’s hard to achieve dramatic scalability improvements. These issues have made the implementation of transaction parallel processing particularly difficult.
Sei’s co-founder and CTO, Jayendra, has consistently pointed out this issue (database-level optimization) through various media channels. If EVM parallel processing, or transaction parallel processing in general, is considered merely an optimization at the blockchain's "execution" level, significant scalability improvements cannot be realized. Therefore, to discuss performance improvements through parallel processing, it is essential to address how database-level optimization is being achieved.
Today, I’d like to talk about how the Sei Blockchain is optimizing its database. Note that database optimization is not just an issue for blockchains that support parallel processing; it’s a challenge faced by all high-performance blockchains that need to handle numerous transactions. Through this article, I hope readers will gain a deeper understanding of Sei V2 and that those designing high-performance blockchains will acquire valuable insights for designing databases in high-performance blockchains.
Before discussing the issue of storage, we need to define what state means. What is state in the context of blockchain? State refers to the information about all accounts within the blockchain, including details about the accounts themselves, their balances, and contract codes. Thus, when a transaction occurs on the blockchain, it inevitably affects a particular state. For example, if person A transfers Sei tokens to person B, the balances of both A and B need to be updated. This is what it means for the state to change. When the state changes, what is the impact? Usually, we don't think that the state increases in size just by changing, but even transactions that merely alter the state leave a transaction record in the blockchain's history (this type of data is called historical state). Therefore, it can be said that even state-changing transactions slightly increase the state size. In other words, all on-chain transactions contribute to the growth of the state.
As I explained earlier, on-chain transactions contribute to state growth. In the case of a fast blockchain like Sei, which processes more transactions within a given time, the state will grow much more rapidly compared to other blockchains. If we further add support for transaction parallel execution, the state will grow even faster, leading to several issues:
Increased node operation costs: Full nodes must store the entire blockchain state, increasing storage costs and making it difficult to operate nodes on that blockchain. This could lead to centralization because the entry barrier for running full nodes becomes higher.
Decreased blockchain performance: A larger state means it takes more time for nodes to process and verify transactions. Whenever transactions that change the blockchain state occur, nodes need to read and update the relevant state values. As the state grows, there is more data to access and more state values to change. This ultimately results in slower blockchain performance.
Node synchronization issues: Blockchain fundamentally involves multiple nodes sharing a ledger and continually synchronizing valid ledgers with each other. If the state becomes too large, it becomes very challenging for new nodes to join. New nodes must download the entire ledger of the chain to participate in the mainnet. Chains take "snapshots" of the entire record at specific points, which new nodes use to synchronize. However, if the chain is too large, taking a snapshot takes a long time, and during that time, the blockchain continues to add new transactions and data. This discrepancy can make synchronization for new nodes difficult. Nodes that fall behind in synchronization will also face significant time and cost to catch up, leading to performance issues and making it harder for new nodes to join, thus potentially causing centralization problems.
The problem of the state becoming too large in a blockchain is called State Bloat. If transaction parallel execution is achieved without database improvements, the state will bloat further, causing the various problems mentioned above. These issues ultimately prevent the benefits sought from transaction parallel execution from being realized. Sei recognized this issue from the beginning, and the result of that awareness is the Sei DB. So, what did Sei DB focus on in its design, and how much has it improved the database?

Sei V1 employed a vanilla database structure based on the Immutable Adelson-Velsky and Landis (IAVL) tree data structure, which is used by the Cosmos SDK for storing state. In Ethereum, a similar concept is the Merkle Patricia Trie (MPT). However, this structure proved inefficient in several ways: 1) It requires storing a significant amount of metadata on each node, 2) Maintaining balance within the tree necessitates multiple disk accesses, slowing down memory access, and 3) It often results in storing more data than intended. To address these inefficiencies, Sei introduced Sei DB, a modular database architecture that divides storage into two layers.
Why divide the database into two layers? Because the state itself is categorized into historical state and active state. To better understand Sei DB, it's essential to define these two types of state:
Historical State
Historical state refers to all states recorded before the most recent block height of the blockchain. In other words, it encompasses all past records of the blockchain, excluding the currently processed block. For example, all past balance records of users fall under the historical state.
Active State
Active state pertains to the information related to the most recent block height. Simply put, it includes the most current information recorded on the blockchain, such as the current balances of users.
Even from these definitions, it’s clear that historical state and active state contain distinctly different information, with historical state being much heavier than active state. Sei aims to optimize the database by handling these two types of state differently.
Sei DB is divided into 1) the State Commitment Layer (SC Layer) and 2) the State Storage Layer (SS Layer). Let’s examine the roles of these layers and how they interact.
The State Commitment Layer manages the active state of the Sei blockchain. The most critical component of the SC Layer is the Memory-Mapped IAVL Tree (MemIAVL), which is a modified version of the IAVL tree used in the Cosmos SDK. This modification, prompted by the inefficiencies mentioned earlier, optimizes state access. But why is MemIAVL so efficient for state access? To understand this, we need to delve into the concept of memory mapping used by Sei.
Typically, when processing files, file descriptors or file structure pointers are used to access them, which necessitates going through a buffer for input and output operations. Memory mapping (mmap()) addresses this by mapping a file into the process’s virtual address space, allowing data to be read or written without using read or write functions.
According to Sei, MemIAVL enables state access in hundreds of nanoseconds, which is 10~287 times faster for writes and 10 times faster for reads compared to traditional tree structures.
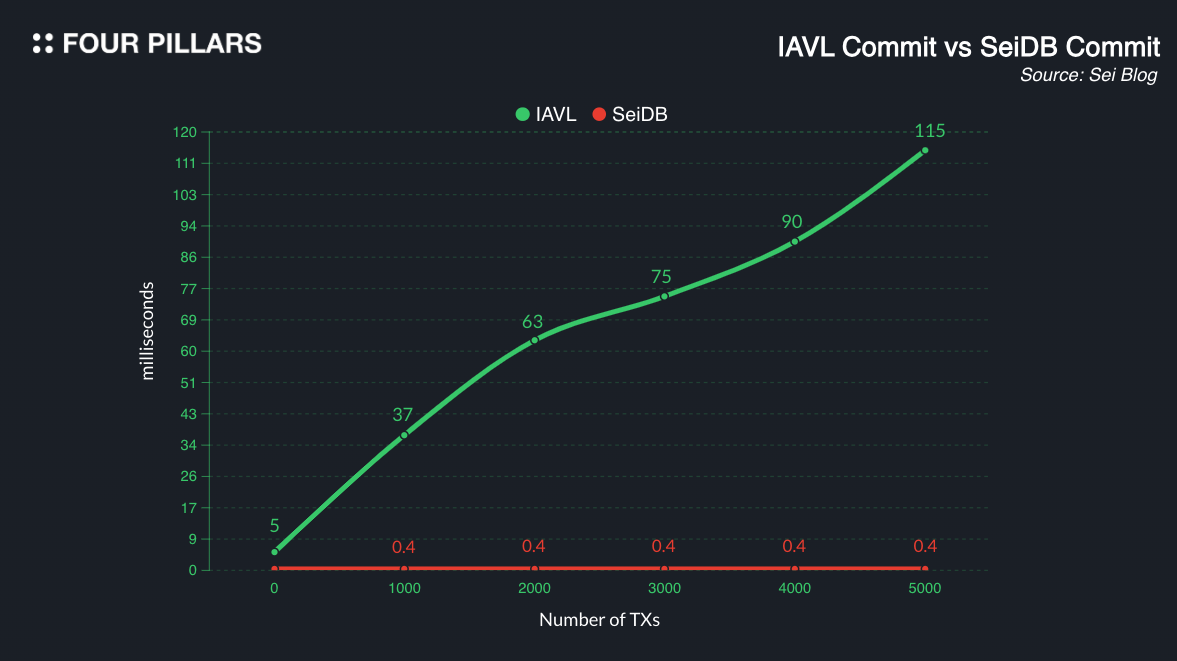
(The graph above focuses on state writes (commits) rather than state reads. This result, demonstrating a significant performance improvement, is achieved through the combination of SeiDB and asynchronous commit.)
To facilitate easier understanding, let's outline the entire lifecycle of a transaction being recorded on the blockchain using the MemIAVL implementation:
Transaction occurs, reading state from MemIAVL, transaction executions will then result in state changes (they are also known as changesets)
Changesets are applied to MemIAVL tree first, which then new root hash can be recalculated.
The newly calculated state root value is included in the block header, marking the transaction as successfully recorded on the blockchain.
In a different goroutine, those changesets will be persisted into a WAL file asynchronously, which can be used for recovery(If a node needs to be restored, the most recent snapshot, along with the information stored in the WAL, can be used for recovery.).
These changes fundamentally reduce CPU and memory usage, enabling Sei to build an exceptionally fast blockchain without the need for high hardware specifications.
While the State Commit Layer manages the most critical active state, the State Storage Layer handles all the records prior to the active state, also known as the historical state. Sei V2's State Storage Layer consists of three key components, which we will examine in detail:
2.2.1 Raw Key-Value Storage
Anyone familiar with blockchain will have encountered the concept of key-value pairs. This data storage structure uses a key as a unique identifier and a value as the associated data. For example, in the context of a blockchain, an account balance or the state of a contract is represented by a key, while the corresponding data (such as the amount of tokens in an account) is the value.
While key-value storage structures are common in other blockchains and databases, Sei optimizes this by minimizing metadata storage, thereby reducing the amount of stored data. Additionally, since the key is directly mapped to the value without needing additional abstraction layers, data access is faster, which enhances the overall efficiency of the blockchain.
2.2.2 Flexible DB Backend
The efficiency of a database structure is as crucial as its support for various storage backends. Requiring node operators to use a single storage backend can be limiting, as it prevents them from optimizing the backend to meet their specific needs. Sei V2 supports PebbleDB, RocksDB, and SQLite, allowing nodes to choose the database that best suits their requirements. The table below compares the characteristics of these three databases:
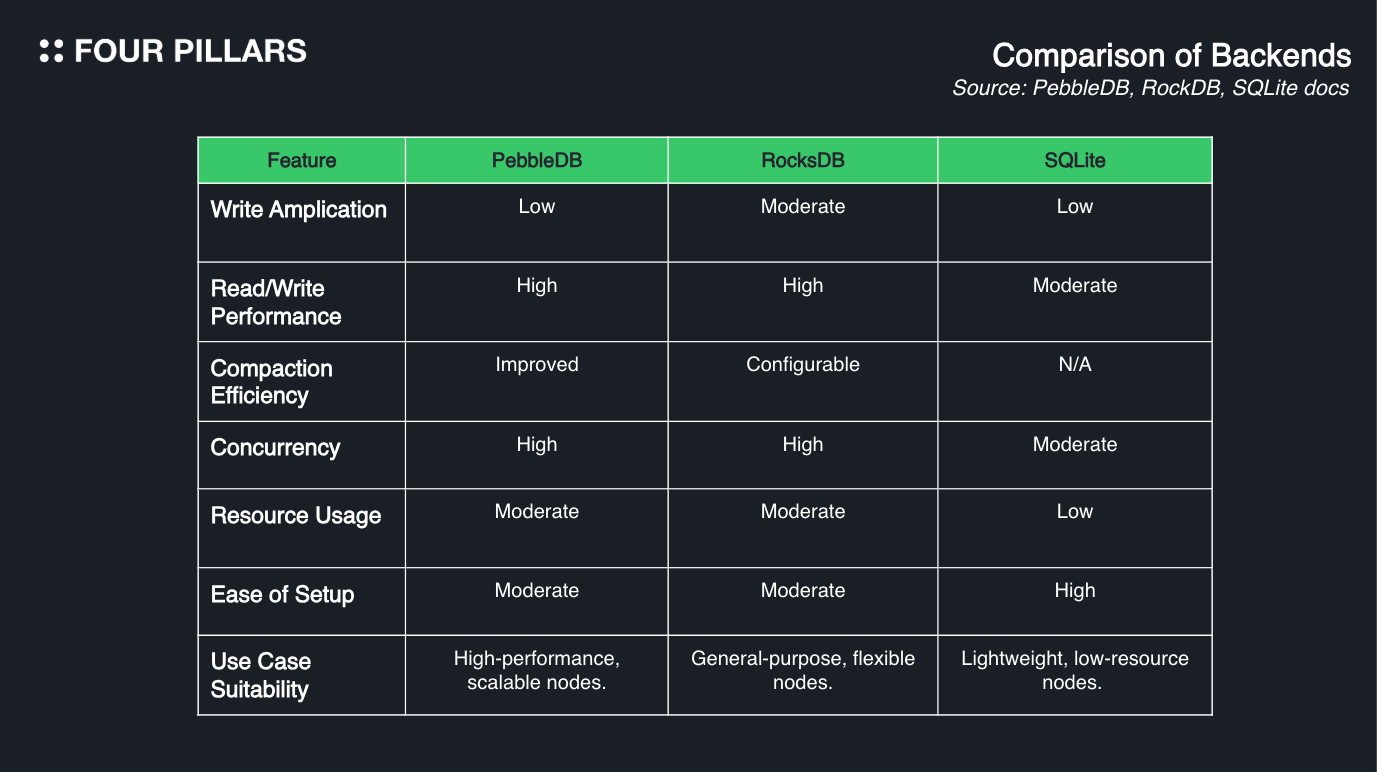
The characteristics of the databases supported by Sei V2 align with Sei's focus on performance. Each of these databases is optimized to handle large-scale data efficiently while minimizing write amplification (i.e., reducing the frequency of data writes to disk).
According to Sei, PebbleDB demonstrated the best performance among the supported databases. However, it's important to note that each of these databases has its own set of advantages and disadvantages. For a detailed comparison of their pros and cons, refer to the comparison chart provided by the Sei team.
2.2.3 Asynchronous Pruning
The final component to discuss is Asynchronous Pruning. Pruning, in the context of blockchain, refers to the process of removing unnecessary or outdated data from the blockchain. Traditionally, pruning operations can negatively impact network performance. However, Sei performs pruning operations asynchronously, meaning these tasks are executed in the background without affecting the primary blockchain operations. This approach allows Sei to optimize historical state data and reduce storage requirements for nodes without compromising the performance of the blockchain.
In summary, Sei V2's innovative approach to database management, including raw key-value storage, flexible database backend support, and asynchronous pruning, ensures efficient handling of both active and historical state data, thereby enhancing the overall performance and scalability of the blockchain.
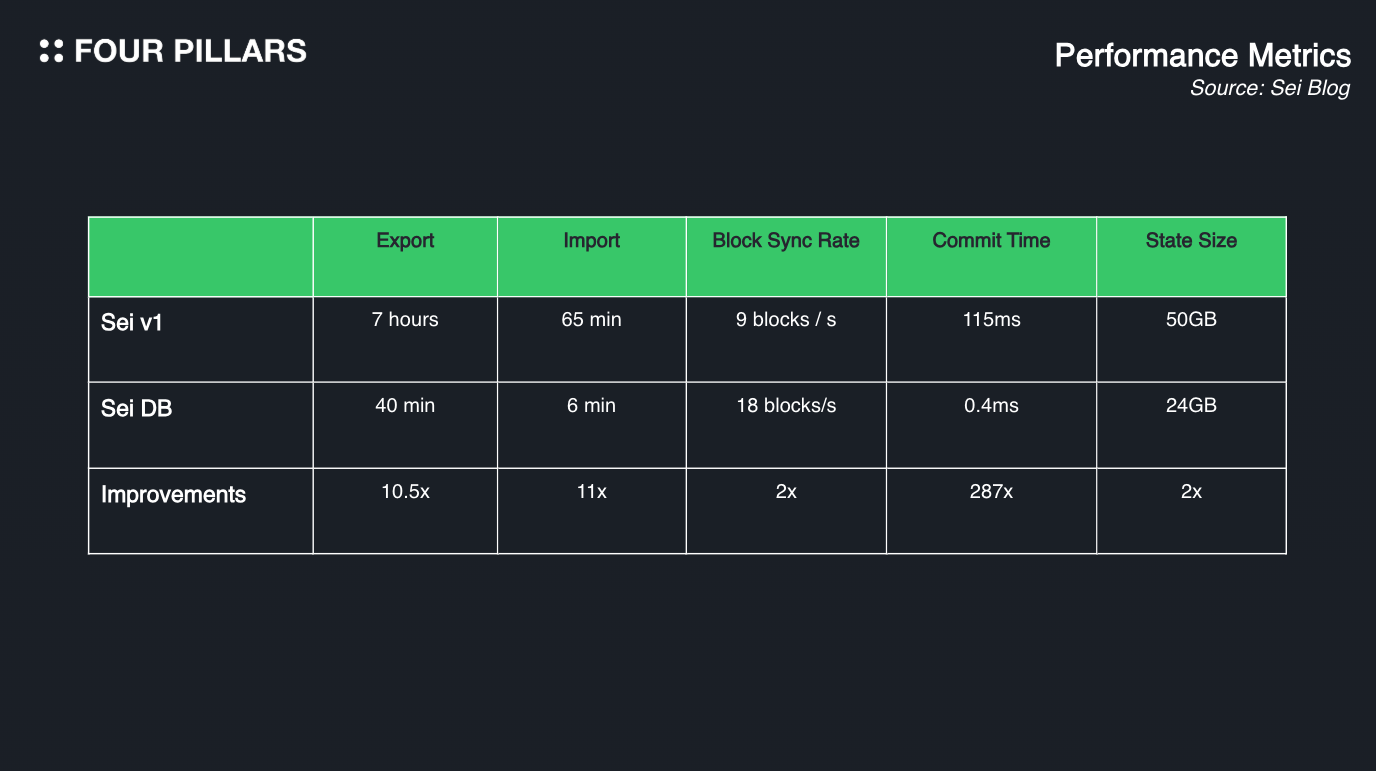
We have now explored the two layers of SeiDB (the state commit layer and the state storage layer) and examined the roles and features of each. Through this explanation, we understand that SeiDB theoretically enhances the performance of the Sei blockchain and optimizes it through database improvements. However, the most crucial aspect is the actual results. When the Sei team implemented SeiDB in a testnet environment, they obtained the following data:
Active State Size Reduction
The size of the active state stored in memory was measured, showing a 60% reduction in active state size.
Historical Data Growth Rate Reduction
The rate of increase in historical state size was assessed, and it was found to be over 90% slower compared to the previous database.
State Sync Time Reduction
The time taken for nodes to synchronize states was measured, revealing an approximately 1,200% improvement in speed.
Block Sync Time Reduction
The time required to synchronize blocks from the snapshot point to the latest block height was measured, showing a 2x increase in speed compared to the previous database.
Block Commit Time Reduction
The time taken to commit blocks to the blockchain was measured, demonstrating a 287x improvement in speed compared to the previous database.
TPS (Transactions Per Second)
The time required to process transactions was measured, showing more than a 2x increase in speed compared to the previous database.
Based on these indicators, it is anticipated that Sei v2, with the implementation of SeiDB, will exhibit dramatic performance improvements. Although overshadowed by the major narrative of EVM compatibility, the long-term significant improvement for Sei may well lie in the changes occurring at the database level.
The era of Sei v2 has arrived. In a market where narratives are crucial, mentioning Sei v2 typically brings to mind "EVM parallel processing." However, a closer examination of the changes brought by the v2 upgrade reveals a technology-intensive transformation that goes far beyond just EVM support and parallel processing improvements. While the performance indicators I mentioned earlier were merely test results prior to the v2 mainnet launch, the real-world impact remains to be seen. Nevertheless, these efforts deserve continuous attention because the practical performance of Sei v2 could inspire other Layer 1 blockchains to benchmark and enhance their own databases, thereby contributing significantly to the broader goal of "blockchain performance improvement."
From the outset, Sei has consistently pursued the singular goal of being a "fast blockchain," conducting extensive research to achieve this aim. As a researcher, I commend their relentless dedication to implementing a fast blockchain. Furthermore, I hope their research will continue to evolve, leading to even better database innovations, possibly emerging from the Sei team itself. Such efforts collectively will enable us to build superior blockchains, ultimately making blockchain technology more accessible to a wider audience.
Thanks to Kate for designing the graphics for this article.
Dive into 'Narratives' that will be important in the next year