The development of human civilization has been driven by informatic innovation, from the earliest days of human communication to the modern era of digital connectivity.
Especially, the development of data pipelines has had a profound impact across all industries in the past 20 years, as evidenced by the wide range of applications and intelligence that have been developed.
Therefore, even in the Web3 context, which is expected to deliver a variety of new values, the establishment of a data flow system can serve as a starting point to actually capture such opportunities.
The release of Bitcoin whitepaper in 2008 led to a rethinking of the concept of trust. Blockchain, which has since expanded its definition to include the idea of a trustless system, is rapidly developing as it assumes that different types of values such as individual sovereignty, financial democratization, and ownership can be applied to existing systems. Of course, it may take a lot of validation and discussion before blockchain can be used practically, as the features of blockchain may seem somewhat radical compared to those of various existing systems. However, if we are optimistic about these scenarios, constructing data pipelines and analyzing the valuable information contained in blockchain storage have the potential to be another significant tipping point in the development of the industry for we can then observe Web3 native business intelligence that has never existed before.
This article explores the potential of Web3 native data pipelines by projecting existing data pipelines commonly used in existing IT market into Web3 context. It discusses the benefits of such pipelines, the challenges that need to be solved to achieve these benefits, and the implications the pipelines can have for the industry.
“Language is one of the most important differences between man and the lower animals. It is not the mere power of articulation, but the power of connecting definite sounds with definite ideas, and of using these sounds as symbols for the communication of thought.” — Charles Darwin
Throughout history, major advancements in human civilization have been accompanied by innovations in information sharing. Our ancestors used language, both spoken and written, to communicate with each other and to pass on knowledge from generation to generation. This gave them a significant advantage over other species. The invention of writing, paper, and printing made it possible to share information more widely, which led to major advances in science, technology, and culture. The metal movable-type printing of the Gutenberg Bible in particular was a watershed moment, as it made it possible to mass-produce books and other printed materials. This had a profound impact on the Protestant Reformation, the Civil Revolutions, and the beginnings of scientific progress.
The rapid development of IT technology in the 2000s has made it possible to understand human behavior more deeply. This has led to a change in lifestyles, with most modern people making various decisions based on digital information. We call the modern society the “IT innovation era” because of this.
And, the AI technology is surprising the world again, only 20 years after the internet was fully commercialized. Many applications that can replace human labor are appearing, and many people are discussing about the civilization that AI will change. Some people are even in a state of denial, wondering how such a technology can come out so quickly that it can shake the foundation of our society. Although there is a “Moore’s Law” that the performance of semiconductors increases exponentially over time, the changes caused by the appearance of GPT are too sudden to face immediately.
However, it is interesting to see that the GPT model itself is actually not a very groundbreaking architecture. The AI industry, on the other hand, cites the following as the main success factors of GPT model: 1) Definition of business areas that can target a large customer base, and 2) Model tuning through data pipeline — from data sourcing to final results and feedback based on it to improve existing models. In short, those applications have been able to achieve innovation by refining the purpose of service provision and upgrading the process of data/information processing.
Most of the things we call innovation are actually based on the processing of accumulated data, rather than on chance or intuition. As the saying goes, "In a capitalist market, it is not the strong who survive, but the survivors who are strong." Today's businesses are crowded into a saturated market of infinite competition. As a result, businesses are collecting and analyzing all kinds of data in order to capture even the smallest niche.
We may be so caught up in the idea of "creative destruction" by Schumpeter that we value intuition over data-driven decision-making. However, even excellent intuition is ultimately the product of personal accumulated data and information. The digital world will penetrate our lives even deeper in the future, and more and more sensitive information will be shown in the form of digital data.
The Web3 market has attracted a lot of attention for its potential to give users control over their data. However, the blockchain scene, which is the underlying technology of Web3, is more focused on resolving the trilemma things at the moment. In order for new technologies to be persuasive in the real world, it is important to develop applications and intelligence that can be used in a variety of ways. We have already seen this happen with big data, as the methodologies for building big data processing and data pipelines have made a leap forward since around 2010. In the context of Web3, it is essential to make efforts to promote the development of the industry by building a data flow system so that data-based intelligence can be produced.
So, what opportunities can we capture from Web3 native data flow systems, and what challenges do we need to solve to capture those opportunities?

To summarize the value of configuring a Web3 native data flow in one sentence — It can be used to safely and effectively distribute reliable data to multiple entities, which can lead to the extraction of valuable insights.
Data Redundancy — On-chain data is less likely to be lost and is more resilient because protocol networks store data fragments across multiple nodes.
Data Security — On-chain data is tamper-resistant because it is verified and agreed upon by a network of decentralized nodes.
Data Sovereignty — Data sovereignty is the right of a user to own and control their own data. With on-chain data flow, users can see how their data is being used, and they can choose to share it only with those who have a legitimate need to access it.
Permissionlessness & Transparency — On-chain data is transparent and tamper-proof. This ensures that the data being processed is also reliable source of information.
Stable Operation — When the data pipeline is orchestrated by protocols in a distributed environment, the probability of each tier being exposed to downtime is significantly reduced because there is no single point of failure.
Trust is the fundamental basis for different entities to interact and make decisions with each other. Therefore, when reliable data can be safely distributed, it means that many interactions and decisions can be made through Web3 services where various entities participate. This can help to maximize social capital, and we can imagine a number of use cases as below.
2.2.1 Application for Service / Protocol
Automated Rule-Based Decision Making System — Protocols use key parameters to operate services. These parameters are periodically adjusted to stabilize the service status and provide the best experience to users. However, it is not easy for protocols to monitor the service status all the time and make dynamic changes to the parameters in a timely manner. This is where on-chain data pipelines come in. On-chain data pipelines can be used to analyze the service status in real time and suggest the optimal parameter set that matches the service requirements. (e.g., Applying an automated floating rate mechanism for lending protocols)
Credit Market — Traditionally, credit has been used in the financial market to measure an individual’s ability to pay. This has helped to improve market efficiency. However, the definition of credit in the Web3 market is still unclear. This is because data on individual is scarce, and there is no data governance across the industry. As a result, it is difficult to integrate and collect information. By building a process to collect and process fragmented on-chain data, credit market in the Web3 market can be newly defined. (e.g., MACRO (Multi-Asset Credit Risk Oracle) Score by Spectral)
Decentralized Social / NFT Expansion — The decentralized society prioritizes user control, privacy protection, censorship resistance, and community governance. This presents an alternative paradigm to the existing society. As a result, a pipeline can be built to control and update the various metadata used more smoothly and to facilitate migration between platforms.
Fraud Detection — Web3 services that use smart contracts are vulnerable to malicious attacks that can steal funds, hack systems, and cause depegging and liquidity attacks. By creating a system to detect these attacks in advance, web3 services can prepare a quick response plan and protect their users from harm.
2.2.2 Collaboration & Governance Initiatives
Fully On-Chain DAOs — Decentralized autonomous organizations (DAOs) rely heavily on off-chain tooling to effectively execute governance and public funds. By building an on-chain data processing flow to create a transparent process for DAO operations, the web3 native values of DAOs can be further strengthened.
Mitigating Governance Fatigue — Web3 protocol decisions are often made through community governance. However, there are a number of factors that can make it difficult for participants to engage in governance, such as geographic barriers, the pressure of monitoring, the lack of expertise required for governance, governance agendas posted at random times, and inconvenient UX. If a tool can be created that can simplify the processing process from understanding to actual implementation of individual governance agenda items for participants, the protocol governance framework can operate more efficiently and effectively.
Open Data Platform for Collaborative Works — In the existing academic and industrial circles, many data and research materials are not publicly disclosed, which can make the overall development of the market very inefficient. On-chain data pools, on the other hand, can promote more collaborative initiatives than existing markets because they are transparent and accessible to anyone. The development of numerous token standards and DeFi solutions are good examples of this. In addition, we can operate public data pools for a variety of purposes.
2.2.3 Network Diagnosis
Index Research — Web3 users create a variety of indicators to analyze and compare the state of protocols. Multiple objective indicators for that can be studied and displayed in real-time. (e.g., Nakamoto Coefficients by Nakaflow)
Protocol Metrics — The performance of a protocol can be analyzed by processing data such as the number of active addresses, the number of transactions, the asset inflow/outflow, and the fees incurred in the network. This information can be used to assess the impact of specific protocol updates, the status of MEV, and the health of the network. (e.g., Post-Shanghai: What Really Happened by Glassnode)
On-chain data has unique advantages that can be used to increase the value of the industry. However, in order for these to be fully realized, many challenges must be addressed, both within and outside the industry.
Absence of Data Governance — Data governance is the process of establishing consistent and shared data policies and standards to facilitate the integration of each data primitive. Currently, each on-chain protocol establishes its own standards and retrieves its own data types. However, the problem is that there is no data governance between entities that aggregate these protocol data and provide API services to users. This makes it difficult for services to integrate with each other, and as a result, users are having difficulty seeing reliable and comprehensive insights.
Cost Inefficiency — Storing cold data in the protocol can save users money on data security and server costs. However, if the data needs to be accessed frequently for data analysis or requires a lot of computing power, storing it on the blockchain may not be cost-effective.
Oracle Problem — Smart contracts can only be fully realized if they have access to data from the real world. However, this data is not always reliable or consistent. Unlike blockchains that maintain integrity through consensus algorithms, external data is not deterministic. Oracle solutions must continue to evolve to ensure the integrity, quality, and scalability of external data without relying on a specific application layer.
Protocols are Nascent — Protocols use their own tokens to incentivize users to keep the service running and to pay for services. However, the parameters required to operate a protocol, such as the precise definition of service users and the incentive scheme, are often managed naively. This means that the economic sustainability of protocols is difficult to verify. If many protocols are organically connected and create a data pipeline, the uncertainty of whether the pipeline can work well will be even greater.
Slow Data Retrieving Time — Protocols typically process transactions through the consensus of many nodes, which can limit the speed and amount of information that can be processed compared to traditional IT business logic. This type of bottleneck can be difficult to resolve unless the performance of all the protocols that make up the pipeline is significantly improved.
True Value of Web3 Data — Blockchains are isolated systems that are not yet connected to the real world. When collecting data from Web3, we need to consider whether the data collected can provide meaningful insights, enough to pay the cost of building a data pipeline.
Unfamiliar Grammar — Existing IT data infrastructure and blockchain infrastructure operate in very different ways. Even the programming languages used are different, with blockchain infrastructure often using low-level languages or new languages that are designed for the specific needs of blockchains. This can make it difficult for new developers and service users to learn how to work with each data primitive, as they need to learn a new programming language or a new way of thinking about blockchain data.
The current Web3 data primitives are not connected to each other, and they extract and process data independently. This makes it difficult to experiment with the synergies of information processing. To address this, this article introduces the data pipeline that is commonly used in the IT market, and project the existing Web3 data primitives to the pipeline. This will make the use case scenarios more concrete.
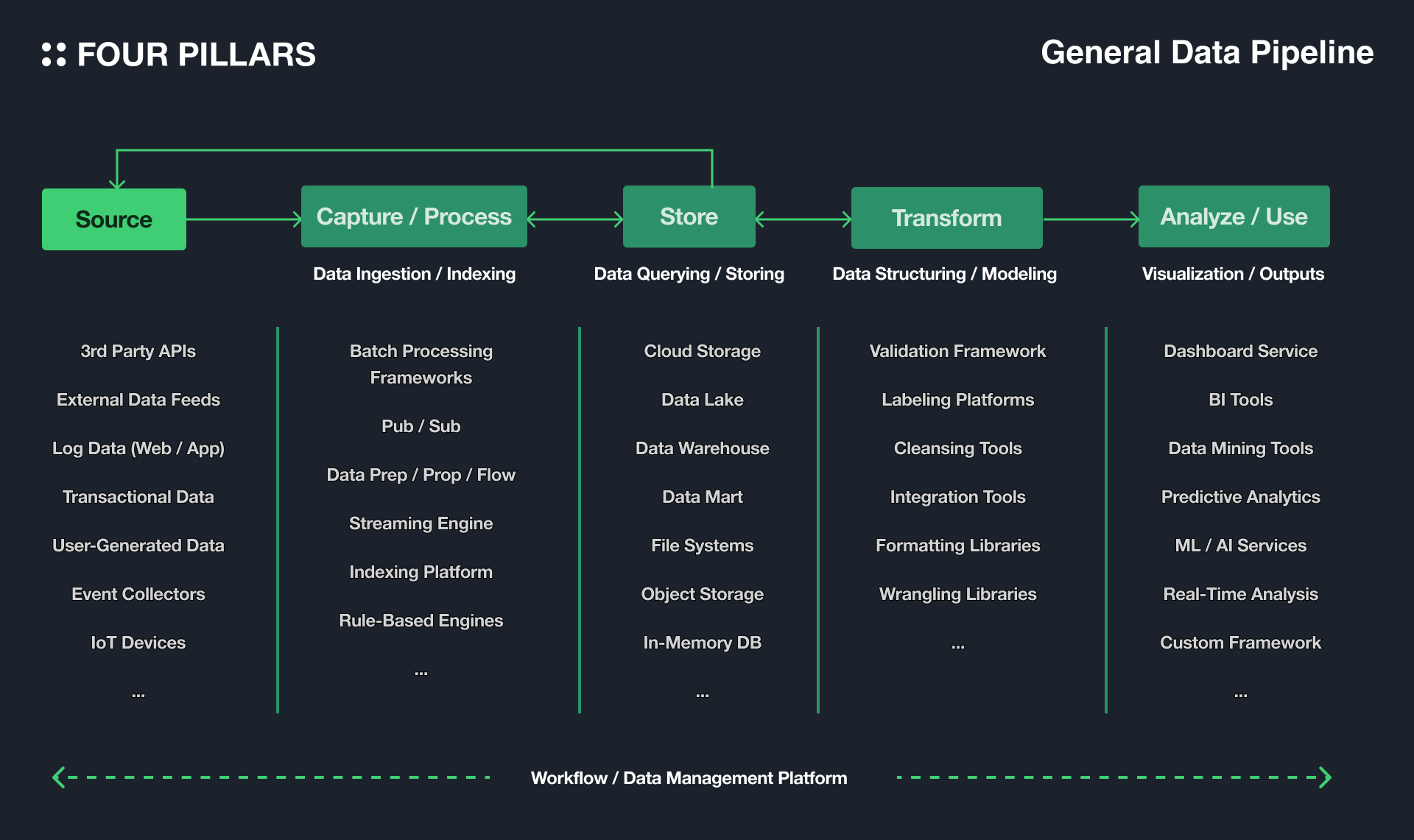
Data pipeline construction is like a process of conceptualizing and automating the repetitive decision-making process in everyday life. By doing this, people can receive the necessary information of a certain quality at any time, and use it for decision-making. The more unstructured data to be processed, the more frequently the information is used, or the more real-time analysis is required, the more time and cost can be saved in acquiring the initiative necessary for future decision-making by automating these series of processes.
The diagram above shows the general architecture used to build data pipelines in the existing IT infrastructure market. The data that is suitable for the analysis purpose is collected from the correct data source, and stored in the appropriate storage solution according to the nature of the data and the analytical requirements. For example, data lakes provide storage solutions for raw data for scalable and flexible analysis, while data warehouses focus on storing structured data for queries and analysis optimized for specific business logic. The data is then processed into insights in various ways or into information for practical use.
Each tier of solutions can also be provided in the form of a packaged service. ETL (Extraction, Transformation, Loading) SaaS product groups that have linked a series of processes from data extraction to loading are also attracting increasing attention (e.g., FiveTran, Panoply, Hivo, Rivery). The order is not always one-way, and the tiers can be linked together in a variety of ways depending on the specific needs of the organization. The most important thing to keep in mind when building a data pipeline is to minimize the risk of data loss that can occur when data is sent and received to each tier of servers. This can be done by optimizing the degree of decoupling of servers and by using reliable data storage and processing solutions.
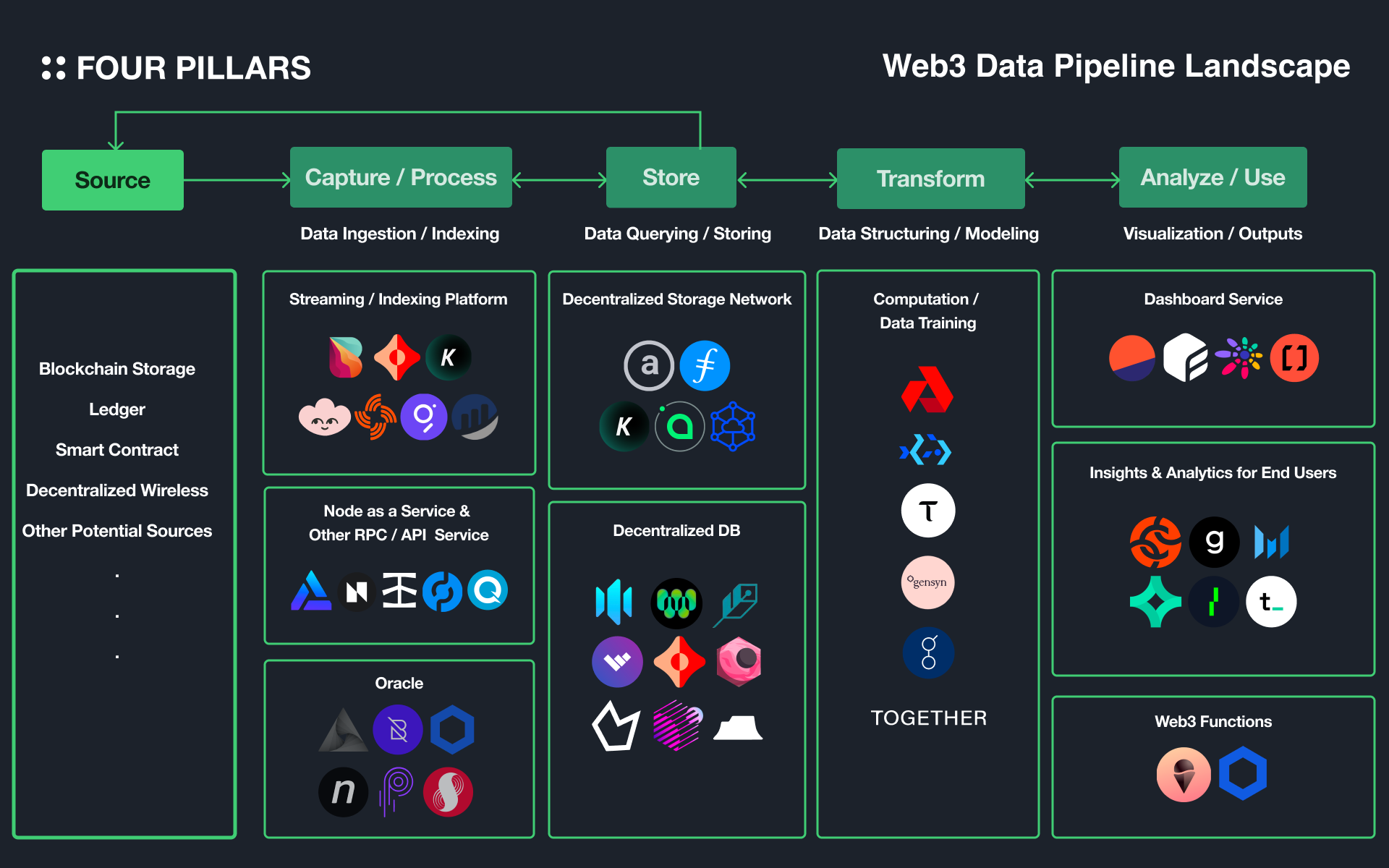
The concept diagram of the data pipeline introduced earlier can be applied to the on-chain context as shown above, but it is important to note that a perfectly decentralized pipeline cannot be formed because each primitive can rely to some extent on centralized off-chain solutions. Additionally, the above figure does not currently include all Web3 solutions, and the boundaries of the classification may be ambiguous — for examples, KYVE includes the functionality of a data lake in addition to a streaming platform, and it can be seen as a data pipeline itself. Additionally, Space and Time is classified as a decentralized database, but it provides API gateway services such as RestAPI and streaming, as well as ETL services. Please consider these limitations when using the above figure.
3.2.1 CAPTURE / PROCESS
In order for general users or dApps to use/operate services efficiently, they need to be able to easily identify and access data sources that are primarily generated within the protocol, such as transactions, state, and log events. This tier is a step in which a kind of middleware plays a role in helping such a process including oracles, messaging, authentication, and API management. The main solutions are as follows.
Streaming / Indexing Platform
Bitquery, Ceramic, KYVE, Lens, Streamr Network, The Graph, Block Explorers for Each Protocols, etc.
Node as a Service & Other RPC/API Service
Alchemy, All that Node, Infura, Pocket Network, Quicknode, etc.
Oracle
API3, Band Protocol, Chainlink, Nest Protocol, Pyth, SupraOracles, etc.
3.2.2 STORE
Web3 storage solutions have several advantages over Web2 storage solutions, such as persistence* and decentralization. However, they also have some disadvantages, such as high cost and difficulty in updating and querying data. As such, various solutions have emerged that can address these disadvantages and enable efficient processing of structured and dynamic data on Web3 — the features of each solution vary, such as the type of data handled, whether it is structured or not, and whether it has an embedded query function.
Decentralized Storage Network
Arweave, Filecoin, KYVE, Sia, Storj, etc.
Decentralized Database
Arweave-Based Databases(Glacier, HollowDB, Kwil, WeaveDB), ComposeDB, OrbitDB, Polybase, Space and Time, Tableland, etc.
*Each protocol has a different mechanism for permanent storage. For example, Arweave is a blockchain-based model, like Ethereum storage, and permanently stores data on-chain, while Filecoin, Sia, and Storj are contract-based models that store data off-chain.
3.2.3 TRANSFORM
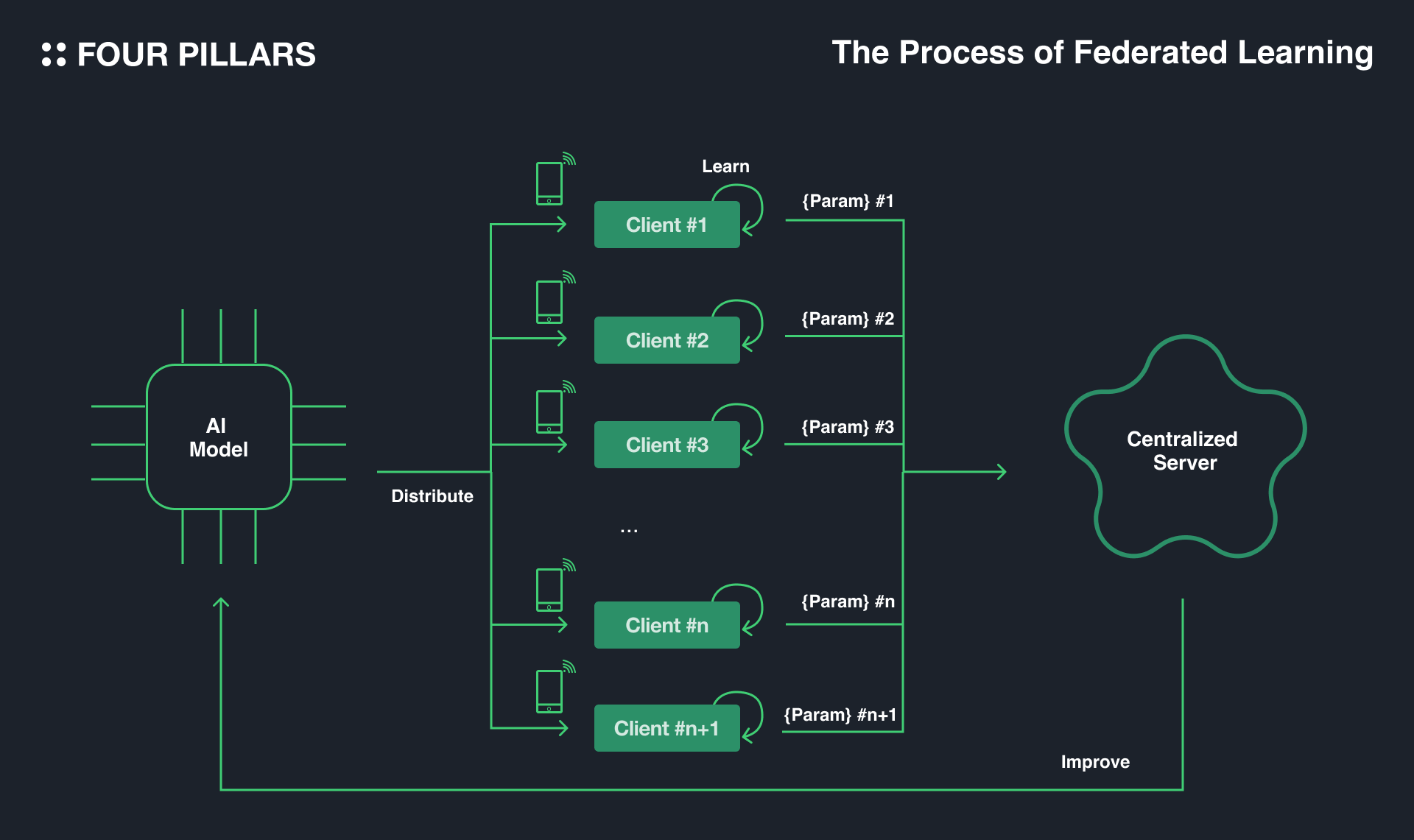
The TRANSFORM tier is expected to be as important as the STORE tier in the context of Web3. This is because the structure of a blockchain consists of basically collection of distributed nodes, which makes it easy to implement backend logic with scaling-out. In the AI industry, there are active efforts to explore the field of federated learning* using these advantages, and protocols specialized for machine learning and AI operations are also emerging.
Data Training / Modeling / Computation
Akash, Bacalhau, Bittensor, Gensyn, Golem, Together, etc.
*Federated learning is a way of training artificial intelligence models by distributing original models on multiple local clients, training them with stored data, and then collecting the learned parameters on a central server.
3.2.4 ANALYZE / USE
The Dashboard Service and Insights & Analytics for End Users solutions listed below are platforms that allow users to observe and derive various insights from all events that occur in specific protocols. Some of these solutions also provide API services for final products. However, it is important to note that the data in these solutions is not always accurate, as most of them use separate off-chain tools to store and process data. Errors between solutions can also be observed.
Meanwhile, there is a platform called ‘Web3 Functions’ that automates/triggers the execution of smart contracts, just as centralized platforms such as Google Cloud trigger/execute specific business logic. Using this platform, users can implement business logic in a Web3 native way, beyond simply deriving insights through the processing of on-chain data.
Dashboard Service
Dune Analytics, Flipside Crypto, Footprint, Transpose, etc.
Insights & Analytics for End Users
Chainalaysis, Glassnode, Messari, Nansen, The Tie, Token Terminal, etc.
Web3 Functions
Chainlink’s Functions, Gelato Network, etc.

Source : Critique of Pure Reason by Immanuel Kant
As Kant argued, we may only witness the phenomenon of things, not their essence. Nevertheless, we have used the observational records called ‘data’ to process information and knowledge, and we have seen how the innovation in informatics can develop civilization. Therefore, the construction of a data pipeline in the Web3 market, which is expected to have various values in addition to the characteristic of decentralization, can play a key role as a starting point for actually capturing such opportunities. I would like to conclude this article with a few final thoughts.
The most important prerequisite for having a data pipeline is to establish data and API governance. In an increasingly diversified ecosystem, the specifications created by each protocol will continue to be created anew, and the fragmented transaction records through the multi-chain ecosystem will make it more difficult for individuals to derive integrated insights. Then, the “storage solution” is the entity that can best provide integrated data in a unified format by collecting fragmented information and updating the specifications of each protocol. We observed that storage solutions such as Snowflake and Databricks in the existing market are quickly growing with vast customer bases, vertically integrating by operating various tiers in the pipeline, and leading the industry.
When data becomes more accessible and the process of processing it improves, successful use cases begin to emerge. And this creates a flywheel effect, in which data source and collection tools emerge explosively — the type and amount of digital data collected each year is increasing exponentially, as the technology for building data pipelines has made great progress since the 2010s. Applying this context to Web3 market, many data sources can be recursively generated on-chain in the future. This also means that blockchains will expand into a variety of business sectors. At this point, we can expect that data sourcing will be advanced through data markets such as Ocean Protocol, or DeWi (Decentralized Wireless) solutions such as Helium and XNET as well as storage solutions.
However, the most important thing is to constantly ask what data to prepare to extract the insights that are really needed. There is nothing more wasteful than building a data pipeline for the sake of building it without a clear hypothesis to verify. The existing market has been able to achieve numerous innovations through the construction of data pipelines, but it has also sacrificed countless costs through repeated meaningless failures. It is also nice to have a constructive discussion for the development of technical stacks, but the industry needs time to think and discuss more fundamental topics, such as what data should be stored in the block space, or for what purpose data should be used. The ‘Goal’ should be to achieve the value of Web3 through actionable intelligence and use cases, and in this process, developing multiple primitives and completing the pipeline are the ‘Means’ to that goal.
Thanks to Kate for designing the graphics for this article.
Dive into 'Narratives' that will be important in the next year