The current AI industry lacks transparency and trust throughout the lifecycle of AI model development. Additionally, high entry barriers limit the expansion of AI applications across various industries.
To address these challenges, federated learning adopts an approach where models are distributed to local clients for independent training. Only the trained parameters are aggregated to update the global model. This method holds significant potential for reducing the overall cost of developing global models and minimizing the exposure of sensitive personal data, thereby greatly enhancing usability.
However, federated learning also faces its own limitations. Key challenges include the difficulty of recruiting a sufficiently diverse and honest pool of participants for model training and the reliance on centralized servers for certain operational tasks.
FLock.io aims to overcome these limitations by integrating various blockchain elements with federated learning methodologies. Its ultimate goal is to democratize the entire AI model lifecycle—from data collection and model proposal to training and application—paving the way for a more creative and trustworthy AI industry.
You and only you are responsible for your life choices and decisions.
— Robert T. Kiyosaki
Average adult makes approximately 35,000 decisions, big and small, every day (Sollisch, 2016). While most of these decisions are likely made intuitively and instantly, we often invest considerable time and resources in seeking justification for our choices because we want them to be the best possible decisions.
The widespread adoption of AI-based services today reflects this phenomenon. In the information-saturated digital landscape, we actively embrace AI-curated information—and sometimes even pay for it—to quickly acquire refined data or to find the solution most optimized for our specific context.
However, we must closely examine the flipside of this convenience: Can we truly trust the outcomes these services provide? Do these outcomes adequately reflect our needs? Can we expect consistent quality from AI services across various industries?
While it is undeniable that AI technology has advanced at an astonishing pace, if it cannot yet offer clear answers to such questions, we must remain cautious. Overreliance on AI services could lead to a loss of autonomy or even decision paralysis.
Even from a structural perspective, it is intuitive to recognize that the outputs produced by AI-powered services cannot be fully trusted. One of the most well-known reasons is the inability to logically explain the inference process behind these outputs (i.e., the "black box" problem) - the inference process typically involves interactions among millions to billions of parameters through complex mathematical computations. This intricate structure makes it challenging to understand how the model functions, significantly weakening the justification for trusting its outputs.
Moreover, the reliability of the data used for training AI is another critical issue. The datasets used for AI training are often insufficient to derive generalized conclusions and are likely to be biased. Additionally, the amount of data available for training is highly limited compared to the rapid generation of new, up-to-date data, and the preprocessing of such data for inference often results in a loss of contextual information. Furthermore, when AI services aim to deliver personalized and tailored experiences to users, they may require sensitive or contextual data from them. However, such data is often difficult to collect, which could result in an insufficient dataset for effective learning. After all, individuals cannot be expected to constantly store dynamic contextual data for every decision-making moment, nor would they want to, due to privacy concerns.
A particularly notable obstacle hindering AI technology adoption across various industries is the high operational cost, in addition to these inherent challenges. Advancing AI requires the construction of data pipelining infrastructures that involve the collection of diverse datasets and the iterative experimentation with numerous models. However, setting up and maintaining such infrastructures demands astronomical costs. In other words, research and development of new AI models and services inherently require substantial capital, creating significant entry barriers for industries or new players with limited financial resources.
Ultimately, for AI-driven services to become optimized, trustworthy, and widely adopted across various fields—thereby synergizing with existing industries—the current methods of AI advancement must undergo structural reformation. This includes the reliable collection of more diverse and contextual datasets and the establishment of new mechanisms and governance structures that lower entry barriers for a broader range of researchers and companies. If, at this juncture where the demand and reliance on AI services for decision-making are accelerating, skepticism about their functionality and trustworthiness fades and users simply accept the information provided, the industry will struggle to grow creatively and competitively. At the same time, this could result in a more monotonous and less dynamic quality of life for individuals.
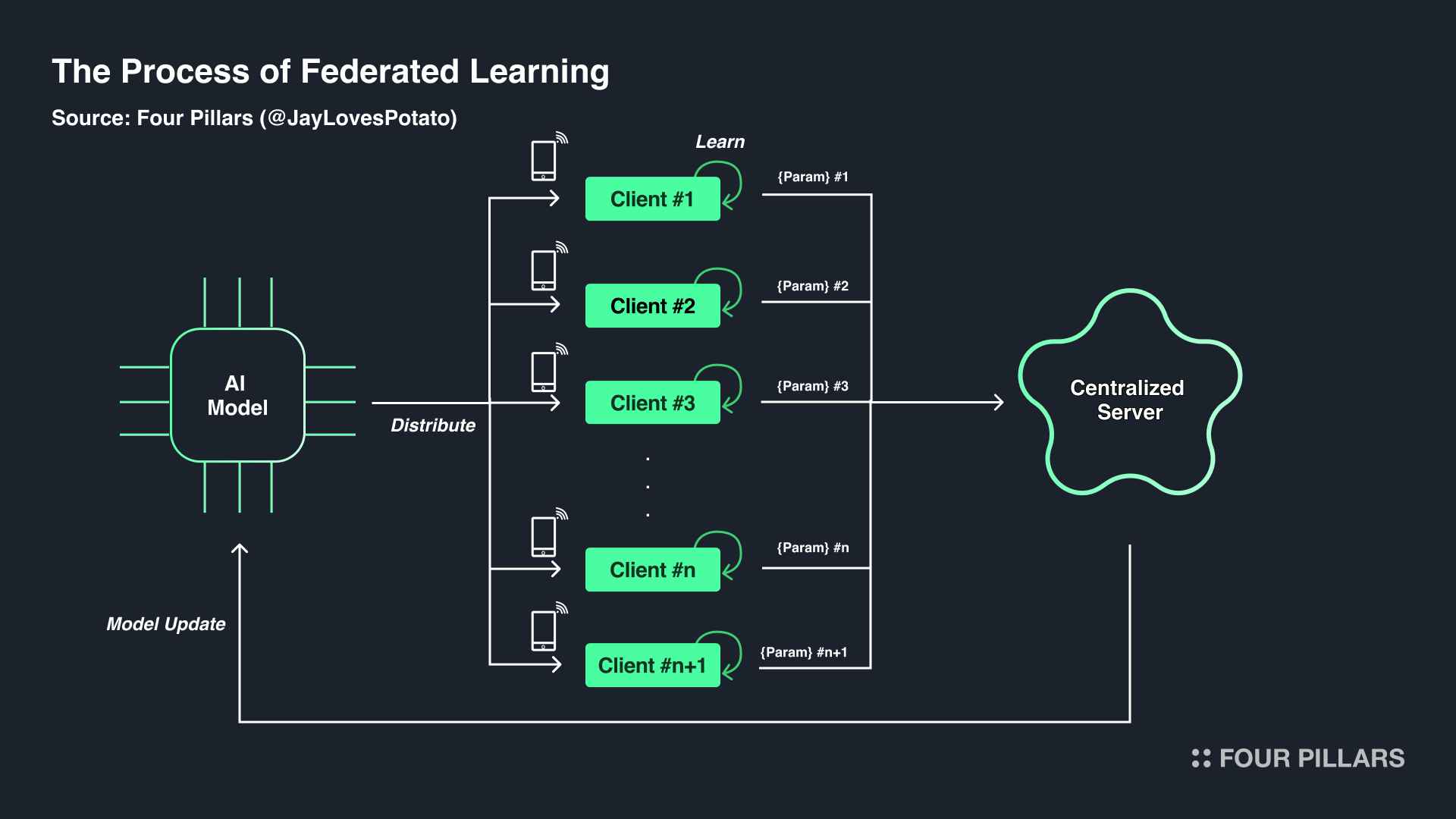
Efforts to address structural challenges in the traditional AI industry have not been absent. Federated learning stands out as a notable example in this context.
First proposed in a paper by McMahan, H. B., and other Google researchers, federated learning introduces a fundamentally different approach compared to conventional AI models that rely on centralized servers to collect and train on all data. Instead, it sends AI base models to local clients, each with unique datasets, enabling real-time training on their devices. The central server then aggregates the parameters trained on these local datasets to build a global model, which is subsequently sent back to the local clients for further updates. This iterative process continues until the final model is fully made.
In essence, participants (e.g., hospitals, companies, individuals) retain their data locally and contribute to model training by sharing only the learned parameters with the central server. This eliminates concerns about exposing original data to third parties. Moreover, since participants receive the model structure and initial parameters directly from the central server, they can transparently verify how their data is processed and utilized, fostering trust in the final model (i.e., a "white-box" approach).
Furthermore, the method of model improvement by the central server—calculating a weighted average of the parameters trained by multiple clients—can, in some cases, produce models that are more objective and contextually relevant than those developed using traditional hyperparameter tuning. Additionally, since data storage and computation for training occur entirely on local clients, federated learning offers advantages in terms of reducing overall storage and computation costs for model development.
The applications of federated learning are vast. Its most prominent use cases include services leveraging sensitive personal data that are challenging to collect due to privacy concerns (e.g., financial or medical data), personalized AI agents, and real-time custom logic development for autonomous vehicles that continuously learn from large-scale up-to-date data to implement driving algorithms.
Despite its numerous advantages, federated learning has yet to see widespread adoption across various industries. The primary limitations can be summarized as follows:
Communication Overhead and Centralized Server Dependency
When a federated learning network involves tens or even hundreds of millions of devices, communication between the centralized server and the clients can become overloaded. Addressing this requires solutions to enhance communication efficiency, such as reducing the total number of communications, minimizing the number of communication clients, or implementing techniques like model compression to reduce the size of transmitted data. These approaches need to be carefully considered and tailored to the specific modeling requirements.
Although some computations are performed on local clients, the centralized server ultimately updates the global model, introducing a potential single point of failure.
Vulnerability to Model/Data Poisoning
Poisoning attacks involve introducing maliciously corrupted data into the training process, significantly degrading the performance of the final model. Due to the structure of federated learning, even a small number of attackers can launch a successful attack on the network.
Additionally, because federated learning only shares model parameter updates from local clients, it becomes challenging for the server to identify malicious clients.
Systematic/Statistical Heterogeneity and Difficulty in Securing Active Clients
AI model training typically assumes that the collected data is independent and identically distributed (i.e., IID). Securing a sufficient volume of data (or clients) is therefore critical.
However, the likelihood of clients participating in federated learning having unbiased conditions (e.g., storage, computation, and communication capabilities) cannot be overlooked. Furthermore, as noted in the context of poisoning attacks, federated learning can be compromised by just a few malicious actors, which limits the number of controllable training nodes that can participate.
Vulnerability to Evasion Attack
Evasion attacks involve minimal manipulation of input data to mislead the model into incorrect learning (e.g., adding imperceptible noise to original data to maximize the model's loss function).
In federated learning, attackers can observe parameters shared across the network, making it easier to modify already optimized parameters through such attacks.
In essence, the fundamental challenges of federated learning stem from the difficulty in recruiting a diverse and sufficient number of active and honest participants for model training, as well as the design's continued reliance on centralized servers for certain critical operations.
In this context, integrating blockchain into the existing architecture of federated learning can address many of the challenges the technology currently faces and drive significant advancements. At its core, blockchain establishes a system that incentivizes diverse participants to contribute to platform operations by implementing a transparent and verifiable network structure.
For example, a federated learning platform can decentralize the authority and roles of a central server by introducing an incentive mechanism that assigns various roles within the network and provides motivations for participation. Moreover, by implementing a PoS structure that penalizes malicious actions and distributes rewards based on contributions, the platform can maintain the quality of model training and validation. Such measures lay the foundation for the platform to effectively counter security threats like poisoning attacks and Sybil attacks.
Source: FLock.io
FLock.io has brought this idea to life by creating a platform where diverse stakeholders—such as general data providers, nodes responsible for training, tuning, and inference, validators in charge of evaluation and verification, and AI developers—can collaborate under an incentive-driven framework to implement a variety of AI models through federated learning. Community members can propose the AI models they need, while AI developers compete on Kaggle-style leaderboards to produce the best-performing models for these requests. The finalized AI models are then distributed on a marketplace for use in various applications.
The ultimate vision of the FLock.io team extends beyond experimental implementations. They aim to democratize the entire lifecycle of AI models—from sourcing reliable data and proposing models to training and deploying them—by applying blockchain technology to federated learning, and advance the AI industry to a more creative and trustworthy level. The team has consistently explored the synergies and complementary aspects of blockchain and federated learning, as evidenced by their extensive portfolio of over 10 academic papers and research outcomes.

3.2.1 Three Pillars of FLock.io Network
Launched as a testnet last May, FLock.io operates as a collaborative framework between three core components: AI Arena, FL Alliance, and the AI Marketplace. This architecture uniquely addresses challenges observed in traditional federated learning by leveraging various elements of blockchain technology.
Before diving into the workflow detailing how models are ultimately developed, here is a brief overview of each component:
AI Arena (Beta Version)
AI Arena serves as a platform where AI models meeting specific requirements are proposed by Task Creators. In this space, base models are selected and initially trained. To propose a model, Task Creators must meet certain qualifications, such as staking a specific amount of network tokens (i.e., $FML) or having relevant experience in the field of machine learning. Currently, the Task Creators are limited to the FLock.io team, but the platform plans to open this role to the community in the future.
Participants can also contribute as Training Nodes (responsible for training models) or Validators (responsible for verifying models). The likelihood of being selected to validate submissions increases with the total stake and delegated shares from the community. However, this increase follows a concave-down growth pattern, meaning the rate of increase diminishes as the total stake grows.
According to the Dashboard, as of November 26, 2024, over 500 Training Nodes and 1,000 Validators are active daily. To date, approximately 18,000 base models have been trained, and over 2 million validations have been performed.
FL Alliance
FL Alliance refines the base models created in AI Arena to produce final global models. Participants, known as FL Nodes, contribute by interacting with off-chain storage through FLocKit and FL clients. They download global models, train them, and re-upload updated weights, thereby contributing to the creation of final models. This aggregation process employs zero-knowledge proofs (as proposed by the FLock.io team here), ensuring that client data remains protected from exposure or peeking.
Similar to AI Arena, FL Nodes must stake a certain amount of $FML tokens to participate in the training process. If the aggregated votes for a given round are not negative, all proposers receive rewards proportional to their staked shares. However, if the result is negative, the staked tokens of all proposers for that round are slashed. Additionally, proposers who fail to participate in a given round also face token slashing.
AI Marketplace
Source: beta.flock.io
The AI Marketplace is a “co-creation” hub where the final models fine-tuned through AI Arena and FL Alliance are hosted. Here, users can either utilize these models as they are or further adapt them for various applications.
The marketplace also allows for ongoing fine-tuning of models, ensuring continuous updates. Participants can contribute to this fine-tuning process using external sources and earn rewards for their efforts - this process, known as Retrieval-Augmented Generation (RAG), improves the performance of large language models (LLMs) like ChatGPT by retrieving facts from external knowledge bases and constructing responses based on the most accurate and up-to-date information.
3.2.2 Workflow of FLock.io Network
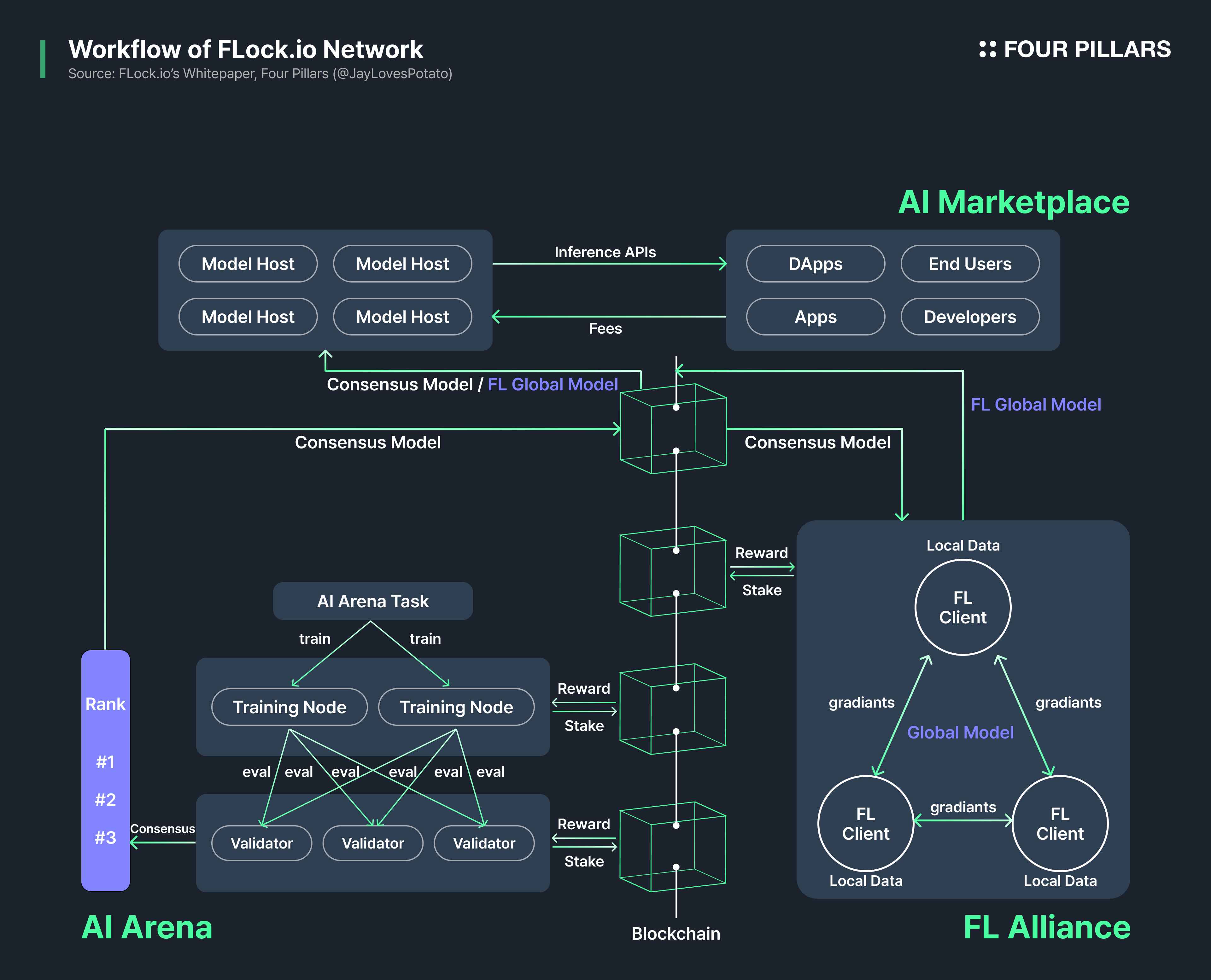
The workflow of the FLock.io network, based on the components above, can be summarized as follows:
Task Creators generate models they wish to train and distribute tasks via the AI Arena.
Training Nodes perform the initial training of the distributed tasks and submit the trained models to Validators for evaluation.
Validators assess the submitted models and rank them through consensus.
The consensus-approved models are assigned to the FL Alliance. Within the FL Alliance, each client is randomly designated as either a Proposer or a Voter for each round. Clients selected as Proposers fine-tune the assigned models using their local data to create improved versions of the FL global model. Voters aggregate the FL global models proposed by the Proposers, evaluate them using their local test datasets, and vote to support or reject the proposed updates.
The global model is finalized based on the aggregated voting results in each round, and rewards are distributed to all participants involved in the FL Alliance task.
The finalized AI Arena consensus model, or FL global model, is then deployed on the AI Marketplace for use in various applications.
By applying a DPoS consensus algorithm and slashing rules throughout both the training phase (i.e., Step #1 ~ #3 for AI Arena) and the fine-tuning phase (i.e., Step #4 ~ #5 for FL Alliance), the FLock.io network effectively mitigates many attack vectors that traditional federated learning approaches face. Additionally, the network introduces a robust reward mechanism tailored to various roles, incentivizing greater participation across the ecosystem.
Since federated learning is one of the methodologies for training AI models, it can fundamentally be applied to all use cases currently served by AI services.
However, as mentioned in the introduction, federated learning is particularly characterized by its relatively better accessibility to highly sensitive and contextual data, assuming active and honest participation from a diverse range of contributors. As a result, use cases stemming from these advantages, as well as those addressing the shortcomings of centralized AI, can become more prominent.
Moreover, the ability for anyone to freely request desired models and specifications on FLock.io enhances synergy across these use cases, fostering the creation of AI models in a more democratic manner.
Domain-Specific & Customized Agent / Assistant
The performance of AI services heavily depends on the data they collect. Federated learning, in particular, allows access to various sensitive data from individuals, enabling the creation of AI models tailored to specific domains or customized to meet particular requirements.
Such services can take diverse forms, including chatbots, agents, or assistants. For instance, FLock.io already offers services like Text2SQL, which converts text into SQL (e.g., Chainbase’s Theia), AI-Assisted coding tools (e.g., Aptos’ Move Code Agent), and various other purpose-specific services (e.g., MOU with Animoca Brands), either already available or in development.
Beyond these examples, federated learning can also be applied to services such as personalized health monitoring based on individual health data, as well as to financial sector applications like trading, credit scoring, fraud detection, and customer service.
Real Time & On-Demand Service
Another significant feature of federated learning platforms like FLock.io, which incentivize diverse participants, is their ability to rapidly gather the latest data from a wide range of contributors. This capability is particularly valuable for tasks where traditional centralized AI systems—relying on precise batch training of large datasets—struggle to keep up. Federated learning-based AI models, equipped with trustworthy and swiftly applied data, can deliver exceptional performance in services that require up-to-date knowledge.
For example, protocol-specific chatbot services like Bitcoin GPT, FLock GPT, and Farcaster GPT available on the FLock.io platform are excellent cases in point. These services dynamically adjust to reflect the complexities of rapidly evolving protocol ecosystems, providing users with continuously refined and updated outputs. This enables users to access more precise and current information compared to conventional services like ChatGPT.
Synergies with Web3 Projects to Build Onchain Data Pipieline
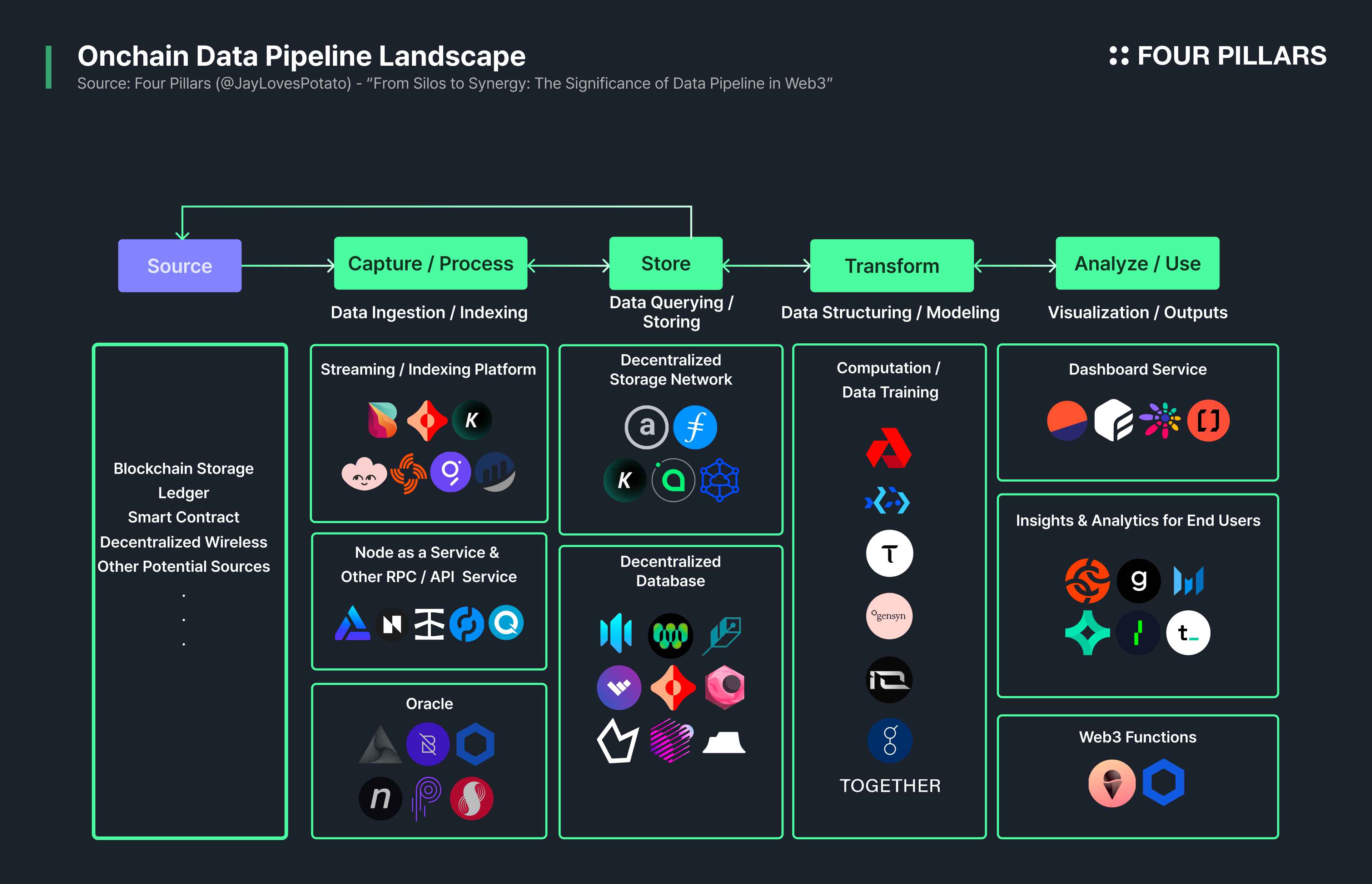
If the two examples above demonstrate how FLock.io can complement existing services, this section highlights its potential to create synergies through collaboration with other onchain projects.
In the traditional IT market, we've witnessed how revolutionary growth in data pipelining infrastructure has led to the discovery of valuable insights, which in turn spurred the creation of groundbreaking applications. Similarly, building an onchain data pipeline can safely distribute onchain data to various stakeholders, uncover meaningful insights for the Web3 ecosystem, and inspire participants to develop diverse Web3-native applications, thereby invigorating the ecosystem.
FLock.io excels particularly in the areas of sourcing and transforming data within the onchain data pipeline, contributing to the generation of impactful AI models. However beyond this, by leveraging synergies with other projects, FLock.io can provide an enhanced infrastructure environment for onchain data pipelining that supports better applications - for instance, FLock.io has organized a hackathon utilizing the computational power of the Akash Network to train models and has further lowered barriers to entry for participants by offering plugins for decentralized hosting networks such as io.net, Gensyn, and Ritual to their services.
Supply Side
The foremost priority for any federated learning platform aiming to attract diverse participants and build a sustainable system is to demonstrate that competitive AI models can be successfully developed through the platform. To achieve this, FLock.io has clearly defined various roles within its ecosystem—including Task Creators, Data Providers, Training Nodes, Validators, Delegators, and FL Nodes—and designed a reward system to ensure each role contributes to the network with optimal performance.
A key aspect of this process is designing the tokenomics to ensure that the tokens supplied through the supply mechanism do not exceed the demand-side requirements. To address this, FLock.io proposes several mechanisms, including charging platform fees (i.e., $FML) or requiring $FML token staking for participation, and implementing token burn mechanisms for certain portion of the protocol’s revenue* - detailed calculations regarding token supply and related mechanisms are thoroughly outlined in the FLock.io Whitepaper.
*However, as FLock.io is still in the testnet phase, it is not yet proved whether the supply mechanisms work well to establish a sustainable economy.
Demand Side
Once the FLock.io platform proves its ability to produce competitive AI models, various forms of demand can emerge. For example, as previously discussed, communities, protocols, academic institutions, and enterprises can request tailored AI models through the platform with payments. These models can also be monetized either through usage fees or ongoing fine-tuning services what is offered in AI marketplaces.
Furthermore, we can anticipate demand from participants who, while not directly engaging in federated learning, delegate their $FML tokens to specific nodes. By doing so, these participants indirectly contribute to improving the platform's overall quality by empowering various network actors to compete and perform at their best, while earning delegation rewards in return. As demand grows and the value of $FML tokens increases, this could, in turn, attract high-quality participants to the network, fostering a virtuous cycle that strengthens the platform*.
*In this context, the $FML token could evolve beyond simply serving as a delegation reward mechanism. It may play a pivotal role as a governance token, enabling the community to participate in governance agendas ranging from technical updates and financial management to other various community initiatives on the FLock.io platform.
ChatGPT demonstrated that the convenience AI technology can bring to our lives has the potential to achieve explosive adoption once it surpasses certain hurdles. And, this convenience has now seamlessly integrated into our daily routines. Consequently, many companies are striving to develop proprietary AI technologies across various fields. However, due to the capital-intensive nature of the industry, such efforts often face significant challenges in achieving success. Of course, as evidenced by numerous adoption cases to date, the benefits offered by centralized AI models are undeniable. This makes it likely that existing large-scale AI model providers will continue to grow rapidly, unveiling groundbreaking new solutions across various fields that may once again astonish us.
Yet, as noted in the introduction, even in such a future, there remains no solid foundation to place complete trust in centralized AI services. This lack of trust can lead to challenges in accessing desired data, leaving AI models perpetually incomplete. This is precisely why we need to democratize AI technology. We can certainly explore ways to overcome the structural limitations of existing industries, enable more people to share in the benefits of AI advancements, and foster creative development of AI across diverse fields.
FLock.io’s blockchain-based federated learning methodology addresses and mitigates inherent issues in the traditional learning approaches of AI models. Beyond that, this approach has the potential to democratize the entire process, from data sourcing to the final creation of AI models, thereby attracting more participants and enabling the emergence of innovative models across a broader spectrum - by allowing individuals without deep prior knowledge of AI to participate, FLock.io democratizes the model creation process. In the stages of model generation and training, it enables access to proprietary data from data providers, fostering the democratization of data. Furthermore, as AI progresses and its societal value increases, this approach ensures that the benefits are widely shared among diverse participants. By enabling anyone to stake and share in these benefits, the distribution of value itself can also be democratized.
Of course, ensuring the network remains stable by maintaining incentives that serve as appealing rewards for high-quality participants and addressing the inherent challenges of federated learning will be critical tasks for FLock.io moving forward. However, at the very least, FLock.io's efforts hold significant meaning in showcasing the potential for AI to act as a unifying force in society—rather than exacerbating divisions—by ensuring fair access and participation in AI technology.
Dive into 'Narratives' that will be important in the next year