
이제는 기존에 존재하는 기술을 그대로 가져다가 새로운 내러티브를 만드는 것만으로는 레이어1 블록체인이 시장성을 갖기 굉장히 어려운 시대가 되었다. 본질부터 다른 기술, 그것만이 새로운 레이어1을 정당화 할 수 있다.
그런면에서, 수이 네트워크는 굉장히 주목할만하다. 컨센서스, 멤풀, 그리고 프로그래밍 언어까지 전부 새롭고 혁신적인 피처들을 가지고 있기 때문이다.
특히나 zkSend나 zkLogin과 같은 기능들은, 앞으로 대중을 위한 블록체인은 어떻게 나아가야 하는지를 보여주는 사례같다는 생각이 든다. 이러한 기술들을 시장의 가장 앞단에서 소개하고 있는 수이야말로, 새로운 레이어1의 존재 정당성을 부여받을 수 있지 않을까.
블록체인은 본질적으로 오픈소스 생태계 위에서 만들어지고, 오픈소스 특성상 프로덕트를 쉽게 모방할 수 있기 때문에 특정 섹터나 산업이 유망하다고 판단되면 수많은 사람들이 시장에 뛰어들어 유사한 프로덕트를 출시하고 경쟁한다. 우리가 2021년과 2022년에 수많은 레이어1 블록체인들이 시장에 나오는 것을 목도할 수 있었던 이유도 오픈소스적 특성을 가지고 있는 블록체인 때문이었을 것이다. 그리고 지금은 이러한 현상이 레이어2로 옮겨갔고 무수히 많은 레이어2 체인들이 시장에 등장하고있다. 그렇다면 이제는 레이어1 블록체인을 구축하는 것이 큰 의미가 없는 것일까? 물론 새로운 레이어1을 구축하는 일은 매우 어렵고 비용도 많이 소모되는 일이다. 그리고 이제는 예전처럼 양산형 레이어1 블록체인들이 시장에 나온다고 주목을 받을 수 있는 시기도 아니다. 그럼에도 불구하고 필자는 아직 레이어1 블록체인이 시장에서 주목을 받을 수 있는 기회는 있다고 생각한다. 물론, 이전과 같은 방식이 아니라 아예 기술적으로 차별화를 한다는 가정을 둔다면 말이다.
이제는 블록체인 인프라 섹터가 굉장히 중요한 국면을 맞이하고 있다고 느낀다. 어떤 시장이던지 수많은 인프라들이 지속적으로 공존하는 시장은 존재하지 않았다. 결국 블록체인도 수많은 인프라들이 완전경쟁을 하는 양상이 아닌, 생각보다 적은 수의 메이저한 인프라들간에 경쟁이 지속될 것이라고 본다(물론 중간중간 혁신적인 인프라를 소개하는 플레이어들이 등장한다면 판도가 바뀔수도 있겠지만 말이다). 그러한 관점에서 앞으로 등장할 레이어1 블록체인들은 자신들이 기존 블록체인들과 어떤 부분이 다르고 왜 다른 레이어1 블록체인들과 공존할 수 있는지를 끊이없이 증명해야 할 것이다.
수많은 블록체인 인프라들 속에서 레이어1 블록체인, 특히 모놀리틱 블록체인(integrated blockchain)이 이 시장에서 유의미한 시장 점유율을 차지할 것이라고 믿는 필자의 입장에서는 이번 사이클에서 기술적인 차별점을 둔 레이어1 블록체인들을 유심히 바라볼 수 밖에 없는데, 흥미로운 것은 이들중에서 매우 재미있는 설계를 한 블록체인들이 꽤 많다는 것이다. 필자가 이번에 소개할 블록체인도 바로 그들 중 하나다. 바로 수이 블록체인(Sui Blockchain)의 이야기다.
이번 아티클에서는 수이 네트워크(Sui Network)에 대한 전반적인 소개와 수이 네트워크가 레이어1 블록체인으로써 가진 차별점에 대해서 이야기 해보고자 한다.
수이가 메타(전 페이스북)에서 개발하던 블록체인인 디엠(전 리브라)팀 그리고 노비(Novi)월렛에서 파생되어 시작된 팀이라는 사실은 이제 시장에 있는 모두가 다 아는 사실이다. 해서, 너무 진부한 사실이기도 하다. 하지만 구체적으로 이들이 디엠팀과 노비팀에서 어떠한 역할과 기여를 했는지에 대해서는 아직까지 많은 사람들이 잘 모르는, 어찌보면 진부하지만은 않은 사실이기도 하다. 해서, 수이의 코파운더들의 배경과 이들이 메타에 있을 때 어떤 일들을 했는지 그리고 더 과거에는 무슨 일들을 했는지를 알아보자.

source: Mysten Labs
현재 수이 네트워크는 수이 파운데이션(Sui Foundation)과 수이 네트워크의 개발사인 미스텐 랩스(Mysten Labs)둘로 나누어져 있고, 수이 네트워크를 만든 파운더들은 전부 미스텐 랩스의 소속이다. 왼쪽 상단부터 한 명씩 살펴보자. 우선 미스텐 랩스의 CEO인 Evan Cheng의 경우 메타 이전에도 애플에서 무려 10년 넘게 일했으며 애플에서 일 하면서 LLVM(Low-Level Virtual Machine이라고 하는 모듈식 컴파일러 프로젝트이고, 일리노이 대학교의 크리스 래트너(Chris Lattner)가 처음 시작하였으나, 이후 애플에서 오랜 시간동안 개발하고 연구한 프로젝트이다. LLVM을 통해 IOS 앱이 더 빠르게 실행될 수 있었다고 알려져있다.)백엔드 팀을 이끌었다. 그리고 LLVM 을 연구한 공로를 인정받아 2013년도에 LLVM을 처음 시작한 크리스 래트너와 함께 ACM Software System Award를 수상하였다.
CPO인 Adeniyi Abiodun은 J.P Morgan과 HSBC에서 시니어 소프트웨어 엔지니어를 역임하고 오라클에서 블록체인 설계를 담당하다가, VMware에서 프로덕트를 총괄한 뒤 메타에서 프로덕트 리드를 지냈다.
CTO인 Sam Blackshear의 경우 메타에서 Principal Engineer을 역임하면서 현재 수이의 프로그래밍 언어인 Move를 창시한 것으로 유명하다. 이외에도 Libra Blockchain에 대한 논문에 참여하는 등 디엠 프로젝트에 큰 기여를 하였다. 현재 수이에서도 단순히 프로그래밍 언어적인 기여 뿐만 아니라, 블록체인 아키텍트를 총괄하는 모습을 보이고 있다.
Chief Scientist 인 George Danezis는 영국의 명문대인 UCL에서 보안과 프라이버시 엔지니어링 교수를 10년째 역임하고 있으며 앨런 튜링(우리가 아는 그 튜링이다)재단에서 펠로우를 지내고 있다. 필자가 George Danezis를 처음 알게된 것은 2022년도에 발표한 Narwhal and Tusk 컨센서스 논문을 냈을 때였다. 그리고 오늘 이 아티클에서 소개할 새로운 컨센서스인 Mysticeti 의 공동 저자이기도 하기 때문에 모놀리틱 블록체인(integrated blockchain)의 컨센서스 디자인에 관심이 많은 필자로서는 가장 익숙한 인물이기도 하다.
Chief Cryptographer 인 Konstantinos Kryptos Chalkias 는 암호학자로 굉장히 유명한데. 메타에서도 암호학 부분을 총괄하기도 하였고, 전에는 R3에서 암호학 부분을 리드했었다. 필자가 포필러스에서 소개했던 수이의 심리스한 온보딩 프레임워크인 zkLogin의 공동 저자이기도 하다. 이 뿐만 아니라 현재 수이쪽에서 열심히 강조하고 있는 zkSend 와 같은 기능들에도 전부 Konstantinos가 있다. 해서 누군가가 필자에게 “모듈러 블록체인 쪽 말고 모놀리틱 블록체인(integrated blockchain)쪽에서 ZK 기술이 어떻게 쓰이냐?”라고 물어볼 때마다 필자는 Konstatinos의 논문과 결과물들을 예시로 들고는 한다.
이처럼, 수이의 코파운더들은 저마다 각자의 분야에서 꽤나 유의미한 성과를 거둔 사람들이고, 지금도 계속해서 다양한 저작물들을 발간하는 연구자들이기도 하다. 필자는 현재 모놀리틱 블록체인(integrated blockchain)을 관심있게 바라보고 연구하는 리서처로서 이들이 주기적으로 내놓는 결과물들에 대해서 큰 관심을 가지고 있고, 지금도 가장 관심을 가지고 팔로우업 하고있는 인물들이기도 하다.
수이 팀의 대부분이 메타에서 블록체인을 개발하던 인력들이고, 이들이 왜 메타를 떠나서 미스텐 랩스를 설립하였는지는 이미 많은 매체에서 다룬 부분이기 때문에 이번 아티클에선 그 부분에 대해서 다루기 보단 좀 더 기술적인 정당성 부분을 다뤄보고자 한다. 수이는 솔라나(Solana), 세이(Sei), 앱토스(Aptos), 모나드(Monad)와 같이 모놀리틱 블록체인(Integrated blockchain)을 대표하는 블록체인이다. 그리고 필자가 위에서 언급했듯, 시장은 레이어1 포화시대를 한 번 거치고 나서 새로운 레이어1에 대해 피로감을 느끼고 있었다(지금도 느끼고 있을 것이다). 그럼에도 불구하고 수이 네트워크는 왜 독자적인 레이어1 블록체인을 런칭했을까?
“스마트 컨트랙트 플랫폼의 유틸리티는, 플랫폼 위에서 상태를 공유하며 작동하는 프로그램들이 서로 아토믹하게(원자적으로) 접근하며 흥미로운 상호작용을 일으킬 수 있는 경우가 많아질수록 높아진다고 생각한다.” by Sam Blackshear(CTO of Mysten Labs)
결국 Sam은 블록체인, 특히 스마트 컨트랙트 플랫폼의 사용성은 얼마나 다양한 애플리케이션들이 얼마나 심리스하게 서로간 상호작용 할 수 있느냐에 달려있다고 보는 것이다. 결국 레이어2 롤업이나 멀티체인 에코시스템을 기반으로 한 생태계들은 각각 독립적이고 고립되어있는 상태(State)를 가지고 있을 것이기 때문에 Sam이 이야기 한 ‘스마트 컨트랙트 플랫폼의 사용성’ 측면에서 일정 부분을 희생할 수 밖에 없다. 결국 다양한 애플리케이션들이 유기적으로 서로 심리스하게 소통하며 상호작용하고, 이를 통해 흥미로운 결과물을 낼 수 있을 때 스마트 컨트랙트 플랫폼의 사용성은 증가한다는 것이다.
결국 풀어서 얘기하면, 수이는 애플리케이션간 심리스한 상호작용이 가능하면서도 수수료가 저렴하고, 이들간의 상호작용이 야기하는 다양한 행동들이 확장성의 제약에 걸려서는 안되며, 레이턴시가 높지 않으면서도 보안적으로도 충분히 뛰어난 환경을 구축하는 것이 목표이다. 사실 이게 말이 쉽지, 이게 구현 가능하다면 수이는 독자적인 블록체인으로써 존재 이유를 검증하는 것이나 다름이 없다고 본다. 수이가 이것들을 증명했을까? 아직은 시간이 더 필요한 시점이라고 생각한다. 하지만, 레이어1 블록체인을 처음부터 독자적으로 개발하는 이유로는 납득 가능한 이유라고 생각된다. 정말로 기술에 자신이 있다면, 특정 생태계나 체인에 의존성이 발생하는 롤업보다는 모든 부분을 스스로 설계하는 것이 더 효율적이고 가치롭기 때문이다.
결국 새로운 레이어1에 대한 경계심이 만연한 지금 이 시장의 분위기 속에서는 기술적으로 굉장히 큰 차별점을 두지 않으면 시장의 주목을 받기 어렵다. 물론 수이의 경우, 메타의 후광을 받고 있고 투자자들도 유명하기 때문에 어느정도 시장에서의 인지도를 올릴 수야 있겠으나, 결국 중요한 것은 단기간의 하이프 형성이 아닌 기술적 차별화를 통한 지속 가능성의 증명이라고 본다. 그렇다면 수이의 기술은 지속 가능성을 증명할만큼 차별성을 두고있을까? 필자는 그렇다고 생각한다. 왜 그런지 수이의 기술에 대해서 하나씩 살펴보자.
수이는 현재도 지속적으로 변화하고 있는 레이어1 체인이다. 예컨데, 지금 당장은 수이가 Narwhal과 Bullshark를 멤풀 프로토콜과 컨센서스 엔진으로 사용하고 있지만, 조만간 새로운 컨센서스인 Mysticeti를 도입할 예정이다. 해서, 필자는 수이의 컨센서스 엔진을 설명할 때 기존의 컨센서스와 앞으로의 컨센서스를 둘 다 설명함으로써 수이의 현재와 미래를 다루어 보려고 한다.

수이의 컨센서스와 멤풀 프로토콜은 미스텐 랩스에서부터 개발이 되었다고 보기엔 무리가 있고, 이들이 메타에서 디엠 블록체인을 설계할 때부터 그 레거시가 이어져 온다고 볼 수 있다. 수이에 적용된 멤풀 프로토콜인 나왈(Narwhal), 그리고 컨센서스 엔진인 불샤크(Bullshark)는 각각의 논문이 있을 정도로 굉장히 심도있는 내용들을 다룬다. 독자들의 이해를 돕기 위해서 이들에 대해 하나씩 설명해보도록 하겠다.
2.1.1 효율적인 멤풀 프로토콜: 나왈(Narwhal)
우선 가장 먼저 설명하고자 하는 것은 나왈(Narwhal)이다. 나왈은 말 그대로 멤풀 프로토콜(mempool Protocol)로 기존 블록체인에서 멤풀에 있는 트랜잭션을 벨리데이터간에 공유하는 방식을 획기적으로 효율화시킨 프로토콜이다. 여기서 주의할 점은, 나왈 자체가 컨센서스 엔진이 아니기 때문에 나왈 혼자서는 사용되기 어렵고 대신 기존에 존재하는 컨센서스 엔진에 나왈을 활용할 수 있는 형태라는 점이다. 맨 처음 나왈이 소개되었을 때도 나왈 자체에 대한 소개 뿐만이 아니라 나왈과 같이 시너지를 낼 수 있는 컨센서스 엔진인 터스크(Tusk)도 같이 소개되었던 것을 보면 알 수 있다. 그럼 나왈과 같은 독자적인 멤풀 프로토콜의 존재 이유는 무엇이며, 나왈이 해결하고자 하는 문제는 무엇일까?
기존 멤풀의 문제점
우선 나왈에 대해서 이해하기 이전에, 멤풀에 대한 이해가 필요하다. 멤풀이란 말 그대로 메모리 풀의 약자이며, 노드들이 아직 검증하기 전에 있는 정보들을 담아놓는 일종의 풀(Pool)로 이해하면 된다. 하지만 여기서 중요한 점은, 블록체인은 상태를 공유하는 데이터 베이스지만, 멤풀은 각각의 벨리데이터들이 로컬에 멤풀을 가지고 있는 형태라서 결국 이 데이터들도 서로 공유하고 검증해야지만 이들을 블록에 담아서 최종적으로 합의를 할 수 있다는 부분이다. 기존에 존재하는 블록체인들은 벨리데이터가 모든 트랜잭션들을 다른 벨리데이터들에게 전파해서 검증하고 검증된 데이터를 다시 블록에 담아서 해당 블록을 전파하는 형태의 이중 전파(double transmission) 문제가 발생한다. 뭐 엄밀히 말하면 두 번 전파하는 것이 문제는 아니다. 다만, 합의에 부하를 준다는 측면에서 문제가 된다고 볼 수는 있다. 특별히 문제가 없다면 벨리데이터들이 로컬에 저장하고 있는 멤풀 데이터들이 맞는 데이터인지만 검증한다면 굳이 모든 트랜잭션 데이터들을 벨리데이터들간에 주고받을 이유는 없을 것이기 때문이다.
Narwhal Kicks In
만약에 벨리데이터들간에 모든 트랜잭션 데이터를 주고받지 않고, 각각 벨리데이터의 로컬 멤풀에 저장된 데이터들이 일치하는지만 확인하는 과정으로 간소화하면 어떨까? 즉, 트랜잭션 데이터들이 기존 블록체인들과 같이 컨센서스 프로세스에 포함되는 것이 아니라, 멤풀은 멤풀대로 처리하고 그리고 합의는 메타데이터(블록헤더와 해시들)를 기반으로 컨센서스를 진행한다면 훨씬 더 효율적일 것이다. 사실상 이것이 나왈에 대한 간략한 설명이라고 볼 수 있다. 하지만 나왈에 대해서 자세히 다루지 않으면, 리서치 페이퍼의 의미도 없다. 한 번 나왈이 어떻게 기존 멤풀 데이터 전파 과정을 간소화 하였는지 알아볼까?
Workers and Primaries
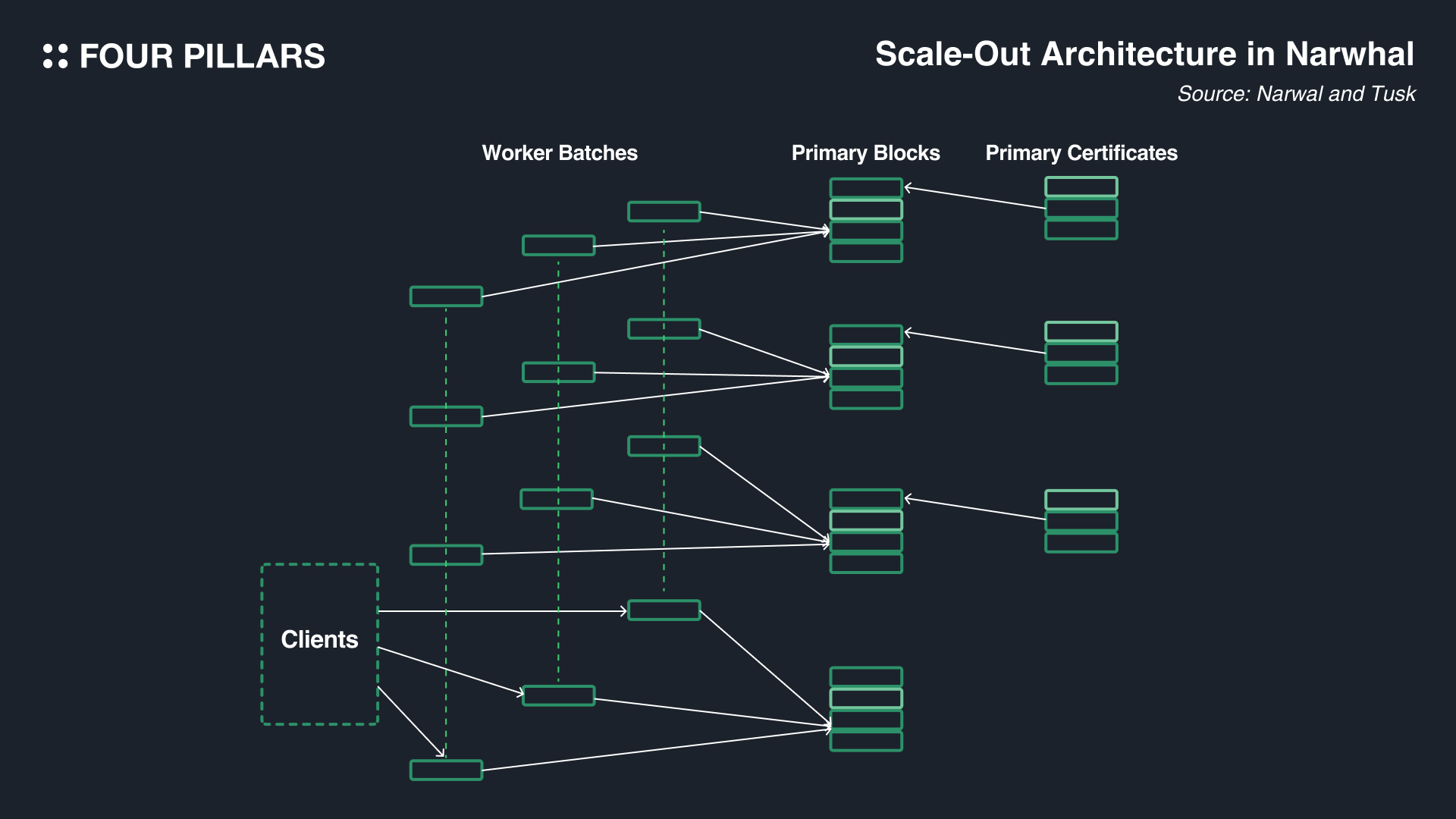
우선 나왈의 구조를 이해하기 위해선, 워커(worker)와 프라이머리(primary)라는 두 주체에 대한 이해가 선행되어야 한다. 벨리데이터 안에는 다수의 워커 머신들을 둘 수 있고(현재 수이에서는 다수의 워커 머신을 돌릴 수 없지만 나중에 다수의 워커를 운영할 수 있도록 할 수도 있기 때문에 일단은 다수의 워커 머신을 기준으로 설명하도록 하겠다), 각각의 다른 워커들은 다른 트랜잭션 데이터를 전파하기 때문에 트랜잭션 전파 과정을 병렬로 처리할 수 있다. 반면 프라이머리는 벨리데이터마다 하나씩만 존재한다.
여기서 워커들은 클라이언트에게 전파받은 트랜잭션 데이터를 묶은 다음에(bathcing)해당 배치의 해시(hash)를 다른 벨리데이터들의 워커에게 전파하는 역할을 한다. 또한 워커들은 트랜잭션 배치들의 해시를 프라이머리에게도 전달한다. 그러면 프라이머리들은 전파 받은 해시를 기반으로 트랜잭션 리스트를 만든다. 그리고 그 리스트는 block에 담기는 방식이다.
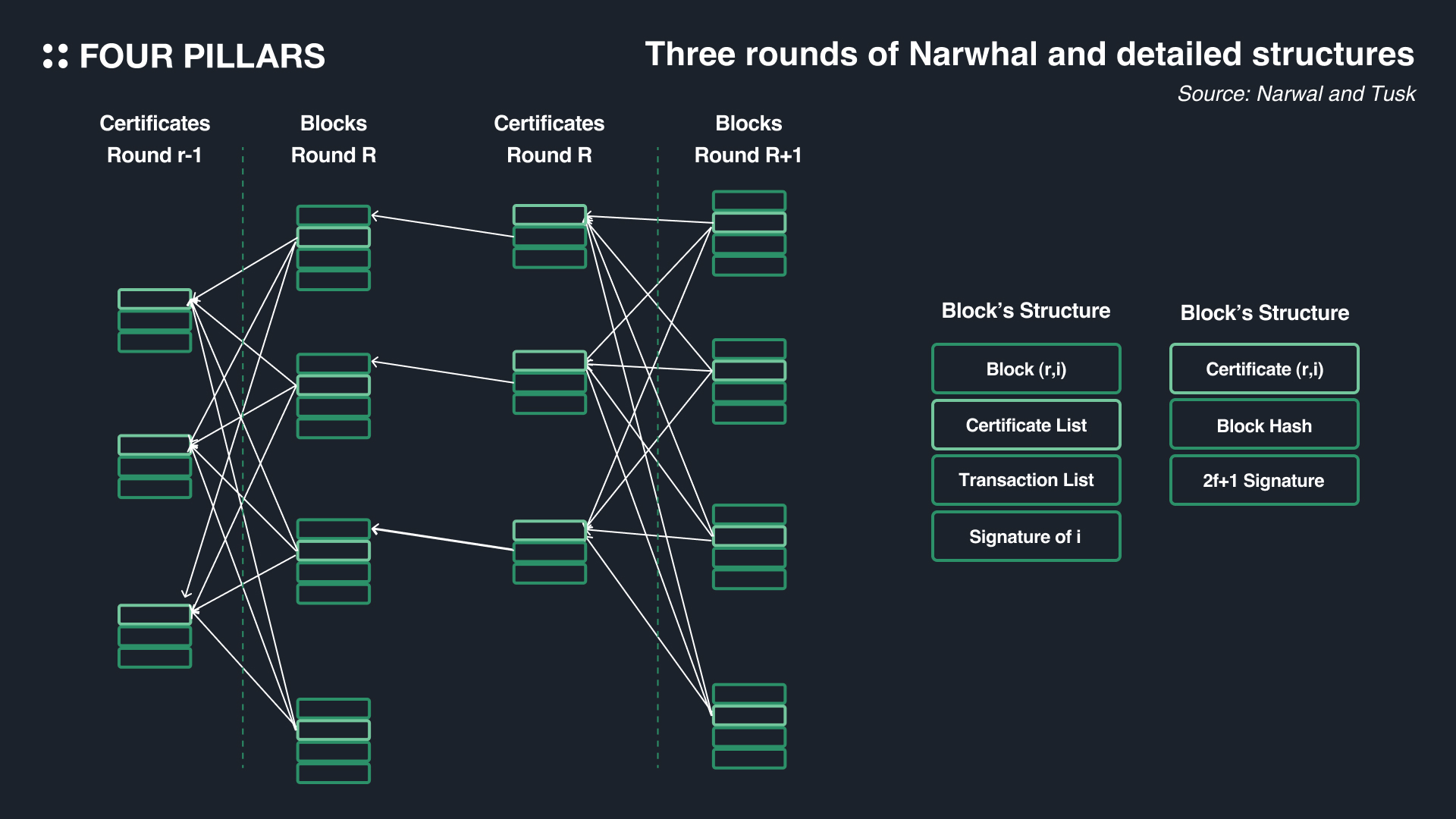
그렇게 만들어진 블록은 리더 벨리데이터를 통해 다른 벨리데이터들에게도 전달되고, 벨리데이터들은 해당 블록에 대한 서명을 진행한다. 서명이 2f+1(BFT 컨센서스 상에서의 정족수(quorum)로, f는 BFT에서 용인될 수 있는 악의적인 노드나 잘못된 노드의 수를 의미한다. 나왈은 컨센서스 엔진과 별도이지만 정족수의 기준은 나왈과 함께 적용된 컨센서스 엔진이 무엇이냐에 따라서 상이할 수 있다는 점을 참고하자)개 이상을 받았다면 증명서(certificate)를 발급받고 리더는 해당 증명서 역시 다른 벨리데이터들에게 전파한다(이를 통해 벨리데이터들이 다음 라운드 블록에 이전 라운드의 증명서를 포함시킬 수 있다). 그리고 증명서를 2f+1 개의 벨리데이터들에게 쌓인 것을 확인한다면, 리더는 그 다음 라운드로 넘어간다. 그 다음 라운드의 블록은, 블록 생산자에 대한 정보와 서명, 트랜잭션 리스트, 그리고 증명서 리스트등으로 이루어진다. 블록의 구조를 보면 certificate list가 바로 이전 라운드들의 증명서를 참고한 것이라고 볼 수 있다.
이렇게 얻어진 증명서는 결국 벨리데이터들로 하여금 자기와 다른 벨리데이터들이 같은 데이터들을 가지고 있는지를 증명하는 역할을 하기 때문에 이를 통해 벨리데이터들은 각자가 가지고 있는 데이터들의 싱크를 맞출 수 있게 된다. 나왈은 두 가지 측면에서 블록체인의 속도 향상에 도움을 준다: 1) 기존 멤풀 프로토콜은 트랜잭션 단위로 노드간 소통을 했던 반면, 나왈은 트랜잭션 배치들이 담긴 블록 단위로 노드간 소통을 하기 때문에 훨씬 더 효율적이다 2)트랜잭션 오더링 과정과 완전히 분리돼서 진행되기 때문에 나왈이 트랜잭션 데이터를 전파하고 보장하는 동안 컨센서스 엔진(밑에서 설명할 불샤크나, 터스크나 핫스터프 같은)은 해당 트랜잭션을 오더링하고 합의하는 역할을 하기 때문에 기존 컨센서스 보다 훨씬 더 빠른 속도로 합의가 가능하다. 분업의 효과인 것이다.
2.1.2 컨센서스는 그럼 어떨까?: 불샤크(Bullshark) 의 등장
나왈이 트랜잭션 데이터의 전파를 담당한다면, 트랜잭션의 순서를 정하는 오더링 로직은 불샤크가 담당한다. 불샤크도 나왈과 같이 DAG(Directed Acyclic Graph) 방식으로 이루어져있는데, 우선 불샤크에 대해서 잘 이해하기 위해서는 DAG의 구조에 대해서 이해할 필요가 있다.
DAG는 “한 방향으로 이어지지만, 순환은 하지 않는 그래프 형태”라고 할 수 있다. 그 구조는 꼭짓점(Vertex)과 꼭짓점들을 이어주는 간선(Edge)들로 이루어져있고 서로가 연결되며 서로를 직/간접적으로 검증하는 형태를 보인다. 결국 이 꼭짓점들과 간선들은 이어지는 순서(order)가 존재하는데, 이것을 우리는 커주얼 오더(Casual Order)라고 부르며 만약 컨센서스에 참여하는 모든 벨리데이터들이 하나의 방향과 값을 가지고 있는 DAG를 가지고 있다면, 우리는 벨리데이터들이 모두 같은 전순서(Total Order)에 도달했다고 할 수 있다. 결국 불샤크는 어떻게 (선량한)벨리데이터들이 효율적으로 전 순서에 도달하게 만들 수 있느냐에 대한 방법론이라고 볼 수 있다. 하지만 이게 결코 쉬운일은 아니다. 벨리데이터들이 각자의 로컬에 DAG를 가지고 있고 이들이 서로 다 같은 형태가 아닌 경우들이 많기 때문이다(불샤크는 기본적으로 비동기식 DAG 방식이기 때문에). 그렇다면 불샤크는 어떻게 벨리데이터들이 전 순서에 도달할 수 있도록 할 수 있을까?
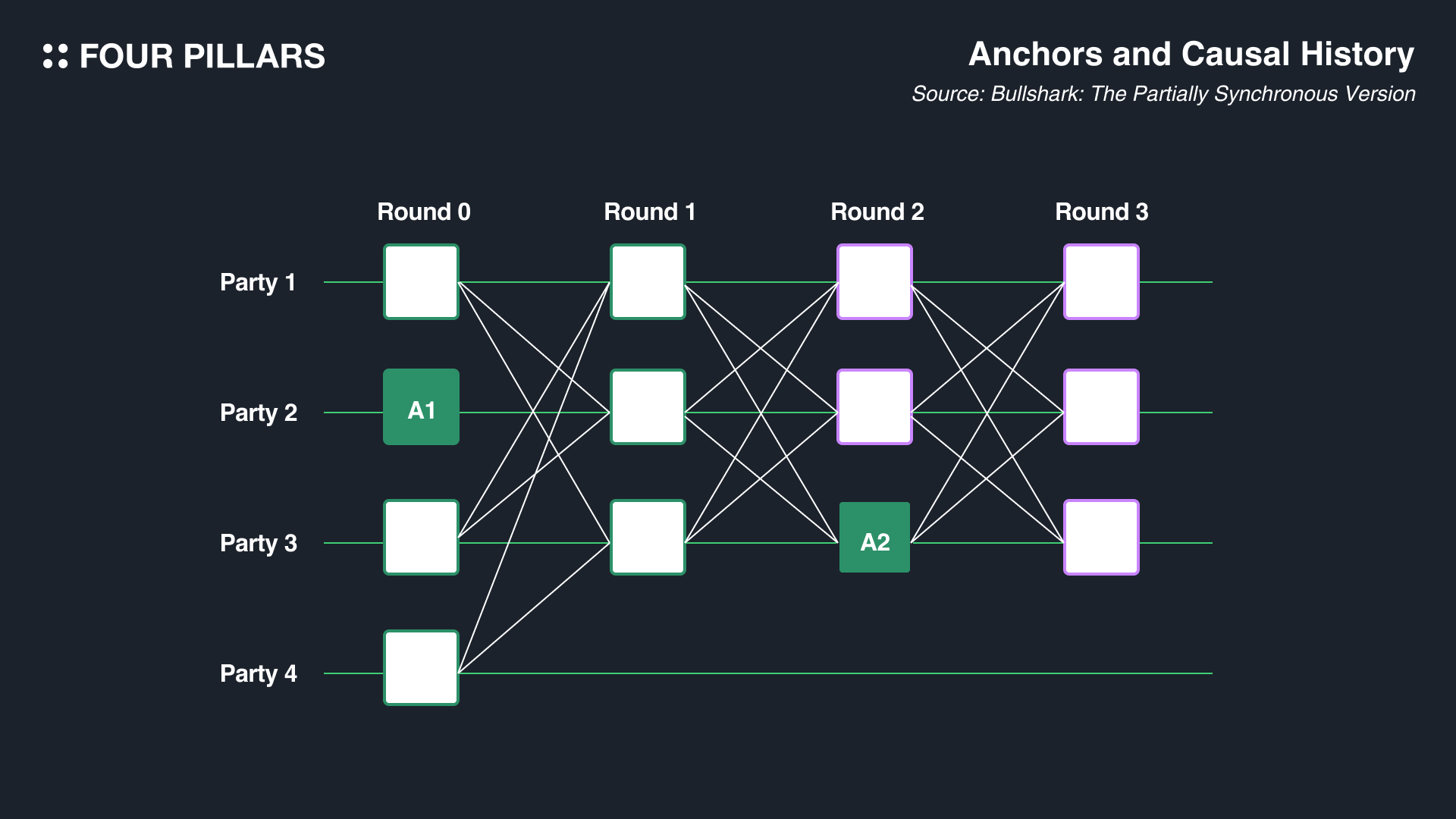
우선 불샤크는 라운드 기반의 DAG BFT이다. 그렇기 때문에 각각의 꼭짓점마다 라운드가 존재하고, 짝수 라운드마다 앵커라고 불리는 리더가 가지고 있는 꼭짓점이 존재한다. 그리고 홀수 라운드에선 짝수 라운드에 존재하는 앵커에 대한 투표를 진행하는 방식이다(즉 홀수는 앵커, 짝수는 앵커에 대한 투표라고 볼 수 있다). 위 그림에서는 앵커가 초록색으로 표시한 꼭짓점들이다(A1과 A2). 그리고 초록색 테두리로 칠해져있는 꼭짓점들은 앵커의 커주얼 오더를 이루는 꼭짓점들이라고 할 수 있다(A2앵커는 Round 1의 party 1, party 2, party 3의 꼭짓점을 참조하였다). 앵커는 말 그대로 리더의 꼭짓점이고, 앵커가 확정이 되기 위해서는 단순히 앵커 꼭짓점인 것으로는 안되고, 불샤크의 Commit Rule에 따라 그 다음 라운드로부터 최소 f+1의 투표를 받아야 한다(아까 나왈에서도 설명했듯 f는 악의적인 또는 잘못된 노드의 수를 의미한다).

위의 예시에서는 현재 4개의 노드가 참여중이니 N은 4이고 f가 1일일 때, 불샤크의 commit rule에 따라 앵커가 확정되려면 최소 f+1의 투표를 받으면 되니 2표를 받으면 해당 앵커는 확정된다. A2는 3개의 투표를 받았으므로 확정(확정 됐으므로 왕관을 수여한다!)되었고, A1의 경우 아직 1표를 받았으므로 확정은 나지 않은 상황이다. 그렇다면 A1을 배치시키지 말고 A2를 배치시켜야 하는 것일까? 정답은 아니다. 이다. 필자가 위에서도 언급했지만 불샤크는 기본적으로 비동기식 DAG 이기 때문에 다른 노드의 관점에선 A1에 대한 투표가 2개 이상 받았을 수도 있는 것이다. 그래서 당장 특정 노드의 관점에서 A1이 2표를 받지 못했더라도 우선은 A1을 A2이전에 배치는 시켜놓고 DAG를 진행하는 것이 옳을 것이다.
그렇다면 불샤크에선 모든 앵커들이 일단 존재하기만 한다면 배치를 시켜야 하는 것일까? 이것에 대한 정답도 아니다. 이다. 앵커가 우선적으로 배치되기 위해선 표를 받는지의 여부도 중요하지만, 최소한 다음 라운드의 앵커가 해당 앵커와 최소한 하나의 경로라도 연결이 되어있는지에 대한 여부가 더 중요하다. 만약에 위 그림에서 A2와 A1사이에 경로가 보장되어있지 않다면, A1은 스킵하고 넘어가도 되는 것이다.
정리하면, 불샤크는 라운드 기반의 DAG이며, 짝수 라운드에선 앵커 꼭짓점이, 홀수 라운드에선 해당 앵커에 대한 투표가 일어난다. 앵커가 DAG에 포함되려면 반드시 ‘확정’되어야 하며 확정의 기준은 홀수 라운드에서 진행하는 투표가 f+1개 이상 일어나야 한다. 하지만 지금 당장 f+1개의 투표를 받지 못한 앵커가 존재하더라도, 누군가의 관점에선 f+1개 이상의 투표를 받았을수도 있기 때문에 당장은 DAG에 배치시킨다. 하지만 만약에 앵커들과 아무런 연결점도 없는 앵커가 있다면, 그 앵커는 배제하는 식으로 DAG를 배치한다. 해서 결국 모든 선량한 벨리데이터들이 종국에는 같은 DAG 값을 가질 수 있도록 보장하는 것이다(이것을 reliable broadcast라고 한다).
지금까지는 불샤크가 어떻게 DAG의 라운드를 진행하는지를 알아보았다. 그렇다면 불샤크가 구체적으로 어떻게 확장성(scalability)을 확보할 수 있을까? 위에서 필자가 설명한 나왈(Narwhal)과 같이 불샤크는 데이터 전파와 DAG 진행을 분리해서 컨센서스 작업을 한다는 점에서 상당히 닮아있다(사실 불샤크 자체가 나왈의 오픈소스 코드베이스를 기반으로 디벨롭 되었다). 이게 무슨 말이냐 하면, DAG 구축은 구축대로 진행이 되고 데이터 전파는 네트워크의 속도에 맞게 진행된다. 이 과정에서 DAG 구축이 늦어진다고 하더라도 DAG의 각각 꼭짓점이 더 많은 메타데이터를 담는 형태로 라운드를 진행시켜서 DAG의 구축 속도가 늦더라도 네트워크 자체의 확장성은 지장이 가지 않는 방식으로 컨센서스 엔진을 설계하였다.
불샤크의 이러한 방식은 컨센서스 메커니즘의 확장성을 높혀주는데에 도움이 된다. 왜냐하면, 각각의 벨리데이터들이 전 순서에 도달하기 위해 서로간에 많은 커뮤니케이션을 하지 않아도 굉장히 효율적인 방식으로 벨리데이터들이 전 순서에 도달하여 서로의 합의를 할 수 있기 때문이다.
2.1.3 나왈 & 불샤크 진행 과정 정리
우리는 지금까지 나왈과 불샤크에 대해서 알아보았다. 정리하는 의미로 나왈과 불샤크를 사용했을 때 트랜잭션이 어떻게 시작되고 끝나는지에 대한 라이프 사이클을 순서대로 봐보도록 하자:
나왈의 워커들은 클라이언트로부터 트랜잭션 데이터를 받아온다. 그러면 워커들은 해당 트랜잭션을 묶고(batch)하고 해시화(hash)하여 전파한다.
해당 트랜잭션 묶음의 해시들은 나왈의 프라이머리에게 전파된다.
프라이머리는 해당 해시값을 블록에 담고 블록을 다른 프라이머리에게 전달한다.
프라이머리는 전달받은 블록을 확인하고 서명한다.
원래 처음 블록을 보낸 프라이머리가 2f+1개의 서명을 받았다면, 증명서를 발급한다.
해당 증명서가 2f+1개가 도착했다면, 다음 라운드를 진행한다.
컨센서스에서 트랜잭션 오더링이 진행된다. 만약 컨센서스 작업이 성공적으로 끝난다면, 트랜잭션 세틀먼트가 끝난 것이다.
트랜잭션 오더링이 끝났으면 해당 트랜잭션들은 벨리데이터들의 엑스큐션 할 수 있도록 포워딩 된다.
엑스큐션이 끝나면 벨리데이터들은 클라이언트들에게 엑스큐션 결과 메시지(execution result message)를 클라이언트에게 보낸다. 여기서 2f+1 개의 벨리데이터들이 해당 메시지를 보내면, 클라이언트들은 세틀먼트가 끝났다고 확인할 수 있다.
벨리데이터는 추가적으로 자신들이 연산한 것에 대해서 일종에 체크포인트를(자신들이 잘 했는지 검사하는 작업) 만드는데, 이 작업은 9에서의 작업과 동시에 이루어지고 보통 수이의 애플리케이션들은 벨리데이터들의 체크포인트까지 기다린다.
이러한 효율적인 컨센서스 방식(불샤크)과 멤풀 방식(나왈)을 통해서 수이는 약 125,000 TPS를 달성하기도 하였다(50개의 주체에게 약 2초의 레이턴시가 걸리긴 했지만).
2.1.4 불샤크로 만족못한다, 미스티세티(Mysticeti)의 등장

필자가 위에서 소개한 불샤크와 나왈의 결합은 수이 네트워크가 여태까지 수많은 트랜잭션을 효율적으로 처리할 수 있었던 가장 큰 이유였다. 하지만, 언제나 더 나은 대안이 나오기 마련이다. 현재 수이가 컨센서스 업그레이드를 앞두고 있는데, 바로 그 컨센서스 엔진의 이름이 미스티세티(Mysticeti)다. 미스티세티가 DAG 기반 컨센서스라는 것은 불샤크와 같다. 하지만 불샤크와 다른점이 몇 가지 존재하는데 오늘은 불샤크와의 차이점을 중심으로 미스티세티에 대한 소개를 해보려고 한다.
훨씬 더 짧아진 레이턴시
필자가 위에서도 잠깐 언급했지만 불샤크는 굉장히 빠른 컨센서스를 가지고 있음에도 불구하고 레이턴시가 꽤 있는 편에 속한다. 미스티세티 논문에서 나온바에 따르면 불샤크는 평균적으로 60-80k tps를 기록했지만 레이턴시가 8초에서 10초정도 발생하기도 하였다. 결국 확장성은 달성이 되었지만 레이턴시가 문제인 것이다. 어떻게 보면 미스티세티는 그러한 레이턴시를 줄이기 위한 시도라고 볼 수 있다. 실제로 미스티세티를 도입하면 50,000 tps를 달성함과 동시에 레이턴시가 0.5 초로 줄어드는 드라마틱한 개선이 이루어진다.
Certified Block이 아닌 Signed Block
필자가 위에서 설명한 불샤크나 다른 DAG의 경우 Certified Block(2f+1 개 이상의 벨리데이터들에게 서명을 받은 블록)을 통해서 컨센서스를 만드는 반면, Mysticeti는 signed block(단일 벨리데이터, 즉 해당 블록을 만든 벨리데이터로부터만 서명을 받은 블록) 을 통해서 컨센서스에 도달한다. 이게 가능한 이유는 Mysticeti에서는 Universal Commit Rule을 사용하기 때문이다. Universal Commit Rule은 간단하게 말해서 벨리데이터들이 블록에 하나하나 서명하지 않아도, signed block만으로도 네트워크가 블록체인에 커밋할지 아니면 스킵할지를 결정해서 블록들이 이전 DAG와 다르게 좀 더 빠르게 블록체인 네트워크에 커밋될 수 있도록 하였다. 이를 통해서 수이 네트워크는 기존 불샤크때 대비 레이턴시를 대폭 낮출 수 있는 것이다. 또한 이러한 효율화를 통해 연산에 필요한 CPU 사용도 최소화 할 수 있었다.
Implicit Certificate
이제 여기서 많은 사람들은 염려를 표할 수 있을 것이다. 여태까지 DAG 기반 컨센서스 모델이 Certified Block을 컨센서스에 사용한 이유가 분명히 있음에도 미스테세티는 Signed Block만을 이용해서 커밋 작업을 진행한다. Signed block을 사용해서 네트워크가 합의에 ‘안전하게’ 도달한다는 것은 결코 쉬운 일이 아니라고 생각한다. 물론 이를 통해 네트워크의 레이턴시는 낮아지겠으나, certified block에 비해서 signed block은 블록이 검증된 정도가 certified block보다 낮기 때문에 분명히 certified block을 사용해서 네트워크 합의에 도달하는 불샤크 보다 보안적인 측면에서의 염려점이 존재한다.
그러면 수이는 이 염려점을 그냥 알고서 미스티세티를 도입하는 것일까? 정답은 “아니다.”이다. 어떻게 signed block 만으로 보안적인 이슈 없이 안전하게 컨센서스에 도달할 수 있을까? 이를 이해하기 위해선 Implicit Certificate이라는 개념을 이해해야한다. Internal Certificate은 무엇이며 기존 불샤크때의 증명서와 다른건 무엇일까?
우선 불샤크에선 시스템 자체적으로 증명서가 존재하기 때문에 해당 증명서를 만들고 전파해야하는 반면, 미스티세티에선 컨센서스에서 정해놓은 벨리데이터 수 이상의 벨리데이터가 서명만 하면, 트랜잭션 자체가 "증명(certified)"되었다고 간주하고 컨센서스에 도달한다.
즉 미스티세티에선 굳이 모든 트랜잭션에 증명서가 없더라도 네트워크가 미리 정해놓은 숫자의 벨리데이터들에게 지지를 받았다면 블록이(해당 블록이 적어도 네트워크가 정해놓은 숫자의 벨리데이터들이 가지고 있는 이전 라운드의 블록들에 대한 레퍼런스만 가지고 있다면) 네트워크에 커밋이 될 수 있는 것이다. 로지컬 클락(Logical Clock)이 있기 때문에 블록들이 순서에 맞게 잘 커밋 되었는지 확인할 수 있고 이는 프로토콜의 신빙성(integrity)을 유지하는데에 큰 도움이 된다.
Wen Mysticeti
미스티세티는 아마 올해 상반기 중에 수이 컨센서스 엔진으로 업그레이드 될 예정이다. 과연 수이는 미스티세티 도입을 통해 안정성을 유지하면서도 레이턴시가 극단적으로 줄어든 네트워크를 구축할 수 있을지도 매우 큰 관심사가 될 것이다.
수이는 블록체인들 중에서도 굉장히 독특한 토크노믹스를 가진 블록체인으로도 유명하다. 수이의 토크노믹스에 대해서 자세히 알아보기 전에, 수이의 토크노믹스에서만 볼 수 있는 몇 가지 컨셉들을 짚고 넘어거자.
2.2.1 스토리지 펀드(Storage Fund)
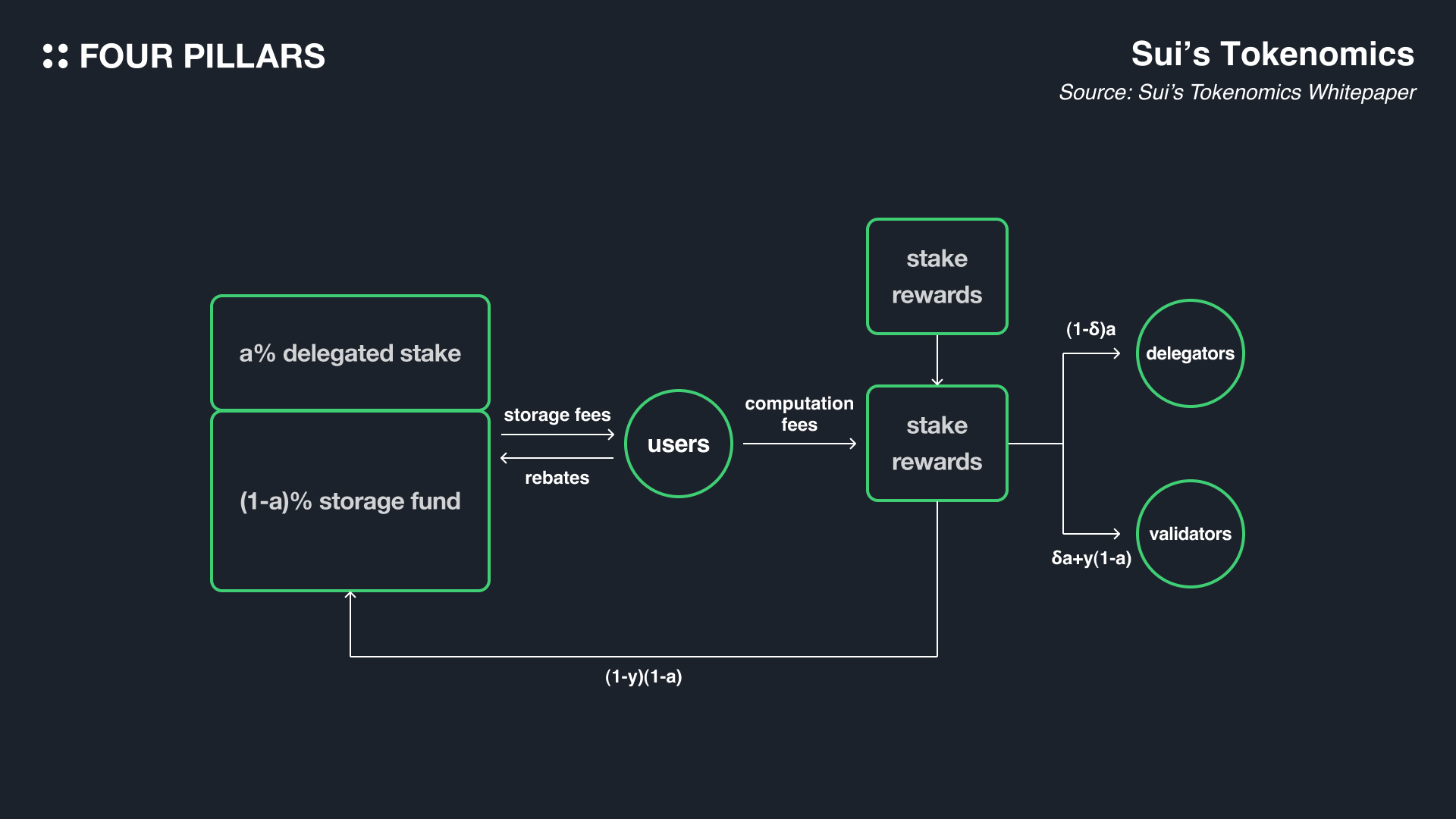
스토리지 펀드는 수이의 토크노믹스를 공부하면서 가장 신기하게 생각했던 피처인데, 어찌보면 앞으로 다른 레이어1 블록체인들도 참고해야할 수도 있는 모델이라고 생각된다. 우선, 블록체인은 시간이 지나면 노드들이 저장해야하는 스토리지의 용량이 매우 커지게 된다. 이는 너무 당연한 것인데, 제네시스 블록부터 현재의 블록까지 전부 다 가지고 있어야 하는 풀 노드의 입장에선 시간과 스토리지 용량은 비례할 수 밖에 없다. 결국 블록체인이 오랜 시간동안 잘 유지되기 위해선, 오랜 시간이 지났더라도 방대한 스토리지를 감당할 수 있는 경제적 인센티브가 있어야 한다. 해서 수이는 스토리지 펀드를 만들어서 나중에 네트워크에 참여하는 노드들이 있더라도 그 시점에 합당한 스토리지 보상을 해주는 것을 목표로 한다.

Soruce: Sui Document
그러면 스토리지 펀드에 있는 돈은 어디서 올까? 현재 수이에 트랜잭션 비용을 내고 있는 유저들이 내준다고 볼 수 있다. 유저들이 트랜잭션 비용을 지불할 때, 유저들은 트랜잭션 비용은 엑스큐션 비용과 스토리지 비용으로 나눠서 지불된다. 여기서 스토리지 비용은 스토리지 펀드로 보내진다. 또한, 스토리지 펀드에 있는 수이 토큰은 수이의 PoS 메커니즘이 전체 스테이킹량을 계산할 때 포함되고, 이에 비례해서 스테이킹 리워드도 받기 때문에 시간이 흐르면서 스토리지 펀드의 규모도 커진다(미래에 벨리데이터들에게 나눠주기 전 까지는). 이를 통해 지속 가능한 스토리지 관리가 가능해진다.
스토리지 펀드에 대해서 공부하면서, 유독 재미있던 기능은 “삭제 옵션(deletion option)”이다. 이것은, 유저가 특정 온 체인 데이터를 지우면, 원래 그 데이터를 만들기 위해서 소모했던 트랜잭션 수수료의 일정 부분을 스토리지 펀드에서 환불해주는 기능이다. 유저들에게 쓸모없는 데이터를 자발적으로 지우도록 인센티브를 설계했다는 점에서 매우 흥미로운 부분이라고 생각했다. 하지만 삭제 옵션이라고 해서, 블록체인의 핵심 가치를 위배하는 것은 절대 아니니 오해는 하지 마시라. 삭제 옵션은 과거 트랜잭션을 지우는 것이 아니라 더 이상 의미 없는 데이터들(NFT 메타 데이터나, 이미 교환을 해간 티켓들, 이미 종료된 경매 관련 데이터들)을 지울 수 있다는 의미이다. 즉, 블록체인의 핵심 가치인 불변성(immutability)은 삭제 옵션과는 무관하다.
2.2.2 트랜잭션 비용 산정 방식
수이 네트워크의 트랜잭션 비용은 어떻게 산정될까? 놀랍게도 “지속적으로 변한다.”라는 답변이 정답일 것이다. 실제로 에포크별로 수이 벨리데이터들이 일종에 서베이 같은 것을 한다. 서베이 중에 벨리데이터들은 자신들이 트랜잭션을 처리해줄 수 있는 최소값을 각자 정한다. 그리고 각자가 제출한 최소값에 대한 하위 66.67%에 해당하는 지점의 값을 참조하여 레퍼런스 비용으로 삼는다. 여기서 중요한 것은 단순히 하위 66.67%은 아니고, 벨리데이터에 스테이킹 된 수이 토큰의 수량에 가중치를 두어서 계산을 한다는 부분이다. 그럼에도 66.67%지점을 참고하는 이유는, 웬만한 벨리데이터들이 수용 가능한 가격을 기준으로 삼아야 하기 때문이다.
또 재미있는 것은 에포크가 끝날 때마다 벨리데이터들은 네트워크의 다른 벨리데이터들의 퍼포먼스에 대한 모니터링을 진행한다. 리스폰스 타임과 같은 다양한 메트릭스(맨 처음에 최소값을 제출할 때, 제출한 트랜잭션 최소값이 높거나, 트랜잭션 처리를 못했다면 보상을 적게 받고, 그 반대의 경우엔 보상을 높게 받는 식으로)를 보고 벨리데이터의 퍼포먼스를 체그한 뒤, 에포크가 끝날 때마다 다른 벨리데이터들의 퍼포먼스에 대한 자신들의 의견을 제출한다. 그리고 이러한 평가서는 스테이킹 리워드가 분배될 때 영향을 준다. 이러한 수이의 트랜잭션 비용 산정 방식은 굉장히 유저 친화적이라고 할 수 있다. 왜냐하면 벨리데이터들로 하여금 더 저렴한 트랜잭션 비용을 받게끔 유도하기 때문이다.

source: Sui
수이가 다른 블록체인들과 비교해서 독특한 점이 무엇인지에 대해서 탐구할 때, 프로그래밍 언어를 빼놓고 이야기 할 수 없다. 무브(Move)에 대한 이야기다. 실제로 수이는 무브 특히 Move on Sui를 독자적으로 가지고 있는 것으로 유명하고, 수의 코파운더이자 CTO인 Sam Blackshear는 해당 프로그래밍 언어(Move)를 메타에 있을 때 만든 것으로 유명하다. 무브언어는 블록체인을 위해서 만들어진 프로그래밍 언어라고 할 수 있고, 보안과 네트워크의 안정성에 포커스를 맞춘 프로그래밍 언어이다. 수이는 무브언어에도 변형을 두었기 때문에, Move on Sui(수이에서 사용되는 무브언어)에 대해서 다루기 전에 우선 무브 자체에 대해서 조금 살펴보고자 한다.
2.3.1 Resource oriented programming language
무브에서는 리소스(Resources)를 first class value(일급 객체란, 다른 객체들에게 적용 가능한 연산을 모두 지원하는 객체를 뜻한다. 프래그래밍 언어상에서 가장 높은 수준의 유연성을 갖춘다는 의미라고 받아들일 수 있다)로 여긴다. 즉 무브 언어에서 리소스는 다양한 형태로 저장될 수 있고 다양한 형태로 보내질 수 있지만, 특정 부분에선 굉장히 엄격한 룰을 부여하여 리소스가 복제되거나, 폐기되거나, 스토리지상에서 장소가 변경될수는 없도록 하였다. 즉, 안정성과 관련된 제약을 제외한다면 그 안에서는 얼마든지 자유롭게 사용될 수 있는 것이 리소스이다. 무브 언어에서 리소스의 예시로는 암호자산, 스마트 컨트랙트의 스테이트 값, NFT, 온체인에서 투표 권한 같은 것들이 있을 수 있다.(솔리디티에는 이러한 기능이 없다)
2.3.2 Data Abstraction
데이터 앱스트랙션이란, 쉽게 말하면 유저가 어떠한 것을 작동할 때 그 작동 원리를 이해하지 않아도 작동할 수 있도록 굳이 알지 않아도 되는 디테일한 내용들을 감추는 것을 이야기 한다. 그리고 무브 언어를 이야기 함에 있어서 데이터 앱스트랙션 부분을 빼놓고 이야기 할 수 없다. 무브에선 리소스들이나 다른 데이터 타입들이 모듈안에 들어가 있어서 해당 리소스들을 관리해야하는 복잡한 태스크들(어떤 방식으로 저장되어야 하는지, 수정되어야 하는지, 관리되어야 하는지등에 대한 일들)이 추상화 된다는 부분이 유저와 개발자의 관점에서 매우 장점이라고 할 수 있다.
데이터 앱스트랙션 때문에 또 가능한 것이 리소스에 대한 액세스 권한을 통제할 수 있다는 부분이다. 어떤 상황에서, 어떤 작업들이, 어떤 리소스에 허용되는지에 대해서 특정할 수 있다. 이러한 기능은 애플리케이션을 만드는 빌더 입장에서 굉장히 유용한 기능이라고 볼 수 있다. 보안적인 측면에서도 이러한 통제는 매우 유용하게 쓰일 수 있다.
2.3.3 Static Verification
Static Verification은 특정 코드가 프로그램에 의해서 실행되기 이전에 에러나 취약점을 미리 발견하는 것을 의미한다. 이게 가능한 이유는 무브 언어가 일단 표현식(expression)들이나, 함수(function)들, 변수(variable)들에게 각각의 타입을 정해주고 각각의 타입들마다 이들이 어떻게 사용되고 결합될 수 있는지에 대한 명확한 룰을 줄 수 있기 때문이다.
또한 borrow checker 라는 것을 도입하여 데이터가 의도하지 않은 방식대로 변질되었는지 확인하거나 데이터를 가르키는 레퍼런스들이 데이터보다 오래 남아있는 것을 방지할 수 있다.
마지막으로 formal verification을 통해서 컨트랙트들의 로직을 검증할 수 있다는 것도 큰 장점이라고 할 수 있다.
2.4.4 Move on Sui: what are the differences?
무브는 그 자체로 굉장히 장점이 많은 프로그래밍 언어이지만, 오리지널 무브는 어카운트 기반의 모델을 가지고 있어서 수이 팀 입장에선 한계점이 많다고 느꼈다고 한다. 오리지널 무브는 애초에 허가형 블록체인인 디엠을 위해서 설계되었기 때문에, 비허가형 블록체인(permissionless blockchain)인 수이를 위해서는 이에 맞게 재설계 해야한다고 생각했고, 그래서 나온 것이 Move on Sui이다. Move on Sui는 오리지널 무브와 다른 점이 몇 개 있는데 이는 아래와 같다:
오브젝트 기반(object oriented) 모델
글로벌 스토리지에 주소나 타입의 이름등으로 저장이 되었던 오리지널 무브와 다르게 Move on Sui는 오브젝트의 ID로 저장이 된다. Move on Sui 에서 각각의 오브젝트들은 고유의 ID를 부여받고 이것은 블록체인 주소들과는 독립적이다. 예를 들어서 “CoolAsset”이라는 오브젝트가 있다면, 이 오브젝트는 “AssetID123”이라는 고유의 ID가 있고 해당 ID가 글로벌 스토리지에 저장되어서 해당 오브젝트를 레퍼런스하는 구조이다. 어떤 사람이나 주소가 해당 오브젝트를 소유했던지간에 말이다. 글로벌 스토리지에 저장되는 것이 해당 자산을 가지고 있는 오너와 상관없는 오브젝트의 ID이기 때문에 개발자들이 자산을 옮기는 로직을 짤 때 복잡하게 짜지 않아도 된다는 장점이 있다.
트랜잭션 병렬처리(Transaction Parallelization)
원래 오리지널 무브에서는 트랜잭션 병렬처리가 기본값이 될 수 없다. 이것도 오리지널 무브가 위에서 언급했듯 어카운트 기반의 모델을 가지고 있기 때문이다(어카운트 기반 모델에서는 트랜잭션이 스테이트 값을 변경할 때 그 스테이트 값들이 어카운트 밸런스와 같은 어카운트와 관련된 데이터와 밀접하게 연관되어있기 때문에 문제를 일으킬 가능성이 높다). 하지만 오브젝트 기반 모델을 가지고 있는 Move on Sui의 경우 각각의 오브젝트들이 독립적으로 영향을 받기 때문에 하나의 오브젝트에서의 변화가 다른 오브젝트에 영향을 끼치지 않는다. 예를 들어서 각각 다른 오브젝트들을 변경하려는 두 트랜잭션이 있다고 했을 때, 이 트랜잭션들은 각각 다른 오브젝트에게 영향을 주는 트랜잭션이기 때문에 병렬로 처리되어도 문제가 없을 것이다.
지금까지는 수이의 디자인적, 구조적 차별점들에 대해서 알아보았다. 하지만 진짜로 유저들이 체감하는 차별점은 필자가 이번에 다룰 피처들에 있다. 만약에 수이가 자체적으로 소셜 로그인을 지원하는데 그 로그인 방식이 자가수탁형(self-custodial)이라면 어떨까? 또, 자산을 QR 코드, 또는 링크를 통해서 사람들에게 보낼 수 있다면 어떨까? 마지막으로 수이 토큰이 없는 유저에게 트랜잭션을 스폰서 해주는 것이 기본적으로 내장되어있다면 어떨까? 놀랍게도 수이는 이 세 가지 기능 모두를 가지고 있다. 이 기능들을 하나하나 살펴보면서, 왜 수이가 다른 레이어1들과 기능적으로 차별화 되는지를 알아보자.

zkLogin은 간단하게 말해서 사람들이 웹2 서비스에 로그인을 하거나 가입을 하는 프로세스와 거의 동일한 수준의 UI를 제공해주는 온보딩 프레임워크이다. 다만, 기존 웹2에선 데이터를 써드파티가 맡아주는 형태였다면, zkLogin은 데이터를 유저가 온전히 소유하는 형태라는 부분이 다르다. 수이는 어떻게 편의성과 데이터 자가수탁(Self Custodial)을 가능하게 했을까? 우선 zkLogin의 방법에 대해 이해하기 위해서는 OAuth 2.0과 Zero Knowledge Proofs에 대한 이해가 선제적으로 필요하기 때문에 이 둘에 대해 간단하게 알아보자.
3.1.1 OAuth 2.0
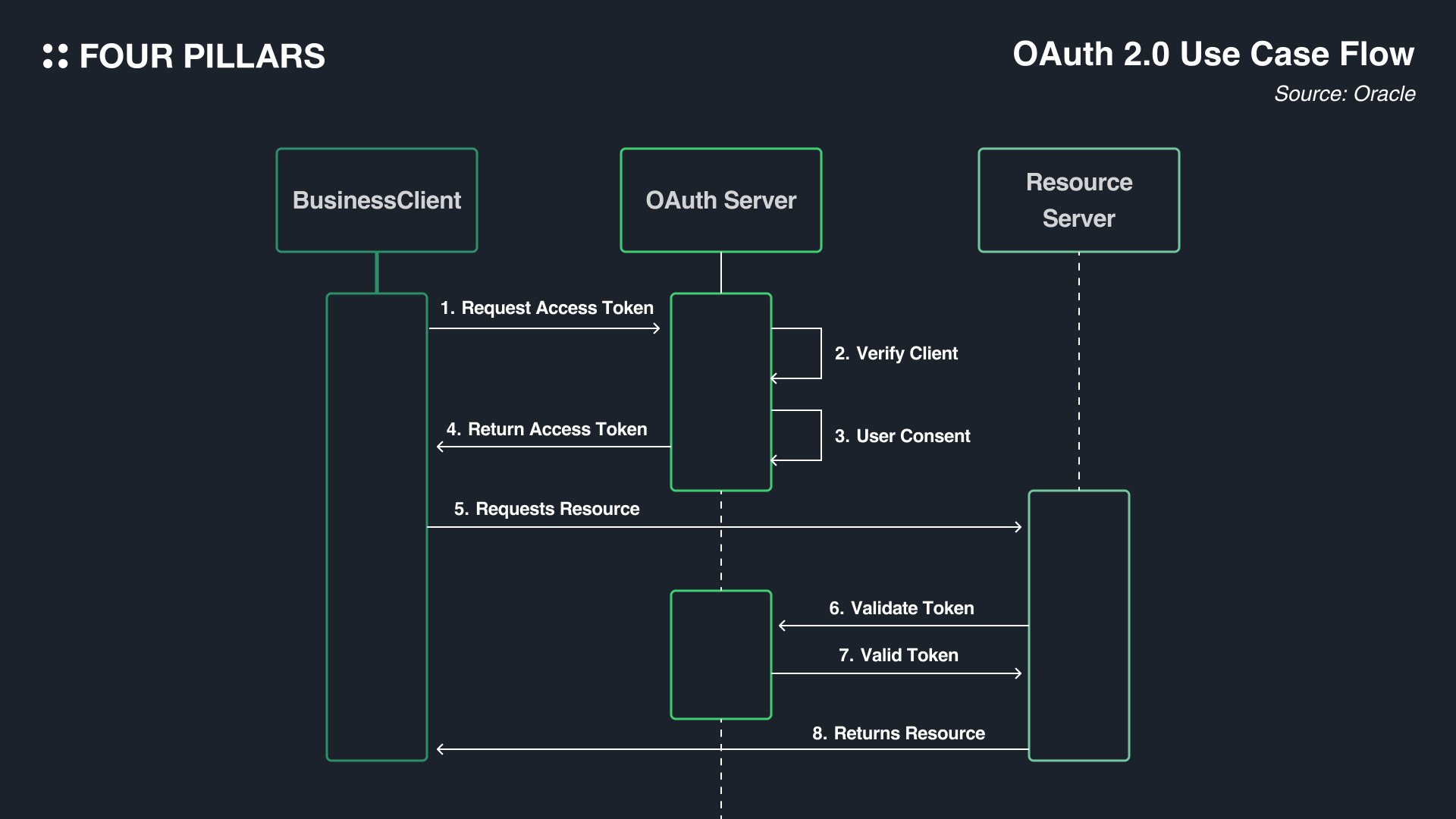
많은 분들은 생소한 단어겠지만, 이 글을 보시는 분들이라면 포필러스 웹사이트에 로그인을 하실 때도 OAuth 2.0 방식을 사용하셨을 것이다. OAuth 2.0은 Open Authorization 2.0의 약자로 신원 인증을 위한 개방형 표준 프로토콜이다. 간단하게 말해서 리소스를 소유한 사람들(유저들)을 대신해서 리소스에 대한 접근 권한을 써드파티에 위임할 수 있도록 해주는 프로토콜이라고 볼 수 있다. 우리가 현재 이용하는 간편 로그인 기능들은 거의 대부분 OAuth 2.0 프로토콜을 기반으로 만들어졌다고 해도 과언이 아니다. OAuth에 참여하는 참여자는 아래와 같다:
Resource Server: 리소스를 보유하고 있는 서버라고 볼 수 있다. Facebook, Google, Twitter와 같이 우리가 간편 로그인을 할 때 이용하는 업체들이 주로 Resource Server에 속한다.
Resource Owner: 자원의 소유자로서, 실제로 서비스를 이용하는 유저라고 볼 수 있다.
Authorization Server: 리소스에 대한 접근 권한 등을 관리하는 서버이다. Access Token을 만들어주는 서버이기도 하다.
Business Client: Resource Server에 접속해서 정보를 가져오고자 하는 주체이다. 포필러스도 Client라고 볼 수 있다.
위의 그림을 좀 더 설명하자면. 클라이언트는 약 세 번의 과정을 거쳐서 리소스를 받아간다: 우선 Resource Owner(유저)에게 인증 승인을 받아야 하고, 해당 승인을 Authorization Server에 주면 해당 서버는 Access Token을 준다. 그리고 그 Access Token을 Resource Server에 주어야 서버로부터 리소스를 얻어가는 방식이다.
수이의 zkLogin 역시 ‘간편 로그인’이 핵심 기능중에 하나이므로 OAuth 2.0 을 이용한다. 즉, OAuth 2.0 호환이 가능한 Resource Server는 전부 zkLogin 지원이 가능하다.
3.1.2 Zero Knowledge Proofs
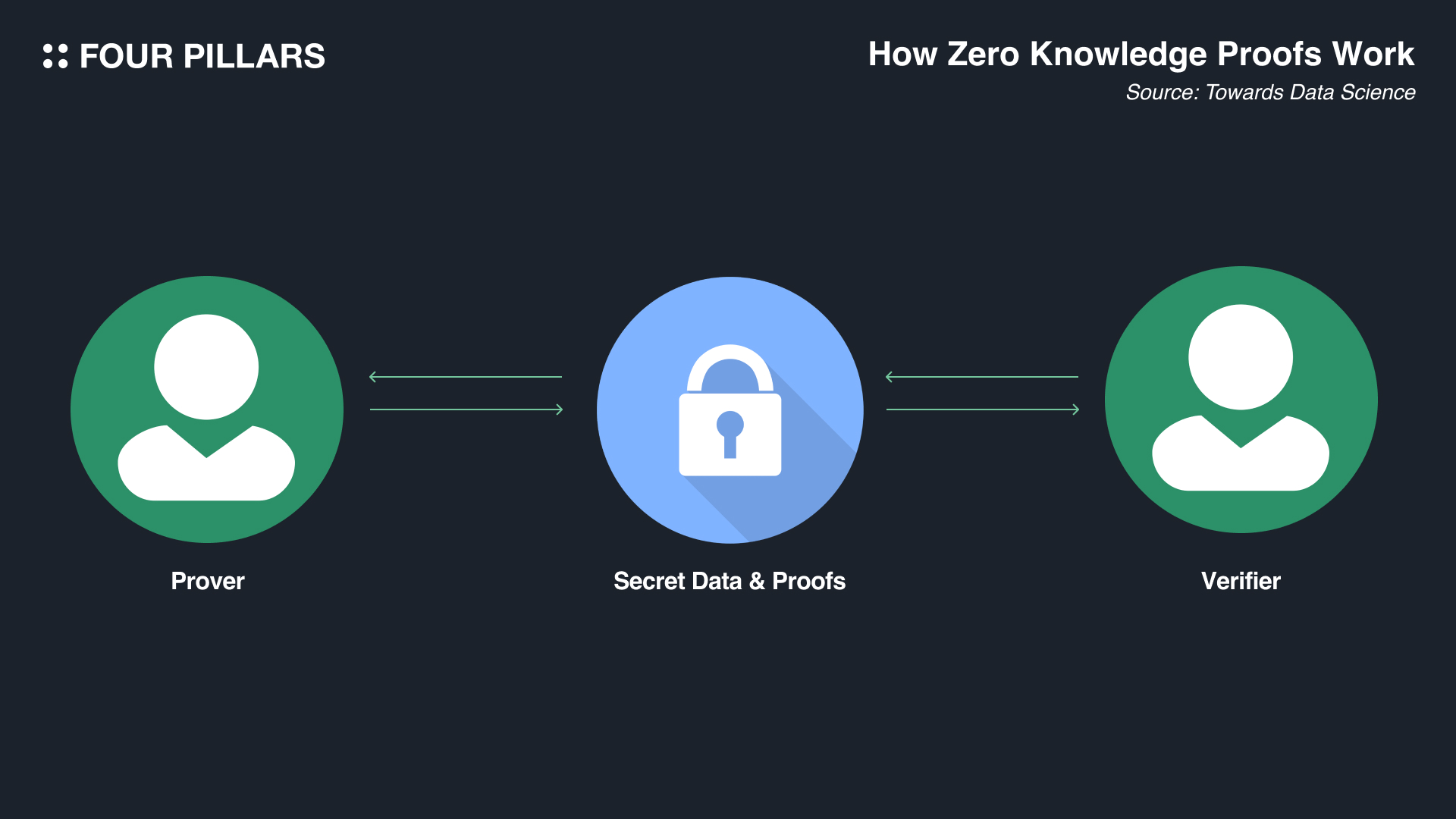
하지만 zkLogin이 단순히 OAuth 2.0만 사용했다면 앞에 zk라는 글자를 붙히지 않았을 것이다. 수이의 zkLogin이 기존 간편 로그인 기능들과 다른 점이 바로 영지식 증명(Zero Knowledge Proofs)을 이용했다는 부분일 것이다. 영지식 증명(ZKP)은 증명자가 정보 자체를 공개하지 않고도 검증자에게 특정 정보에 대한 지식이 있다는 것을 증명할 수 있는 암호화 프로토콜이다. 즉, ZKP를 사용하면 자신이 알고 있는 정보를 실제로 공개하지 않고도 자신이 무언가를 알고 있음을 증명할 수 있다.
ZKP는 정보 자체를 공개하지 않고도 증명자가 검증자에게 특정 정보에 대한 지식이 있음을 증명할 수 있도록 하는 방식으로 작동하기 때문에 인증, 신원 확인, 개인정보 보호등 다양한 애플리케이션에서 사용될 수 있고, 수이의 zkLogin은 ZKP를 활용한 애플리케이션 사례로 매우 적합하다고 볼 수 있다. 왜냐하면 zkLogin이 ZKP를 사용하여 써드 파티들이 수이 주소와 해당 OAuth 식별자에 연결되는 것을 방지하여 매우 간편한 로그인 방식을 제공하면서도 데이터를 온전히 유저들의 소유(영지식 증명 기술을 통해서 구글 페이스북과 같은 정보 제공자들도 자신들이 제공하는 정보와 특정 수이 주소가 연결되어있다는 것을 알 수 없다)로 만들어주기 때문이다.
3.1.3 How Does zkLogin Work?
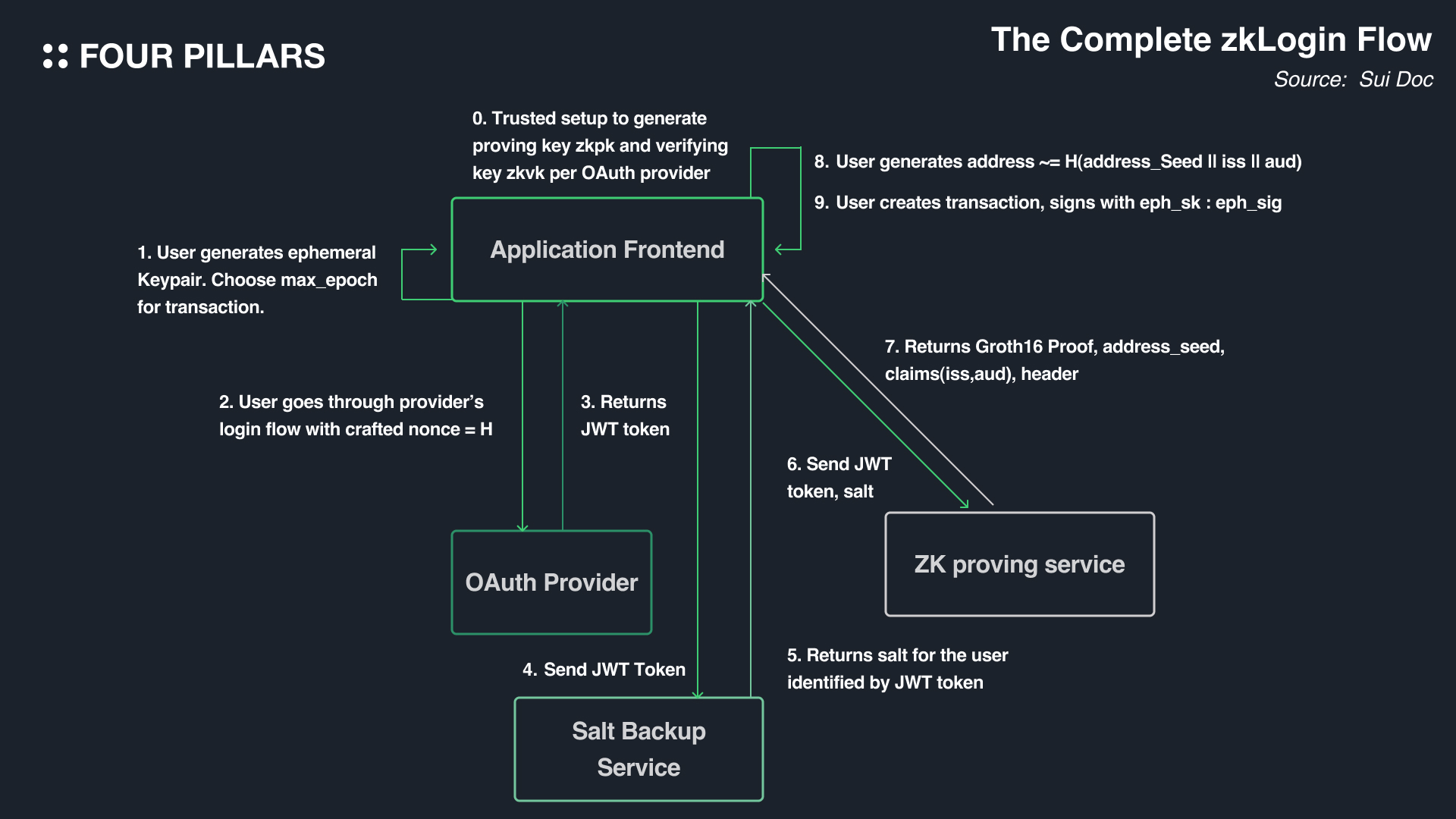
우선 zkLogin 을 이해하기 위해서 알아야 하는 단어들이 몇 개 있다:
JWT Token: JWT Token은 JSON Web Token의 약자로 헤더(header), 페이로드(payload), 서명(signature) 로 구분되어 있고 클라이언트와 서버 사이에서 통신할 때 권한을 주기 위해 사용하는 토큰이라고 볼 수 있다.
Salt(솔트): 솔트값은 데이터, 비밀번호, 통과암호를 해시 처리하는 단방향 함수에 임의의 문자열을 덧붙이는 것을 말한다. 누군가 같은 비밀번호를 사용하더라도 솔트값이 적용된 문자열이 다르기 때문에 보통 스토리지에서 비밀번호를 보호하기 위해 사용된다.
OpenID Provider(OP): 이들은 OAuth 2.0에서 Resource Server의 역할을 맡는 주체들이라고 볼 수 있다. 현재까지 zkLogin을 지원하는 제공자들은 페이스북, 구글, 트위치, 슬랙, 애플이 있다.
Application Frontend: zkLogin을 지원하는 애플리케이션이나, 지갑과 같은 서비스를 이야기 한다.
Salt Backup Serivce: 백엔드 서비스로, 솔트값을 유저들에게 돌려주는 역할을 한다.
ZK Proving Service: JWT 토큰과, JWT 랜덤값, 유저 솔트값, max-epoch를 기반으로 ZKP를 만드는 역할을 한다. ZK Proof를 생성하는 것은 굉장히 많은 리소스가 드는 작업이기 때문에 직접 ZK Proof를 생성할 수도 있지만, 미스텐 랩스가 ZK Proof를 대신 만들어주기도 한다.
eph_sk. eph_pk: 이들은 임시적으로 서명을 생성하기 위해 필요한 KeyPair(Private Key와 Public Key의 쌍)를 의미한다. 서명 매커니즘은 통상적인 트랜잭션 서명 매커니즘과 동일하지만, OAuth 의 세션이 끝나면 만료되기 때문에 일시적이다.
zkLogin이 이러한 임시 KeyPair를 만든 이유는, 유저들이 키를 잃어버려도 언제든지 새로운 임시 키를 만들 수 있게해서 자산을 지킬 수 있도록 하기 위함이다.
iss(issuer): 발급자라는 의미로 JWT 토큰을 발행한 주체를 식별하는 문자열이다.
aud(audience): JWT 토큰을 전달받는 주체를 식별하는 문자열이다.
sub(subject): JWT 의 대상인 유저를 식별하는 문자열이다.
핵심 단어들에 대한 이해가 끝났다면, 다음은 zkLogin의 과정에 대해서 알아보자. 어떻게 유저들은 zkLogin을 통해 수이 블록체인에 접근이 가능할까?
우선 사용자들은 OP(OpenID Provider)에 로그인 함으로써 논스값이 담긴 JWT 토큰을 얻는다. 특히 사용자는 여기서 일시적인 KeyPair(eph_sk. eph_pk)를 생성한 다음 KeyPair에서 퍼블릭 키를 만료 시간(expiray times) 및 Jwt_randomness와 함께 논스에 입력한다. 사용자가 OAuth 로그인을 끝내면 애플리케이션의 리디랙션 링크에 JWT토큰을 찾을 수 있게 된다.
그 다음은 Application Frontend에서 JWT 토큰을 Salt Backup Service로 보낸다. 그러면 Salt Service는 JWT 토큰의 유효성을 검사한 뒤, iss(JWT발행 주체를 나타내는 문자), aud (애플리케이션을 나타내는 문자), sub(유저를 나타내는 문자)를 기반으로 유저의 고유한 솔트값과 JWT 토큰을 다시 Application Frontend 로 보낸다.
유저는 JWT 토큰, 솔트값, 임시 퍼블릭 키, jwt randomness, 문자열들(iss, aud, sub)을 ZK Proving Service로 보내면, ZK Proving Service는 해당 정보를 바탕으로 ZKP를 생성하게 된다.
애플리케이션은 문자열들을 바탕으로 유저의 주소를 연산한다(JWT 토큰만 유효하다면 이 작업은 독립적으로 이루어질 수 있다).
임시 프라이빗 키를 사용해서 임시 서명(emphemeral)을 하는 것으로 트랜잭션이 서명된다.
마침내 유저는 임시 서명과, ZKP, 그리고 다른 인풋값을 수이에 제출한다.
여기서 반드시 짚고 넘어가야하는 부분이 있는데, 바로 zkLogin은 각각의 애플리케이션, 그리고 zkLogin 호환 월렛마다 별도의 OAuth credential을 만든다는 부분이다. 쉽게 말하면, 여러분이 zkLogin으로 수이 블록체인에 온보딩하여 특정 애플리케이션을 사용한다고 했을 때, 애플리케이션마다 별도의 주소와 어카운트가 부여된다(여기서 애플리케이션은 단지 DeFi, Game등에만 국한된 것이 아니라 월렛들도 포함이다. 즉 같은 구글 계정으로 다른 지갑에 로그인 하더라도 다른 어카운트가 배정이 된다). 이렇게 하는 이유는 각각의 앱별로 독립적인 UX를 제공해주기 위해서라고 볼 수 있다. 이해를 돕기위해서 예시를 들어보자:
steve@4pillars.io + Sui Wallet = account 1
steve@4pillars.io + different sui wallet but zkLogin compatible = account 2
steve@4pillars.io + game or DeFi app = account 3
그렇다면 만약 steve@4pillars.io 라는 구글 계정을 활용해서 zkLogin을 하고 수이 월렛을 이용해서 게임이나 디파이를 사용하는 경우엔 사용하는 게임과 디파이마다 어카운트가 다르게 배정될까? 정답은 “아니다”이다. 필자가 방금 설명했던 것처럼 이 맥락에서는 월렛도 애플리케이션의 일종이기 때문에 여러분이 zkLogin으로 수이 월렛에 로그인 해서 다양한 수이의 애플리케이션들을 사용하신다면, 이미 수이 월렛 자체가 애플리케이션이기 때문에 이에 할당된 하나의 OAuth credential에 해당되는 것이다. 만약 다른 월렛을 거치지 않고 게임이나 디파이에 바로 접근했다면, 그 경우엔 애플리케이션마다 별도의 어카운트가 배정되는 것은 맞다.
지금 이 글을 읽고계신 분들은 zkLogin이 너무 복잡한 기능이라고 생각하실 수 있지만, 당연히 필자가 위에서 명시한 과정들은 유저딴에선 전부 생략되고 애플리케이션들이 감당하기 때문에 걱정하지 않아도 된다. 필자가 zkLogin의 과정을 설명한 이유는, zkLogin이 얼마나 안전하게 유저들의 데이터를 보호하고 어떻게 비수탁형으로 쉽게 수이 네트워크에 온보딩 될 수 있는지를 설명하고 싶어서였다. 블록체인에서 가장 중요한 기능인 월렛에 대한 이야기이니 만큼 자세한 설명이 있어야 사람들도 안심하고 쓸 수 있기 때문이다.
3.1.4 zkLogin이 다른 소셜 로그인과 다른 점
우선 다른 소셜 로그인들(웹2의 인증 정보들을 웹3로 가져오는 것)도 얼핏 보면 zkLogin과 비슷한 기능을 하고 있는 거 같지만 이들은 1)써드 파티에 의존한다는 점(웹2 신원 인증을 할 때나, 프라이빗 키를 운영할 때) 2) JWT 토큰을 증명할 때 스마트 컨트랙트에 의존해서 개인정보를 공개해야 하거나, 굉장히 비싼 온체인 ZKP 검증을 해야한다는 부분에서 zkLogin과 다르다고 볼 수 있다.
zkLogin은, Sui 네티이브 하기 때문에 zkLogin으로 만들어진 트랜잭션들은 수이 블록체인의 다른 트랜잭션들(뒤에서 후술할 Sponsored Transaction과 같은)과 쉽게 호환이 된다.
또한 임시 퍼블릭 키(ephemeral key)를 사용하기 때문에 써드 파티가 지속적으로 프라이빗 키를 관리하지 않아도 된다(해당 키는 만료 기간이 지날 때 까지만 사용되고, 해당 ZKP도 키가 만료되면 같이 만료된다). 마지막으로 ZKP와 임시 서명(ephemeral signature)만 온 체인에 제출하면 되기 때문에 다른 정보들을 공개하지 않아도 된다는 점에서 기존 소셜 로그인과는 확실한 차이점을 보인다. zkLogin에 대한 더 자세한 설명은 포필러스가 일전에 작성한 zkLogin에 대한 글을 참고하시길 바란다.
source: Mysten Labs Blog
zkSend는 간단하게 수이를 보낼 수 있는 기술이다. 원래 토큰을 누군가에게 보내려면 1) 토큰 수량을 정하고 2) 받는 사람의 주소를 적는 과정을 거쳐야 한다. 하지만 아무리 도메인을 쓴다고 하더라도 상대방의 주소를 하나하나 외우거나 가지고 다니는 것은 매우 불편한 일이다. 만약에 도메인이나 주소를 잘못 입력한다면, 영구적으로 자산을 잃어버릴 위험도 있다. 만약에, 받는 사람의 주소를 적는 과정 없이도 누군가에게 자산을 보낼 수 있다면 얼마나 좋을까?
zkSend가 바로 그것이다. 자산을 보내는 사람은 보낼 자산의 수량만 입력하고 링크를 만들거나 QR코드를 만들어서 상대방에게 보내기만 한다면, 그것을 받은 상대방은 필자가 위에서 설명한 zkLogin을 통해 간편하게 로그인 후, 자산을 받기만 하면 된다.
3.2.1 zkLogin + zkSend = UI/UX on another level
필자가 위에서 설명한 zkLogin과 zkSend를 잘 결합해보면, “수이 월렛을 가지고 있지 않은 사람도 단 10초만에 지갑을 만들고 QR이나 링크를 통해서 수이를 수령할 수 있는” 경험을 할 수 있다. 우선 zkSend로 링크나 QR을 받으면 zkLogin을 통해 구글이나 트위치 계정으로 수이 지갑을 바로 생성한다, 그 후에 바로 수이 토큰을 수령한다. 지갑도 없는 사람이 지갑을 만들고 수이를 중앙 거래소가 아닌 자가 수탁형 지갑에서 수령할 수 있는 경험을 단 10초만에 할 수 있다는 것이 믿어지는가? 수이는 현재 이 모든 기능을 구현해놓은 상태이다. 애플리케이션 빌더의 입장에선 여러 방면으로 유용하게 쓰일 수 있는 인프라라고 생각되고, 필자가 현재 수이에 대한 관심을 갖고 아티클을 작성하게 된 가장 큰 이유가 zkLogin과 zkSend라는 혁신 때문이라고 봐도 과언이 아니다. zkSend를 해보고 싶으신 분들은 이 링크를 통해 직접 수이 토큰을 보내보는 경험과 받는 경험을 해보시기 바란다.

Source: Sui Blog
여태까지 우리는 수이의 zkLogin과 zkSend 대해서 알아보았다. zkLogin와 zkSend로 기존 블록체인 지갑이 주는 불편함은 해소할 수 있을 거 같은데, 필자가 언급했던 불편함은 지갑에만 있는 것이 아니었다. 오히려 어쩌면 지갑보다 더 불편한 것이 트랜잭션 수수료일 것이다. 수이는 트랜잭션 수수료의 복잡성 문제를 어떻게 해결하려고 할까?
사실 어떠한 것이 문제라면, 그 문제의 원인을 없애는 것이 가장 현명한 문제 해결 방법이다. 블록체인에서 트랜잭션 수수료를 지급하는 것이 UI적으로 문제라면, 트랜잭션 수수료를 지불하지 않고도 트랜잭션을 발생시킬 수 있으면 되지 않을까? 그래서 등장한 것이 바로 Sponsored Transactions이다. Sui의 프로그래밍 언어인 Move에는 애플리케이션 빌더들이, 애플리케이션에서 발생하는 트랜잭션의 수수료 일부 또는 전부에 대해 대납할 수 있는 기능이 있다. Sponsored Transaction은 아래와 같은 경우에 사용할 수 있다:
유저가 실행한 트랜잭션에 대한 대납을 할 때.
유저가 GasLessTransactionData Object를 만들면 빌더에게 승인을 받기 위해서 보내진다. 그러면 빌더는 TransactionData Object를 트랜잭션 수수료와 함께 만들고 서명하면, 유저도 해당 Object에 서명하고 트랜잭션은 처리된다.
빌더가 직접 유저에게 트랜잭션 수수료를 전달할 때.
이 경우는 빌더가 TransactionData Object(이미 트랜잭션이 미리 허용(Pre-authorized)된 경우고, 트랜잭션 비용도 지불이 된다)를 만들어서 이메일이나 다른 메시징 프로토콜로 유저들에게 직접 전달해서 유저들이 해당 트랜잭션을 발생시킬 수 있도록 한다.
보통 이런 형태의 트랜잭션은 광고나, 새로운 유저들을 온보딩 시킬 때 매우 유용하게 쓰일 수 있다.
이러한 유형의 트랜잭션이 재미있는 것은, 수이 토큰이 없는 유저나 아예 블록체인을 사용해보지 않은 유저도 zkLogin과 함께 트랜잭션을 발생시키게 해서 웹3에 대한 경험을 시킬 수 있다는 부분에 있다.
빌더가 GasData 를 만들어서 유저에게 전달할 때
GasData는 일종에 백지수표와 같다. GasData(트랜잭션 비용 예산을 정의해둔다)를 전달받은 유저는 트랜잭션 비용이 얼마인지 알 필요 없이 트랜잭션을 실행하기만 하면, 빌더가 서명하고 트랜잭션이 처리된다.
이런식으로 수이는 유저의 입장에서 트랜잭션 비용을 알지 않아도 블록체인에서 트랜잭션을 발생시킬 수 있는 구조를 만들어놨다. 이러한 피처들이 좀 더 상용화 된다면 많은 유저들이 블록체인을 활용하는지도 모른채 웹3 서비스를 이용할 수 있는 순간도 찾아올 것이다. 필자가 방금 설명한 세 가지 기능을 전부 다 활용한다면 유저들은 1) 지갑을 만들 필요도 없고 2)자산을 전송받아야 하는 대상의 주소도 모른채로 자산을 전송할 수 있는데다가 3) 이 모든 것을 함에 있어서 드는 트랜잭션 비용을 지원 받을 수 있다는 것이다. 이 피처들이야말로 애플리케이션 빌더들이 바라던 인프라가 아닐까?
우리는 지금까지 수이에 대해서 알아보았다. 필자는 다양한 블록체인들에 대한 조사를 하고 공부를 하지만, 수이 블록체인 만큼 다양한 논문들을 참조하여서 글을 작성하는 경우는 매우 드물다. 그만큼 수이 블록체인이 굉장히 기술 집약적이고, 새로운 기술들을 많이 도입했다는 의미이기도 하다. 필자가 해당 아티클 초반부에 언급했듯, 이제 새로운 레이어1을 만들기 위해서는 정말로 새로워야한다. 기존에 있는 체인들을 포크해서 새로운 내러티브를 입히는 정도로는 시장에서 경쟁력이 없을지도 모르겠다. 그런면에서 수이는 정말 다양한 분야에서 새로운 시도를 하고있고, 발전을 거듭하고 있다. 이게 비단 컨센서스 디자인이나 아키텍처적인 측면이 아니라, 유저들의 인터페이스를 개선하고 개발자 친화적인 환경을 조성하기 위해서 끊임없이 다양한 피처들과 기술들을 개발하고 소개하고 있다는 점에서 앞으로 수이가 만들어갈 블록체인 기술에 지속적으로 관심을 가질 수 밖에 없다.
특히 zkLogin과 zkSend 와 같은 기술들은, 블록체인 업계에 오랜 시간동안 리서치를 해왔던 필자의 입장에서도 굉장히 충격적인 기술들이었다. 수이의 이러한 기능들은 우리가 블록체인 대중화에 대해서 논함에 있어서 매우 중요한 메시지를 던져준다고 생각한다. 정말로 대중들이 블록체인을 사용하기 위해서는 단순히 블록체인이 빠르고 수수료가 저렴한 것을 넘어서서 월렛이나, 자산을 옮기는 방식, 그리고 트랜잭션 비용의 간소화와 같은 다양한 부분에서의 혁신도 필요하다는 메시지가 바로 그것이다.
아마 수이에 대한 리서치는 앞으로도 포필러스에서 자주 다룰 거 같다. 왜냐하면 필자가 해당 아티클을 작성하고 있는 순간에도 수이 팀은 인터넷 없이 트랜잭션을 보내는등의 정말로 엄청난 시도들을 하고 있기 때문이고, 필자는 리서처로써 또 저러한 시도들이 어떻게 이루어졌는지를 다루어야하는 사명을 가지고 있기 때문이다. 다음번엔 수이가 또 어떠한 기능들을 가지고 나오게 될까? 우리 모두 함께 수이에 관심을 가지고 지켜보도록하자.
이 글의 비주얼을 제공해주신 Kate에게 감사의 말씀을 전합니다.