The reason AI has yet to achieve true personalization or scalable progress stems from a range of structural constraints—spanning technology, data, ethics, and cost. Overcoming these limitations requires a fundamentally new approach, distinct from the centralized architectures that have defined AI development to date.
Gradient is redesigning each component required for AI inference and training—data, compute, and communication—as decentralized layers and integrating them into a unified stack. Through this, the team is building a scalable, open AI intelligence full-stack that anyone can participate in, verify, and collaboratively operate.
Gradient holds clear potential to become a scalable open intelligence infrastructure optimized for the diverse contexts of a pluralistic society. However, securing meaningful market advantage will require aligning incentives across participants at multiple layers and generating strong network effects that combine seamless module-level interoperability with real market efficiency in a highly competitive landscape.
“How can we deliver the value of our product or service to more customers, consistently, and in a way that provides them with the greatest utility?”
This is a fundamental question that every business, regardless of industry, must inevitably face. Yet value is inherently relative — it is interpreted differently by each person, culture, and era. Every product or service is created with a clear intention, but that intention is rarely conveyed uniformly to all customers. At times, the original philosophy or purpose behind it can even become distorted along the way.
For this reason, global companies invest heavily in localization. In order to maintain consistent quality and brand experience across diverse audiences, they adapt their services to fit the cultural and economic contexts of each market — narrowing the gap between the value they intend to deliver and the value perceived by local consumers.
However, the trend today goes far beyond regional localization and into the realm of hyper-personalization — customization at the individual level. As societies grow more complex and interactions more diverse, individuals increasingly seek to express their unique tastes and identities, expecting the services they use to reflect those very traits — distinct, convenient, and deeply personal. In this new era, services are no longer about catering to customers by region; they must now understand and respond to each person’s context, emotions, and behavioral patterns.
This shift has been accelerated by rapid advancements in AI, data, and communication technologies. Companies are now able to go beyond traditional macro-level analyses of industries and consumers — they can leverage cutting-edge tools to collect and interpret vast streams of data in real time, ranging from sensitive personal information to behavioral insights.
Yet amid this progress, an important question arises: can today’s AI-driven services truly deliver perfectly hyper-personalized experiences to hundreds of millions of users? Or are they, paradoxically, undermining individuality and narrowing the spectrum of choice? The truth is, the centralized AI learning pipelines that dominate today still carry deep structural limitations at every stage — raising doubts about whether the hyper-personalized era we envision can truly emerge from the current wave of AI innovation.
This article explores how Gradient seeks to overcome these structural constraints through the development of an open intelligence platform. Gradient dissects the backend interactions required for agents’ inferences, then reconstructs and integrates them into a modular, decentralized architecture — aiming to build the foundational engine for scalable agent ecosystems across industries.
In many ways, it has become evident that today’s AI systems face structural limitations in delivering perfectly personalized services to everyone. Most simply, it is practically impossible to reflect each individual’s ever-changing and context-rich circumstances in real time. Human emotions, preferences, and behavioral patterns shift constantly, and between transmitting this information to a centralized server and feeding the output back to users, there are inevitable time lags and losses of fidelity. Consequently, modern AI can only offer what might be called “delayed personalization” — an approximation based on past data rather than a reflection of the present.
Beyond this, structural constraints exist across multiple dimensions — data, ethics, economics, and governance. As personalization deepens, AI inevitably requires access to increasingly sensitive information about users’ behaviors, locations, emotions, and even health conditions, which directly conflicts with privacy protection. Regulations such as GDPR and national privacy laws clearly define how deeply technology companies may understand individuals. Yet as long as the depth that technology demands exceeds what society permits, users will never experience truly complete personalization.
Even if regulations guarantee data sovereignty or users willingly provide their data, the inner workings of AI remain opaque. Most models function as black boxes with millions of interdependent parameters, leaving users unaware of which data or logic underlies a given output. This opacity fundamentally weakens trust. Moreover, models not only reproduce biases embedded within their complex training datasets but also often rely on data that itself stems from previously personalized interactions — thereby narrowing user choice and amplifying bias in what can be seen as the paradox of personalization.
From an economic standpoint, building fully personalized solutions is also inefficient. Segmenting users into smaller groups and operating dedicated models for each requires enormous computational and infrastructural resources. Under this burden, the AI industry has increasingly concentrated around a few large platforms, while the entry barrier for new researchers and companies continues to rise. Even existing services must compromise somewhere between “sufficient personalization” and “operational efficiency.”
Of course, the strengths of today’s centralized AI models — their efficiency and generality — remain clear. Their ability to integrate massive datasets and generate generalized solutions continues to hold immense value in terms of convenience and productivity. Accordingly, large AI providers are likely to continue proposing new solutions and expanding into diverse domains.
However, for AI to truly enhance quality through deeper personalization, to enable the rise of more creative and diversified models, and to open new frontiers of innovation across industries, a different approach is required — one that diverges from the current centralized paradigm. In other words, for AI to spread more organically throughout society and generate broader synergies, we must develop new forms of architecture and governance that can more finely capture individual contexts. This entails not just technological advancement but a redesign of the entire AI lifecycle — from data collection and learning to inferencing — in ways that are more transparent, trustworthy, and openly constructed.
How, then, can we redesign the traditional AI architecture to enable a world of truly “scalable AI”?
Scalable AI, at its core, hinges on three conditions. First, users must be able to selectively apply their own data to the model of their choice, within a verifiable and trustworthy network. Second, the model must have access to sufficient computational resources to train and run smoothly. Third, the communication pipeline that powers each agent must operate without relying on a single point of failure, ensuring that it can be hosted without bottlenecks or interruptions. In other words, the key lies in moving beyond capital- and infrastructure-dependent centralized systems toward an environment where anyone can build, control, and operate their own AI in a flexible, distributed manner.
The Gradient team found their answer in an approach that decomposes each function into protocols and frameworks optimized for distributed environments, and then recombines them into a single, coherent stack. By doing so, they aim to guarantee data sovereignty while decentralizing compute and communication layers—ultimately building a reliable, open AI intelligence engine that anyone can participate in, verify, and co-operate.
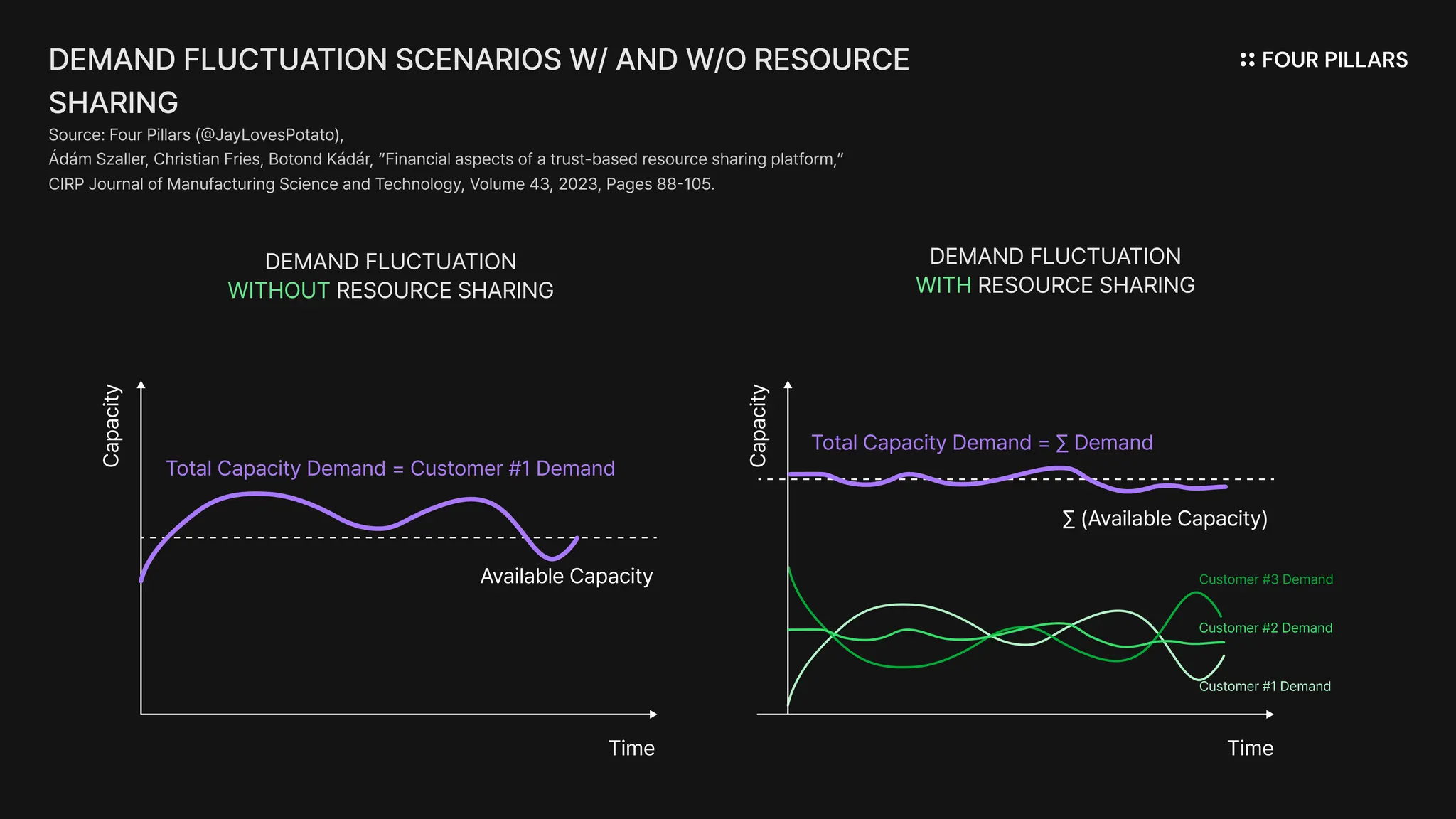
As we will examine later, a central design principle that has guided Gradient’s redesign of the decentralized stack is the ability to unify and orchestrate the vast pool of idle compute resources and heterogeneous computing environments distributed across the world. Compared to a traditional architecture in which all tasks are funneled through a centralized server, this approach offers several advantages.
Lower entry barriers: Participants can contribute to model training directly from their own environments, significantly reducing the barriers to participation.
Enhanced privacy and true data ownership: Because data remains in each participant’s local environment rather than being uploaded to a central server, privacy becomes easier to preserve, and users can build more refined, domain- or region-specific models that they fully own.
Greater reliability, efficiency and real-time performance: By coordinating work across a large pool of distributed idle resources, the system reduces the load on any single server, enabling a more stable, interruption-free communication context and improving real-time inference performance.
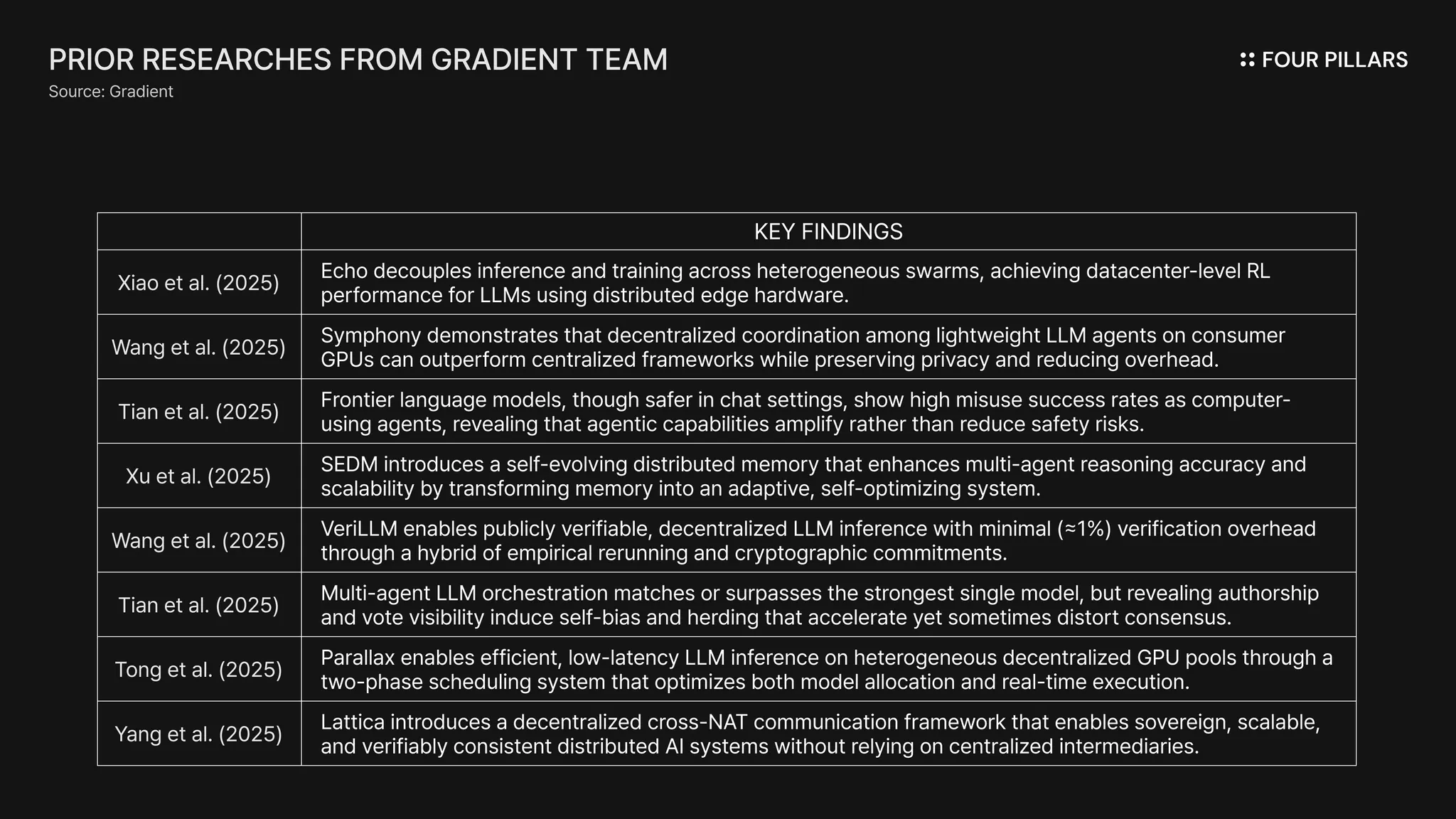
Composed of researchers from leading institutions such as UC Berkeley, Carnegie Mellon, and ETH Zurich, as well as alumni of Google, Apple, and ByteDance, the Gradient team has consistently explored the components of its envisioned decentralized infrastructure stack—and the value each layer can deliver—through eight academic papers and research outputs.
This approach of rebuilding the entire full-stack architecture enables Gradient to preserve the independence and scalability of each function while still allowing new models to be introduced and integrated flexibly. As a result, the overall pipeline achieves significantly higher operational efficiency and reliability.
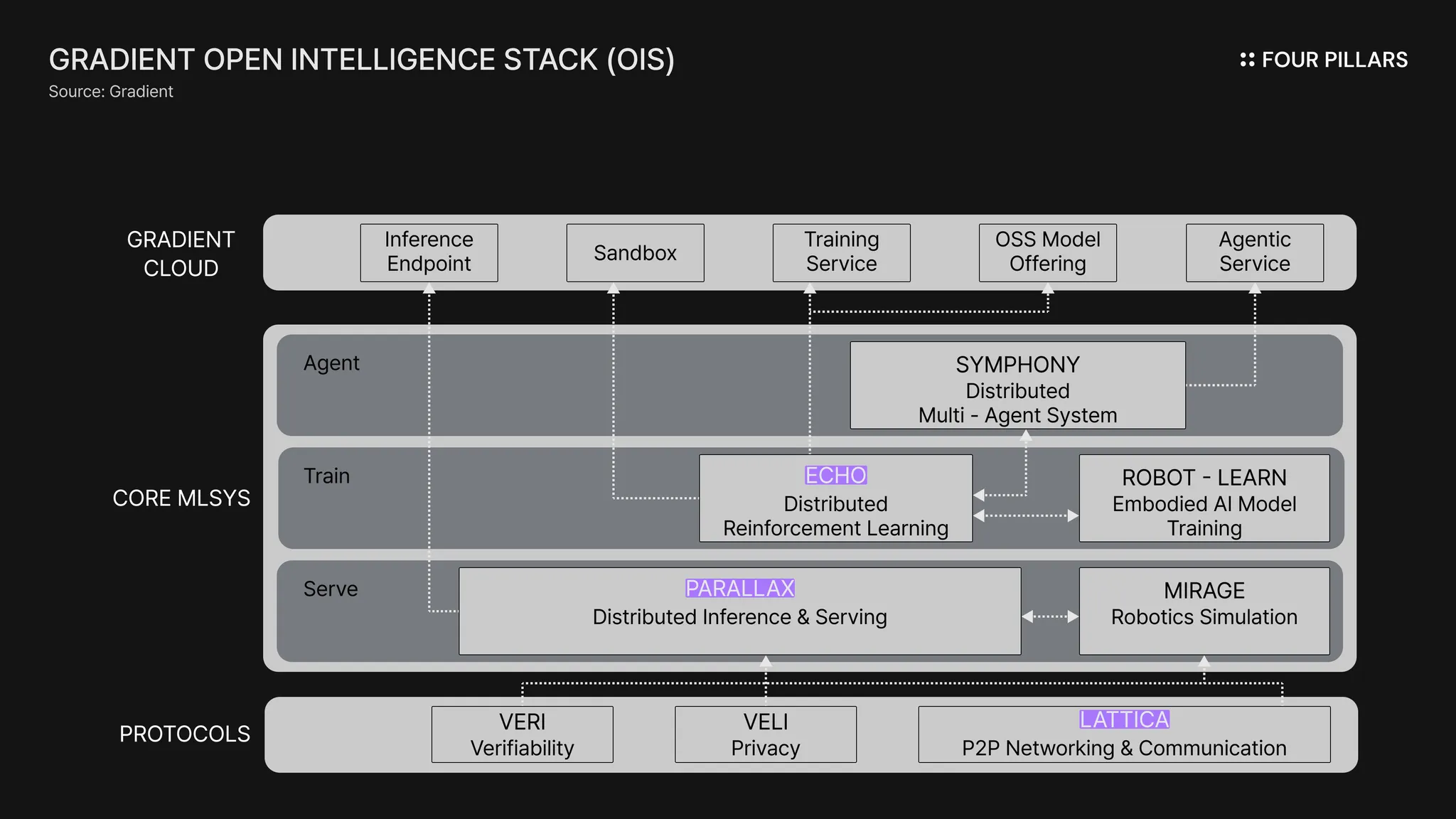
Based on their ongoing research, the Gradient team has so far unveiled four core infrastructure layers and services:
Lattica: a P2P communication protocol enabling seamless connectivity across diverse environments
Parallax: a distributed AI framework that links heterogeneous GPUs and CPUs to parallelize large-scale LLM inference
Echo: a training engine that supports reinforcement learning across users’ devices
Gradient Cloud: a platform providing inference endpoints for various AI models, built atop the three layers above
3.3.1 Lattica — The Communication & Coordination Layer for Open Intelligence
To begin with, Lattica can be understood as a foundational communication and coordination layer designed for an increasingly modular and purpose-driven AI environment. It allows a wide range of agents — each operating within its own context — to infer, collaborate, and interact seamlessly.
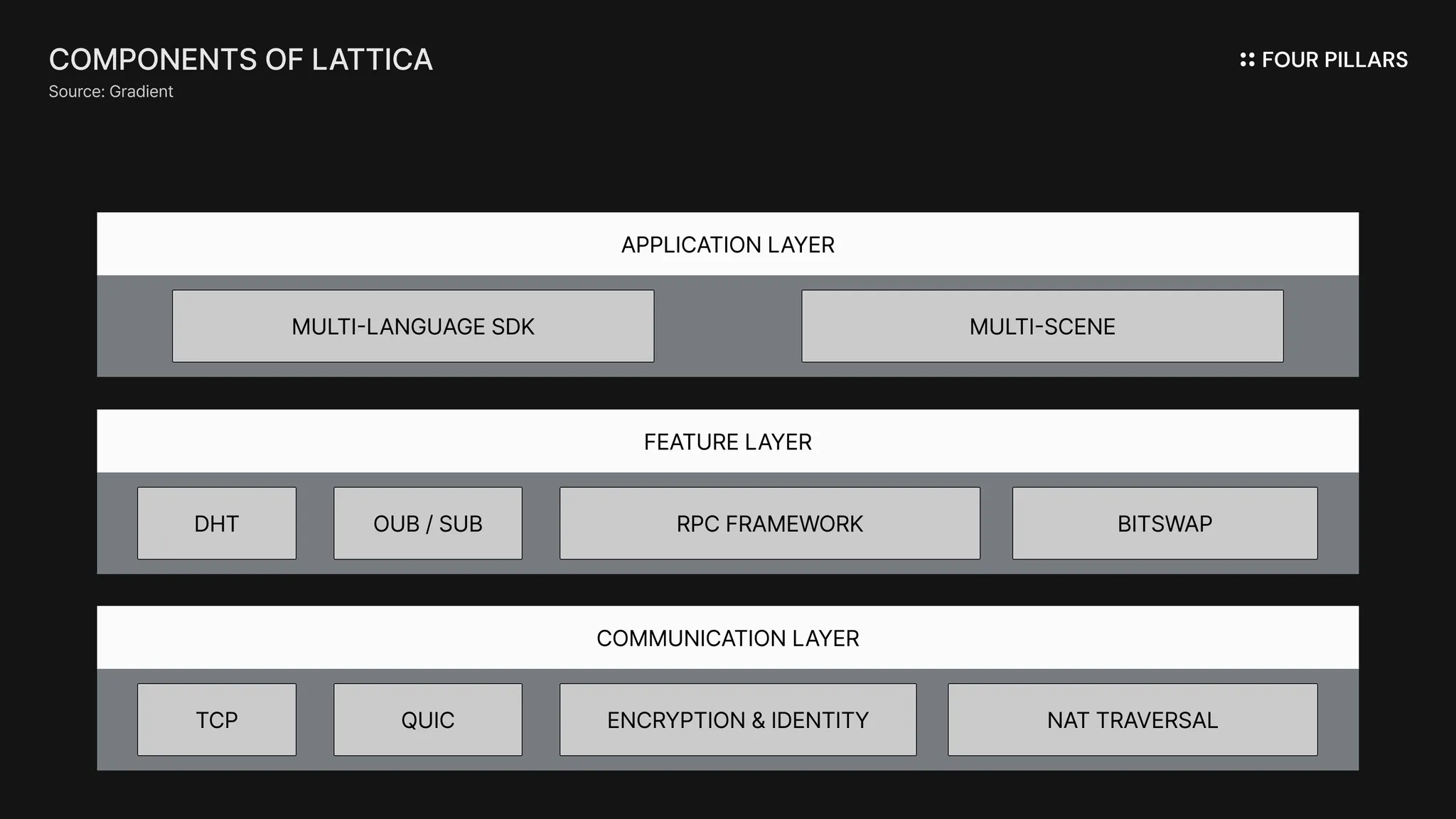
Lattica integrates and abstracts multiple layers — including the communication layer, protocol feature layer, and the application layer — into a unified stack. It combines NAT traversal*, Distributed Hash Table (DHT)**, Distributed Content Delivery Network (DCDN), and a libp2p stream-based RPC framework, thereby ensuring smooth, flexible connectivity between data centers, GPUs, browser nodes, and edge devices alike.
*NAT traversal is a technique that enables direct P2P connections between two devices located within separate internal networks that share a single public IP address via Network Address Translation (NAT), where direct communication is otherwise restricted for security reasons.
**A DHT is a decentralized system for storing and retrieving key-value pairs across multiple computer nodes without relying on a central server.
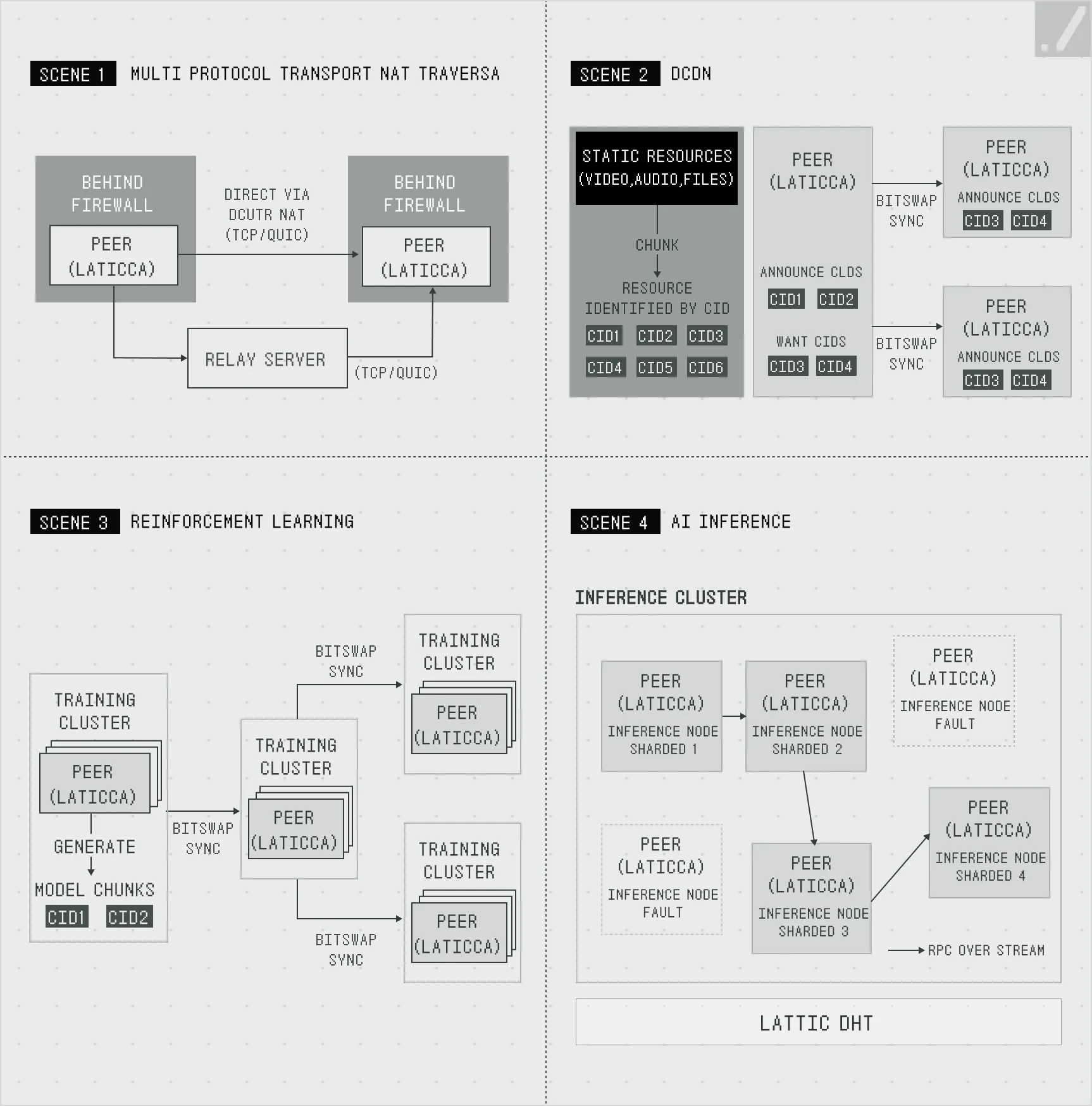
Source: Gradient | Four Scenarios for Decentralized AI
The communication orchestration process of Lattica can be summarized as follows:
model segments or data chunks are cached on individual (edge) nodes, whose validity is continuously monitored and propagated to an “availability map.” The orchestrator then scans this map to match optimal peers for data sharing, while Gradient’s learning engine feeds on this feedback loop — improving peer selection, load balancing, and routing strategies in real time. The result is a network that continually enhances its overall efficiency and stability.
Consequently, each node can exchange data via P2P connections — without centralized servers — and perform AI training and inference locally, regardless of environment. This enables users to conduct complex, intelligent computations such as collaborative reinforcement learning or large-scale distributed machine learning far more efficiently.
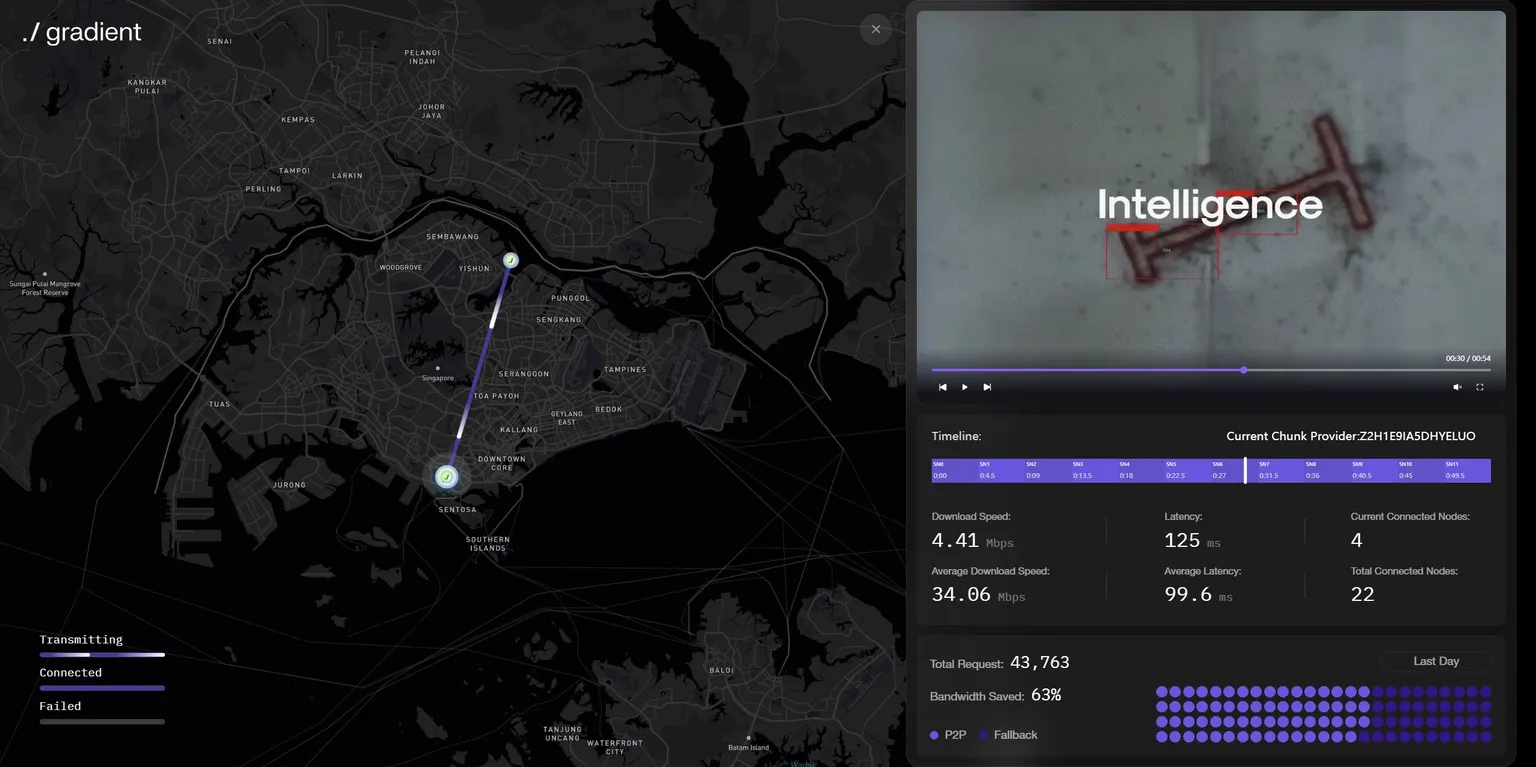
Source: https://explorer.gradient.network/
To demonstrate Lattica’s performance, the team has conducted several campaigns — most notably, a distributed video streaming experiment held in April using Chrome-extension-based Sentry nodes. In this test, more than 8 million Sentry nodes across 160+ regions worldwide participated. Videos were streamed successfully in real time — not from a centralized server, but directly from nearby Sentry nodes selected by the orchestrator via P2P transmission.
Looking ahead, Lattica aims to evolve beyond simple content transmission into a core communication substrate for decentralized AI — capable of orchestrating data flows in real time, from model-parameter routing to distributed inference and agent-to-agent communication.
3.3.2 Parallax — Sovereign AI OS Framework
If Lattica serves as the networking layer that unifies diverse communication environments and enables P2P connectivity between nodes, Parallax operates as the inference layer built on top of it. Leveraging Lattica, Parallax allows users to assemble fully sovereign, custom clusters through which AI model training and inference—at any scale—can be performed both efficiently and reliably.
Fundamentally, to maximize the utility, security, and stability of personalized AI services, the entity hosting the service must be able to directly control and host its own AI cluster. Yet in practice, this ideal often faces a dilemma. Running various LLMs on a single local machine quickly reaches hardware limits, while offloading larger models to cloud or global GPU pools means sacrificing control over the execution environment. Moreover, in such distributed settings, heterogeneous elements within the cluster—such as differences in bandwidth and dynamic GPU availability—often create operational constraints, making efficient scheduling highly challenging.
To address these issues, Parallax employs an architecture that integrates multiple foundational environments: the P2P communication network provided by Lattica, the GPU backend powered by SGLang, and the MAC backend driven by MLX LM. This unified setup enables seamless orchestration of inference nodes and cluster formation—whether in a local environment or, for large-scale models, across shared GPU pools—without downtime or dependency issues.
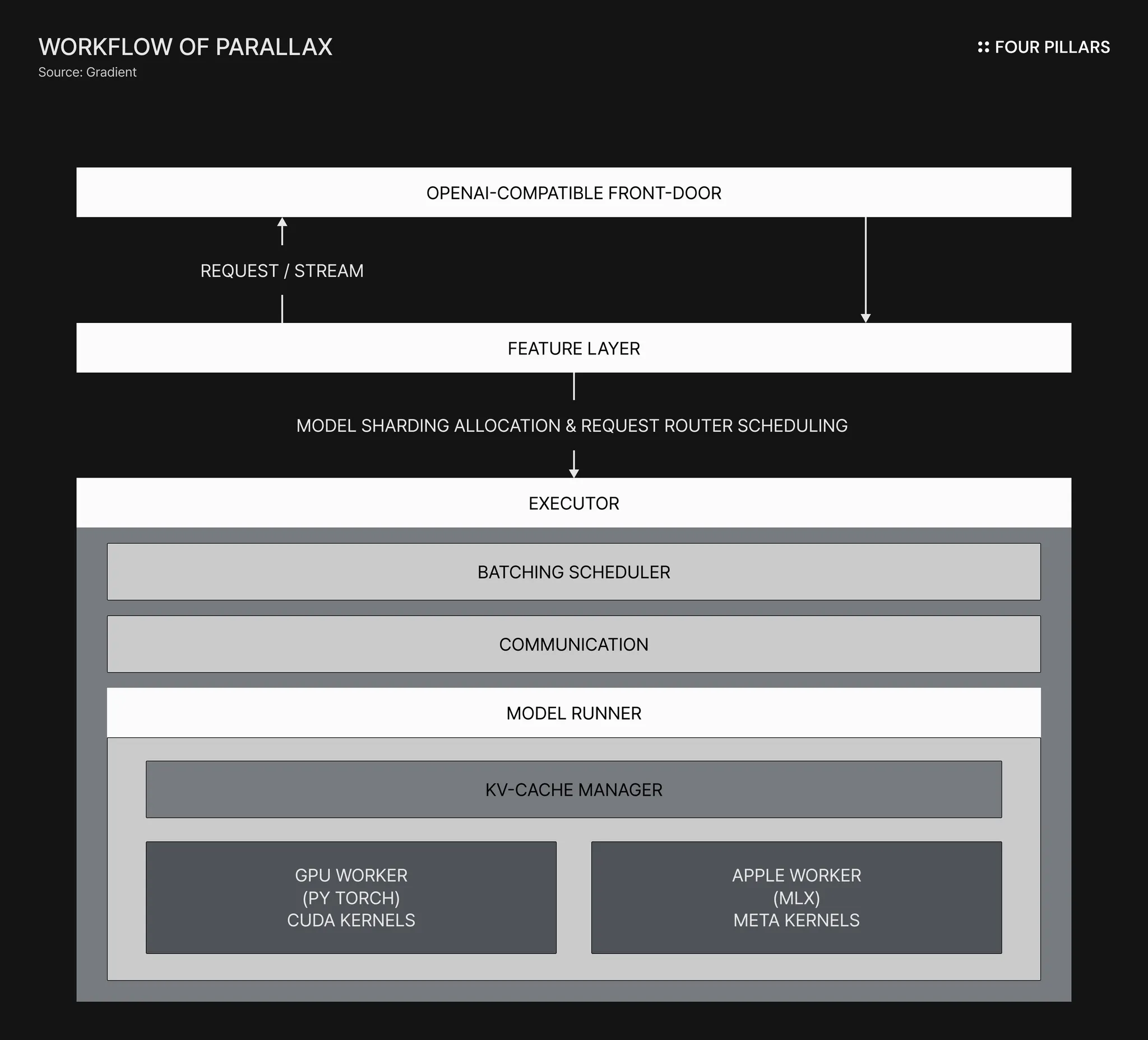
Built upon a swarm-based distributed architecture, Parallax orchestrates a set of heterogeneous machines within a cluster into a single adaptive mesh. It continuously explores optimal routes for each request and reorganizes inference clusters in real time according to load conditions.
Parallax’s scheduling and inference operations span three core layers: Runtime, Communication, and Worker.
Scheduling
Parallax shards models into consecutive layers, then uses Dynamic Programming (DP) and Water-Filling algorithms to identify and allocate the optimal hosts (e.g., laptops, GPUs) within the swarm—taking into account availability, compute performance, and latency. Throughout this process, it minimizes pipeline depth to reduce delays, increases replicas where necessary to boost throughput, and maintains balance so that faster devices are not bottlenecked by slower ones.
Backend & Communication
Within its unified backend layer, heterogeneous workers—from NVIDIA GPUs to Apple Silicon—execute inference in ways optimized for their individual hardware. All nodes function as one coordinated service under orchestration. Each request is dynamically profiled by device performance and RTT (Round Trip Time), then automatically routed through the most efficient path—be it a single host, local network, or public internet. Because Parallax streams hidden states rather than transferring complete datasets, all intermediate data and inference results remain secure and confidential while sequentially traversing each model layer.
As a result, Parallax delivers fault-tolerant and consistent inference performance across highly distributed and heterogeneous environments. It currently supports more than 40 open models, ranging from 600 million (0.6B) parameters to trillion-scale Mixture-of-Experts (MoE) architectures.*
Source: Gradient Chatbot | **A demo version of distributed inference powered by Parallax is currently available
*Leading MoE and GLM models, as well as open-source providers such as MiniMax M2, Kimi K2, Z.ai, LMSYS’s SGLang, and Alibaba’s Qwen, have all been integrated with Parallax.
3.3.3 Echo - A Distributed Reinforcement Learning Layer Optimized for Diverse Devices
AI learning can largely be divided into two categories. The first is pre-training, which involves observing human behaviors or datasets and imitating them (e.g., imitation learning). The second is post-training, which relies on trial and error—repeatedly performing a given scenario, then rewarding or penalizing the model based on outcomes (e.g., reinforcement learning (RL), knowledge distillation, and transfer learning). Pre-training excels at understanding human patterns and processing large-scale data, which is why it has played a pivotal role in advancing base models such as LLMs. However, to enable more complex and diverse applications, future agents must go beyond simply reproducing correct answers or assisting decisions; they must be capable of autonomous, solution-oriented inferencing to independently solve problems.
That said, modern post-training architectures still face several limitations. Most models perform trajectory sampling and policy optimization* within the same GPU cluster. This setup leads to multiple issues: (1) rollouts** occur within a single simulator cluster, limiting data diversity; (2) models risk overfitting to specific environments; (3) if the time gap between the learning policy and the policy used for rollouts grows too large, gradient updates become unstable; and (4) since trajectories are collected within the same cluster, even when policies are updated, models may continue to train on outdated data—resulting in delayed policy reflection. To mitigate these problems, recent RL approaches have begun separating rollout clusters from training clusters, introducing buffer-based designs that allow both clusters to operate independently.
Gradient’s Echo is a layer optimized to extend this architecture across idle devices around the world. It aims to enhance training and inference dynamics so that agents can model more efficiently. Echo separates the training and inference processes into each swarm, enabling each to function efficiently based on its designated role. Through synchronized protocols, devices across the globe are interconnected, forming a vast rollout worker network that operates stably and organically.
*Policy; the strategy or rule determining which action an agent should take in a given state
**Rollout; the process of evaluating an agent’s performance by executing a policy over a defined period of time
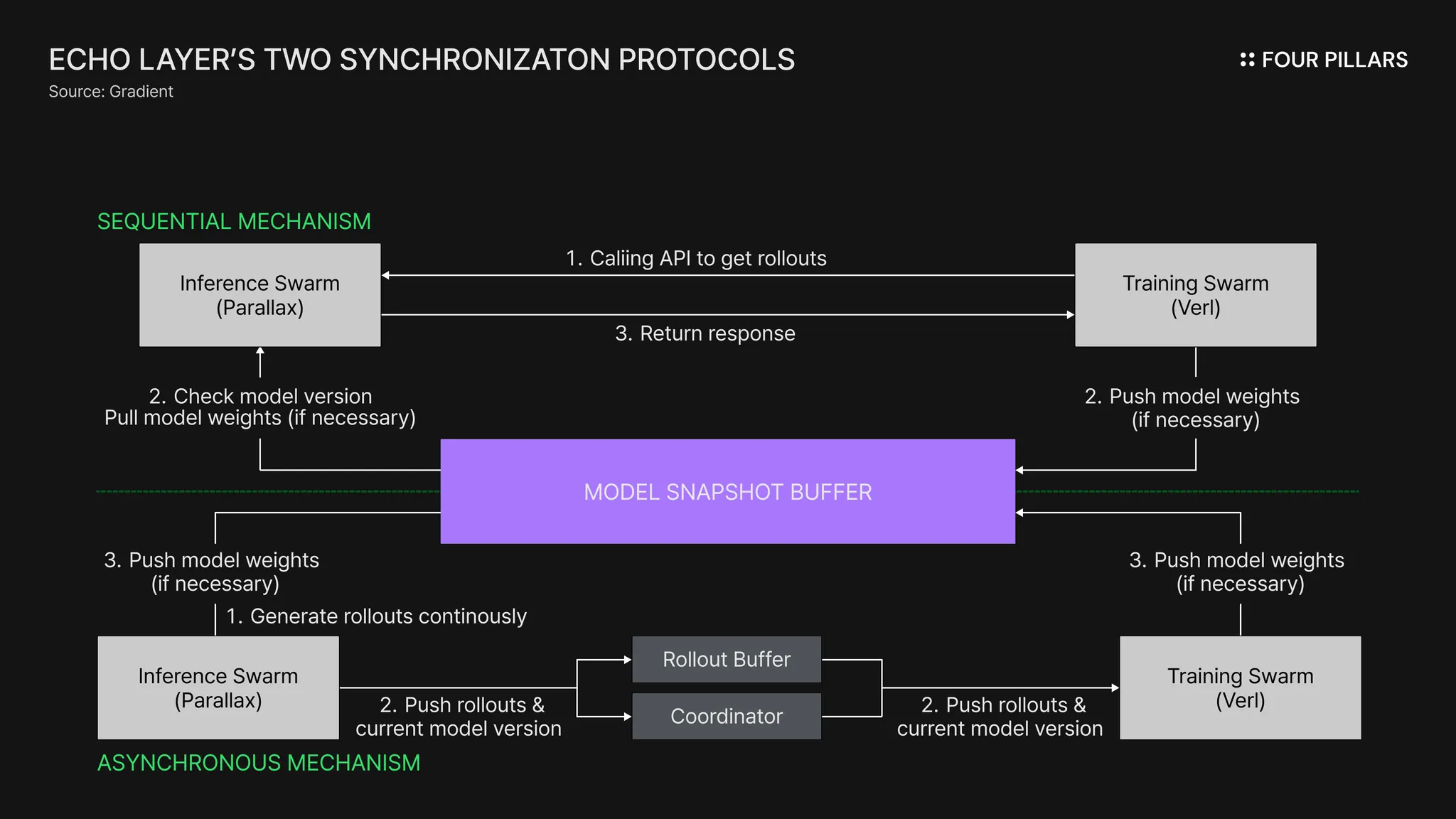
First of all, the Inference Swarm leverages the previously mentioned Parallax framework, which allows various hardware workers—such as NVIDIA GPUs and Apple Silicon—to perform optimized rollouts based on their respective performance characteristics. Meanwhile, the Training Swarm extends the open-source Verl stack* to optimize policies within data-center–grade GPU environments such as A100 and H100 systems.
However, in such a dual-architecture design, there naturally arises a trade-off between the freshness of rollouts and the synchronization of policy optimization. In other words, the challenge lies in balancing bias, accuracy, and computational efficiency within inference results. To address this, the Echo layer introduces two synchronization mechanisms centered around a model-snapshot buffer, allowing each mechanism to be applied flexibly according to purpose.
For agents that prioritize precision and low bias—requiring finely controlled policy consistency—Echo proposes a Sequential mechanism. This method resembles the conventional centralized approach: the Training Swarm serves as the core, making on-demand API calls to request trajectories from the Inference Swarm. Upon receiving the request, each Inference Swarm checks its local weight version against the latest model snapshot; if outdated, it updates accordingly before executing rollouts and streaming the resulting batches back to the caller.
In contrast, the Asynchronous mechanism continuously streams rollout samples to a Rollout Buffer, tagging each with a version identifier. The Training Swarm, at predefined intervals, updates the model-snapshot buffer with new weights in mini-batch form. Here, training and inference occur concurrently, minimizing end-to-end latency and maximizing training efficiency.
In summary, Echo’s modular architecture significantly improves upon traditional reinforcement learning approaches by (1) maximizing resource utilization, (2) enhancing the deployment flexibility of inference pipelines, and (3) decoupling hardware diversity from model improvement—thereby alleviating bottlenecks and reducing performance degradation caused by single points of failure.
*Verl is an open-source reinforcement learning framework developed by ByteDance’s Seed Team, supporting algorithms such as PPO and GRPO.
Source: Gradient
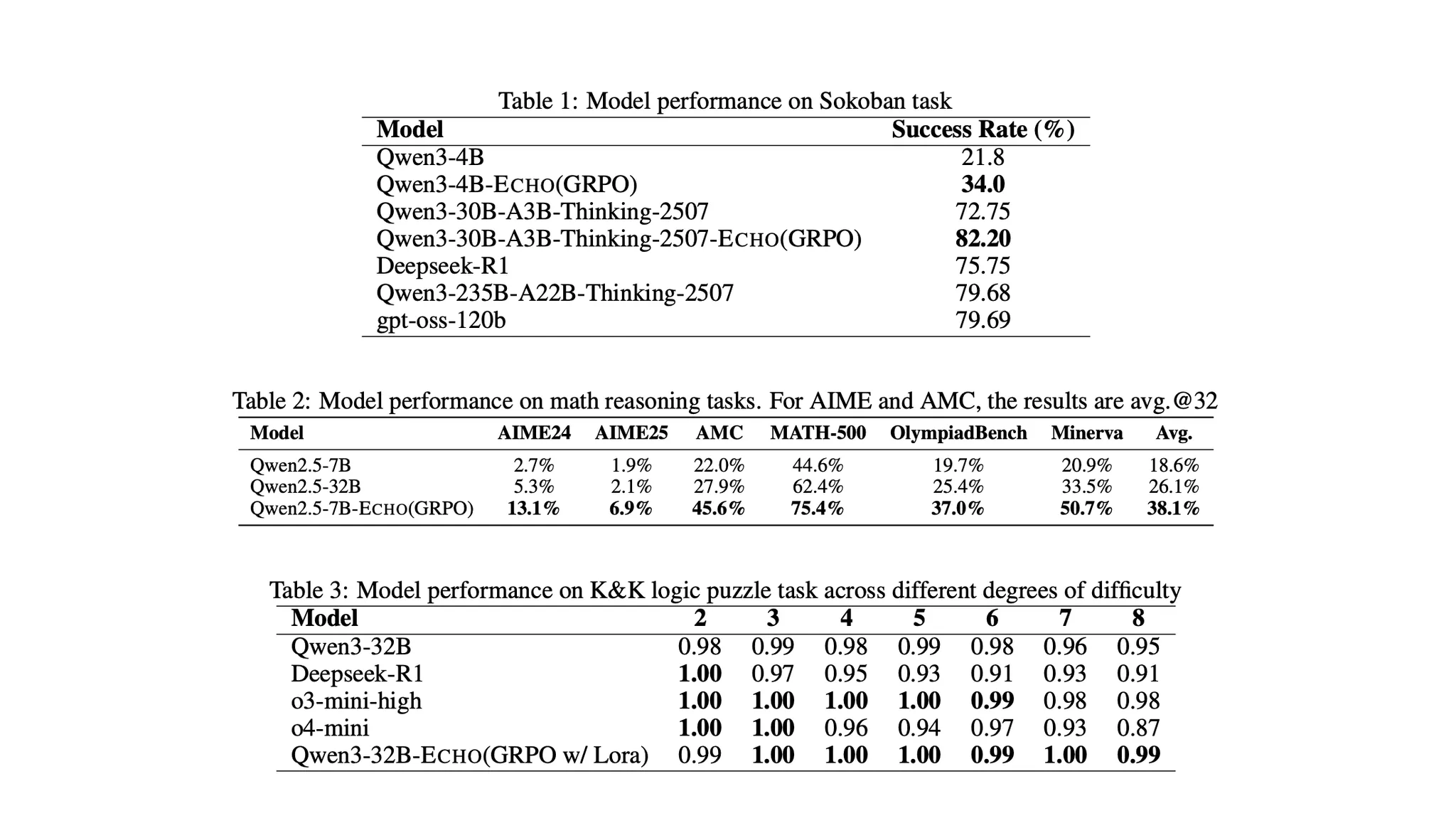
According to Gradient’s paper, the proposed methodology was benchmarked against conventional co-located models. The evaluation used four Qwen-series base models: Qwen3-4B, Qwen2.5-7B, Qwen3-32B, and Qwen3-30B-A3B-Thinking-2507.
VERL Framework (Base)
Single machine equipped with 8 × A100 80GB GPUs
Echo Framework
Inference Swarm
Distributed network based on Parallax, consisting of six nodes (3 × RTX 5090 and 3 × Mac M4 Pro)
Training Swarm
Single machine with 4 × A100 GPUs
As a result, the Echo layer successfully distributed trajectory generation across general-purpose edge hardware while achieving comparable convergence speed and final reward to the co-located baseline*.
*Currently, four test models are publicly available via the Hugging Face collection.
3.3.4 Gradient Cloud — The Enterprise Solution That Unifies It All
Source: Gradient Cloud
The Gradient Cloud serves as an all-in-one AI development station built atop the three decentralized stacks introduced earlier—Lattica, Parallax, and Echo. It offers an interactive playground where users can flexibly adjust inference endpoints and parameters for leading open-source models, and deploy them with a single click, all powered by a globally distributed hardware network.
According to its roadmap, Gradient aims to continually advance its fully decentralized stack—encompassing the three foundational layers mentioned above—to achieve performance and scalability that transcend the limits of centralized architectures across diverse industries. At the same time, through products like Gradient Cloud, it seeks to consolidate these technologies, facilitate real-world collaboration among multiple agents, and ultimately build an open ecosystem where the value generated within the Gradient network flows back to all participants, allowing them to share in the collective benefits.
Today, AI is rapidly evolving beyond the realms of simple information retrieval or text generation, moving toward solving complex problems and performing autonomous tasks in specialized domains such as robotics, virtual world, industrial automation, and more. In response, both users and tech companies are no longer content with merely leveraging existing AI tools — instead, they are increasingly building and combining purpose-built AI agents optimized for their own environments, exploring more sophisticated and intelligent ways to integrate them into their workflows.
However, for AI technologies to truly expand into deeper and more diverse sectors — opening up countless new use cases across industries — structural and governance-level openness is essential. Anyone should be able to safely utilize sensitive data, freely build models, and access the computational resources they need. At the same time, every step in this process must ensure procedural integrity that is transparent and verifiable, fostering genuine democratization of participation. Only when such trust infrastructure is established can the flywheel of an open-intelligence ecosystem begin to spin sustainably.
Within this context, Gradient’s Open Intelligence Stack (OIS) offers a scalable infrastructure capable of building and hosting inference-driven agent models tailored to far more diverse contexts than any centralized system could allow. Furthermore, by realizing this infrastructure as a platform, OIS lays the groundwork for decentralized agents to connect and interact across various industries and environments — positioning itself with strong potential to serve as the backbone of a truly distributed intelligence network.
However, several unobserved risks still remain within Gradient. The first is the issue of value alignment among its diverse participants.
Gradient’s incentive-based decentralized structure—originally pioneered by blockchain—fundamentally operates on the principle of attracting a broad and voluntary set of contributors by rewarding them for performing specific tasks. In other words, when incentives exist, supply naturally emerges in response; and through the interplay between supply and demand, coupled with the incentive mechanism, a cyclical equilibrium of value flow is established. Yet for this idealized market-adjustment mechanism to truly function, each contributor’s share of value creation must be reasonably calculated, and the corresponding rewards must reach a collectively accepted balance.
That said, Gradient integrates the AI ecosystem’s learning, inference, data, and computation stages into a modular architecture—pursuing an open intelligence network accessible to anyone. This, in turn, means that each layer hosts a wide array of participant groups. The more diverse the participants, the greater the complexity of aligning their economic incentives becomes.
Moreover, Gradient is highly likely to adopt a stake-based governance model to ensure decentralized operation. However, even when consensus is achieved among participants, if the verification criteria or reward systems for each module keep changing, the trust metric across layers may diverge and overall stability could deteriorate. When incentives are poorly defined or reward systems are biased toward certain entities, there is a risk that specific layers may wield disproportionate influence or distort overall efficiency.
Therefore, for Gradient to evolve into a truly open intelligence network, it must design a finely tuned and resilient incentive system—one that enables the economic motivations of each module to function complementarily, while continuously driving long-term improvements in quality.
Another non-negligible risk for Gradient lies in the increasingly competitive landscape it faces. The market is already crowded with established Web2 players such as OpenAI, Anthropic, Google, and Meta—companies that, despite structural limitations, continue to secure absolute dominance in model performance and parameter optimization through massive capital and data advantages. At the same time, Web3-native projects like Gensyn, Bittensor, IO.NET, and Aethir are rapidly expanding their ecosystems by decentralizing specific layers of the AI stack—data, compute, and model training respectively. Of course Gradient occupies a distinctive position as an integrated intelligence engine within this landscape, yet paradoxically, this very integration implies a structural limitation: it is difficult to achieve full economies of scale in any single vertical.
To strengthen its position in such a fiercely competitive arena, Gradient must move beyond simply advocating decentralization. It needs to create a new kind of network effect that fuses interoperability between modules with market efficiency. In other words, while projects like IO.NET or Aethir focus on connecting isolated idle resources, Gradient should enhance its role as an intelligent orchestration layer—one capable of seamlessly integrating and coordinating these resources into a unified inference pipeline. When this sort of direction is firmly established, Gradient can evolve into a hybrid intelligence infrastructure that absorbs the capital efficiency of Web2 and the distributed openness of Web3.
Dive into 'Narratives' that will be important in the next year